A Kairosfocus Briefing
Note:
GEM 06:03:17; this adj. 06:12:16 - 17 to 08:09:28 further adj.to 09:01:04 - 12:06:01, &12: 09:29 Ver 1.7.2c
https://www.angelfire.com/pro/kairosfocus/resources/Info_design_and_science.htm
On
Information, Design, Science, Creation & Evolutionary
Materialism:
Engaging the
Current controversies over the role of information and design in
understanding the origins of the Cosmos, Life, Biodiversity, Mind, Man
and Morality
Is
it possible for any man to behold these things, and yet imagine that
certain solid and individual bodies move by their natural force and
gravitation, and that a world so beautifully adorned was made by their
fortuitous concourse? He who believes this may as well
believe that if a great quantity of the one-and-twenty letters,
composed either of gold or any other matter, were thrown upon the
ground, they would fall into such order as legibly to form the Annals
of Ennius. I doubt whether fortune could
make a single verse of them. How, therefore, can these
people assert that the world was made by the fortuitous concourse of
atoms, which have no color, no quality—which the Greeks call
[poiotes], no sense? [Cicero, THE
NATURE OF THE GODS BK II Ch XXXVII, C1 BC, as trans Yonge
(Harper & Bros., 1877), pp. 289 - 90.]
SYNOPSIS: The raging controversy
over inference to design too often puts out more heat and smoke than
light. However, as Cicero pointed out in the cite just above, the
underlying issues are of such great importance, that all educated
people need to think about them carefully. Accordingly, in the below we
shall examine a cluster of key cases, starting with the often
overlooked but crucial point that in
communication systems, we first start with an apparent
message, then ask how much information is in it. This directly
leads to the question first posed by
Cicero, as to what is the probability that the received
apparent message was actually sent, or is it "noise that got lucky"?
The solution to this challenge is in fact an implicit inference to
design, and it is resolved by essentially addressing the functionality
and complexity of what was received, relative to what it is credible --
as opposed to logically possible -- that noise could do. That is, the
design inference has long since been deeply embedded in scientific
thought, once we have had to address the issue: what is information?
Then, we look at several key cases: informational
macromolecules such as DNA, the related origins of observed biodiversity,
and cosmological finetuning.
Thereafter, the issue is broadened to look at the
God of the gaps challenge. Finally, a technical
note on thermodynamics and several other technical or detail appendices are presented: (p) a critical look at the Dover/ Kitzmiller case (including a note on Plato on chance, necessity and agency in The Laws, Bk X), (q) the roots of the complex specified information concept, (r) more details on chance, necessity and agency, (s) Newton in Principia as a key scientific founding father and design thinker, (t) Fisherian vs Bayesian statistical inference in light of the Caputo case, and (u) the issue of the origin and nature of mind. Cf. Notice
below. (NB: For FAQs
and primers go here. This Y-zine also seems to be worth a browse.)
CONTENTS:
INTRODUCTION
--> ID in a nutshell
-->
ID FAQs and Primers
--> A basic survey of the ID
issue and its significance
--> On research-level ID
topics
A] The
Core Question: Information, Messages and Intelligence
-->
Defining "Intelligent
Design"
--> Three
causal factors: chance,
necessity, agency
--> The design inference explanatory filter
--> Defining
"Intelligence"
--> On "Lucky Noise"
--> Defining "Information"
--> Shannon Info (AKA Informational Entropy) and the link to thermodynamic entropy
--> Defining "Functionally
Specific, Complex Information" [FSCI]
--> Metrics for FSCI (and CSI)
--> Orgel vs Shapiro on getting to origin of life
B] Case
I: DNA as an Informational Macromolecule
--> Dembski's
Universal Probability Bound
--> "Definitionitis" vs. the
case by case recognition of FSCI
--> Of monkeys and keyboards,
updated
--> Implications of the scale of the configuration space of the genome
--> Optimality and structured codon assignments in the DNA code
--> Objections and responses
C] Case
II: Macroevolution and the Diversity of Life
--> the observed fossil record pattern: sudden appearance, stasis, disappearance
--> Defining
"Irreducible Complexity"
--> The
Bacterial Flagellum
--> Macro-
vs. Micro- Evolution
--> Natural selection as a probabilistic culler
vs. an innovator (& the gambler's ruin challenge)
D] Case
III: The evidently Fine-tuned Cosmos
--> Leslie
on convergent fine-tuning
--> On "multiverses"
--> Objections and responses
E] Broadening
the Issue: Persistent "Gaps," Man, Nature, Science and Worldviews
--> On
"Defining" Science
--> The US NSTA's attempted naturalistic redefinition of the nature of science, July 2000
--> Lewontin's materialism agenda in the name of "Science"
--> The NAS-NSTA intervention on science education in Kansas
--> On marking the key distinction between origins and operations sciences
CONCLUSION
APPENDIX I: On
Thermodynamics, Information and Design
--> On the consequences of injecting raw energy into an open system
--> On energy conversion devices and their origin, in light of having FSCI
-->
Brillouin's Negentropy view of
the link between Information and Entropy
-->
A Thought Experiment using "nanobots"
building "a flyable micro-jet" to illustrate the issues
involved in Origin of Life (OOL) and neo-Darwinian-style Macroevolution
in light of thermodynamics
APPENDIX 2: On
Censorship and Manipulative Indoctrination in science education and in
the court-room: the Kitzmiller/Dover Case
-->
Plato on chance, necessity and
agency in The Laws,
Book X
APPENDIX
3: On the source, coherence and
significance of the concept, Complex, Specified Information (CSI)
--> Thaxton,
Bradley and Olsen on the source of CSI
--> Orgel -- the first known
documented use of the term; in
1973
--> Wicken's "wiring diagram" functional organisation and the roots of the term Functionally Specific, Complex Information [FSCI]
--> Trevors and Abel on sequence complexity: OSC,
RSC, FSC
--> Yockey and
Wickens and the source of the term used in this note,
Functionally Specified, Complex Information [FSCI]
--> Of the
creation of tropical cyclones and the origin of snowflakes
--> Dembski's
work and the identification of
the edge of chance
APPENDIX 4: Of chance, necessity, agency, the natural vs. the supernatural vs. the artificial, Kant and Fisher vs Bayes:
APPENDIX 5: Newton's thoughts on the designer of
"[t]his most
beautiful system of the sun, planets, and comets . . . "
in his General Scholium to the Principia
APPENDIX 6: Fisher,
Bayes, Caputo and Dembski
APPENDIX 7: Of the Weasel "cumulative selection" program and begging the question of FSCI, c. 1986
APPENDIX 8: Of the inference to design and the origin
and nature of mind [and thence, of morals]
--> The (modified) Welcome to Wales thought experiment --> Key cites: Liebnitz's mill, Taylor on Wales, Reppert on Lewis' AFR, Shapiro's blind forces golf game, Plantinga on natural selection vs the accuracy of beliefs, Crick's astonishing hypothesis & Philip Johnson's rejoinder, Hofstadter on Godel, Atmanspacher on Quantum theory, randomness and free will, Calef's corrective on mind's influence, the Penrose- Hameroff graviton suggestion, the Derek Smith two-tier controller cybernetic loop model--> Evolutionary materialism and self-referential incoherence
--> Evolutionary materialism and the is-ought gap
--> Implications of the reality of evil etc
--> On the hard problem of consciousness
INTRODUCTION:
The raging controversy over inference to design, sadly, too often puts
out more heat and blinding, noxious smoke than light.
(Worse, some of the attacks to
the man and to strawman
misrepresentations of the actual
technical case for design [and even of the
basic definition of design theory] that have now become a routine distracting rhetorical
resort and public
relations spin tactic of too many of the defenders of the
evolutionary materialist paradigm, show that this resort to
poisoning the atmosphere of the discussion is in some quarters
quite deliberately intended
to rhetorically blunt the otherwise plainly telling force of
the mounting pile of evidence and issues that make the inference to
design a very live contender indeed.)
Be that as it may, thanks to the transforming
impacts of the ongoing Information Technology revolution, information has now increasingly
joined matter, energy, space and time as another recognised fundamental
constituent of the cosmos as we experience it. For, it has become
increasingly clear over the past sixty years or so, that information is deeply embedded
in key dimensions of existence. This holds from the evidently fine-tuned complex organisation
of the physics of the cosmos as we observe it, to the intricate nanotechnology of the
molecular machinery of life [cf. also J Shapiro here!
(NB on AI here,
and on Strong vs Weak AI here
and here
. . . ! )], through the
informational requisites of body-plan level biodiversity, on
to the origin of mannishness
as we experience it, including mind and reasoning, as well as
conscience and morals. So, we plainly must frankly and fairly address
the question of design as a proposed best current
explanation -- and as a paradigm framework for transforming
the praxis of science and thought in general, not just technology --
as, it has profound implications for how we see ourselves in our world,
indeed (as the intensity of the rhetorical reaction noted just now
indicates) it powerfully challenges the dominant evolutionary
materialism that still prevails among the West's secularised
educated elites.
In a nutshell:
The
scientific study of origins helps us probe the roots of our existence.
Unfortunately, some have recently undercut this search by trying to re-define science as a search for “natural causes,” which imposes materialistic conclusions before the facts can speak. However, through objectively studying signs of intelligence -- the intelligent design approach -- we can allow the evidence to speak for itself. For, reliably, functionally specified complex information comes from intelligence. Thus, ID helps us restore balance
to science and to many other aspects of our culture that are shaped by
our views on our origins. [HT: StephenB, a long-standing commenter
at UD. (NB: For basic FAQs and primers on ID-related
topics and issues, kindly go to the IDEA Center, here.
For a layman's level
introduction to the basic design issue go here,
and for a similar layman's level discussion of why it is an important
challenge to the assumptions, assertions and agendas of our secularised
intellectual culture, go here.
For a discussion of
ID-related research and associated topics, go to the Research-ID
Wiki here.)]
However, it is obviously also necessary for us to now pause
and survey in more details on the key facts, concepts and issues, drawing out implications
as we seek to infer the best explanation for the information-rich world
in which we live. That is the task of this briefing.
A]
The Core Question: Information, Messages and Intelligence
Since the end of the 1930's, five key trends have
emerged, converged and become critical in the worlds of science and
technology:
- Information Technology and computers, starting with
the Atanasoff-Berry
Computer [ABC], and other pioneering computers in
the early 1940's;
- Communication technology and its underpinnings in
information
theory, starting with Shannon's
breakthrough analysis in 1948;
- The partial elucidation of the DNA code as
the information basis of life at molecular level, since the 1950s, as,
say Thaxton reports by citing Sir Francis Crick's March
19, 1953 remarks to
his son: "Now we believe that the DNA is a code. That is, the order of
bases (the letters) makes one gene different from another gene (just as
one page of print is different from another)";
- The "triumph" of the
Miller-Urey spark-in-gas experiment, also in 1953,
which produced several amino acids, the basic building blocks of
proteins; but, also, we have seen a persistent failure thereafter to
credibly and robustly account for the origin of life through so-called chemical
evolution across subsequent decades ; and,
- The discovery of the intricate
finetuning
of the parameters in the observed cosmos for life
as we know and experience it -- strange as it may seem: again, starting
in 1953.
The common issue in all of these lies in the
implications of the concepts, communication and information -- i.e. the
substance that is communicated. Thus, we should
now focus on the basic communication system model, as that sets the
context for further discussion:
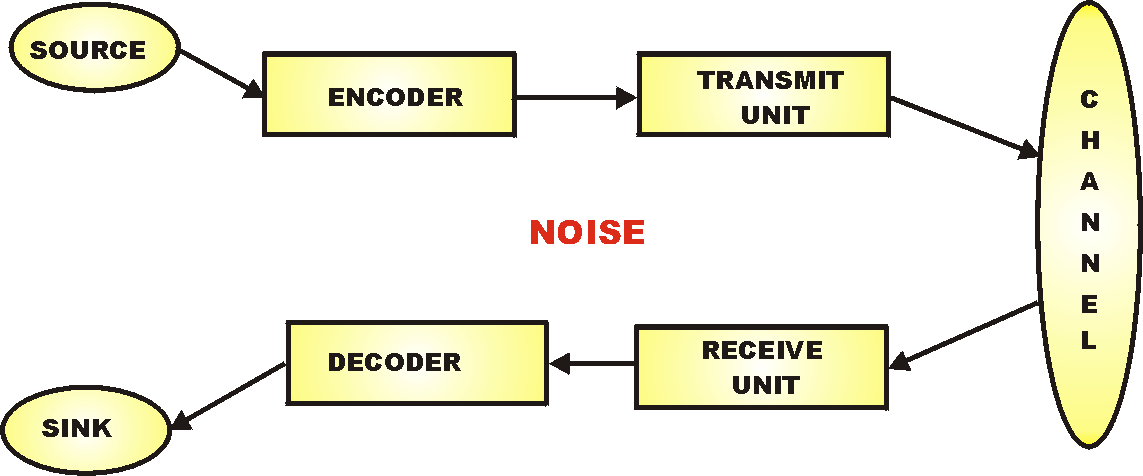 |
Fig. A.1: A Model of the "Typical" Communication System
|
In this model, information-bearing messages
flow from a source to a sink, by being: (1) encoded, (2) transmitted
through a channel as a signal, (3) received, and (4) decoded. At each
corresponding stage: source/sink encoding/decoding,
transmitting/receiving, there is in effect a mutually agreed standard,
a so-called protocol. [For instance, HTTP
-- hypertext
transfer protocol --
is a major protocol for the Internet. This is why many web page
addresses begin: "http://www . . ."]
However, as the diagram hints at, at each stage noise
affects the process, so that under certain conditions, detecting and
distinguishing the signal from the noise
becomes a challenge. Indeed, since noise is due to a random fluctuating
value of various physical quantities [due in turn to the random
behaviour of particles at molecular levels], the
detection of a message and accepting it as a legitimate message rather
than noise that got lucky, is a question of inference to design.
In short, inescapably, the design inference issue is foundational to
communication science and information theory.
Let us note, too, that similar empirically
testable inferences to intelligent agency are a commonplace
in forensic science, archaeology, pharmacology and a great many fields
of pure and applied science. Climatology is an interesting case: the
debate over anthropogenic climate change is about unintended
consequences of the actions of intelligent agents.
Thus, Dembski's
definition of design theory as a scientific project through
pointed question and answer is apt:
intelligent design begins with a
seemingly innocuous question: Can objects, even if nothing is known
about how they arose, exhibit features that reliably signal the action
of an intelligent cause? . . . Proponents of intelligent design, known
as design theorists, purport to study such signs formally, rigorously,
and scientifically. Intelligent design may therefore
be defined as the science that studies signs of intelligence.
[BTW, it is sad but necessary to highlight what should be obvious:
namely, that it is only common
academic courtesy (cf. here,
here,
here,
here,
here
and here!)
to use the historically
justified definition of a discipline that is generally
accepted by its principal proponents.]
So, having now highlighted what is at stake, we
next clarify two key underlying questions. Namely, what is
"information"? Then, why is it seen as a
characteristic sign of intelligence at work?
First, let
us identify what intelligence
is. This is fairly easy: for, we are familiar with it from the
characteristic behaviour exhibited by certain known intelligent agents
-- ourselves.
Specifically, as we know from experience and reflection,
such agents take actions and devise and implement strategies that
creatively address and solve problems they encounter; a functional
pattern that does not depend at all on the identity of the particular
agents. In short, intelligence is as intelligence does. So, if we see evident active, intentional,
creative, innovative and adaptive [as opposed to merely fixed
instinctual] problem-solving behaviour similar to that of
known intelligent agents, we are justified in attaching the label:
intelligence.
[Note how this definition by functional description
is not artificially confined to HUMAN intelligent agents: it would
apply to computers,
robots, the alleged alien residents of Area 51, Vulcans, Klingons or
Kzinti, or demons or gods, or God.] But also, in so solving their
problems, intelligent agents may leave behind empirically evident signs
of their activity; and -- as say archaeologists and detectives know -- functionally
specific, complex information [FSCI]
that would otherwise be utterly improbable, is one of these signs.
Such preliminary points should also immediately lay to rest the assertion in some quarters that inference
to design is somehow necessarily "unscientific" -- as, such is
said to always and inevitably be about improperly
injecting "the supernatural" into scientific discourse.
(We hardly need to detain ourselves here with the associated claim
that intelligence is a "natural" phenomenon, one that spontaneously
emerges from the biophysical world; for that is plainly one of the
issues to be settled by investigation and analysis in light of
empirical data, conceptual issues and comparative difficulties, not
dismissed by making question-begging evolutionary materialist
assertions. Cf App 6 below. [Also, HT
StephenB, a longstanding commenter at the Uncommon Descent [UD] blog,
for deeply underscoring the significance of the natural/supernatural
issue and for providing incisive comments, which have materially helped
shape the below.])
Now, Dembski's definition just above draws on the common-sense point that: [a] we may quite properly make a significantly different contrast from "natural vs. supernatural": i.e. "natural" vs. "artificial." [Where "natural" = "spontaneous" and/or "tracing to chance + necessity as the decisive causal factors" -- what we may term material causes; and, "artificial" = "intelligent."] He and other major design thinkers therefore propose that: [b] we may then set out to identify key empirical/ scientific
factors (= "signs of intelligence") to reliably mark the distinction.
One of these, is that when we see regularities of nature, we are seeing low contingency, reliably observable, spontaneous patterns and therefore scientifically explain such by law-like mechanical necessity: e.g. an unsupported heavy object, reliably, falls by "force of gravity." But, where we see instead high contingency -- e.g., which side of a die will be uppermost when it falls -- this is chance ["accident"] or intent ["design"].
Then, if we further notice that the observed highly contingent pattern
is otherwise very highly improbable [i.e. "complex"] and is independently functionally specified,
it is most credible that it is so by design, not accident. (Think
of a tray of several hundreds of dice, all with "six" uppermost: what
is its best explanation -- mechanical necessity, chance, or intent? [Cf
further details below.]) Consequently, we can easily see that [c] the attempt to infer or assert that intelligent
design thought invariably constitutes "a 'smuggling-in' of
'the supernatural' " (as opposed to explanation by reference to the "artificial" or "intelligent") as the contrast to
"natural," is a gross error; one that not only begs the question but also misunderstands, neglects or
ignores (or even sometimes, sadly, calculatedly distorts) the explicit
definition of ID and its methods of investigation as has
been repeatedly published and patiently explained by its leading
proponents. (Cf. here
for a detailed case study on how just this -- too often, sadly, less than
innocent -- mischaracterisation
of Design Theory is used by secularist advocates such as the ACLU.)
Further, given the significance of what routinely
happens when we see an apparent message, we know or should know that [d] we routinely and confidently infer from signs of intelligence to the existence and action of intelligence. On this, we should therefore again observe that Sir Francis Crick noted to his son, Michael, in 1953, in the already quoted letter: "Now we believe that the DNA is a code. That is, the order of
bases (the letters) makes one gene different from another gene (just as
one page of print is different from another)."
For, complex, functional messages, per reliable observation, credibly trace to intelligent senders.
This holds, even where in certain particular cases one may then wish to raise the subsequent question: what
is the identity (or even, nature) of the particular intelligence inferred to be the
author of certain specific messages? In turn, this may lead to
broader, philosophical --
that is, worldview level -- questions. Observe carefully, though: [e] such
questions go beyond the "belt" of science theories, proper, into the
worldview-tinged issues that -- as Imre Lakatos reminded
us -- are embedded in the inner core of scientific research programmes,
and are in the main addressed through philosophical
rather than specifically scientific methods.
[It helps to remember that for a long time, what we call "science" today was
termed "natural
philosophy."] Also, I think it is wiser to
acknowledge that we have no satisfactory explanation of a matter,
rather than insist that one will only surrender one's position (which
has manifestly failed after reasonable trials)
if a "better" one emerges -- all the while judging "better" by
selectively hyperskeptical criteria.
In short, those who would make such a rhetorical
dismissal, would do well to ponder anew the
cite at the head of this web page. For, the key insight of Cicero
[C1 BC!] is that, in particular, a
sense-making (thus, functional), sufficiently complex string of digital characters is
a signature of a true
message produced by an
intelligent actor, not a likely product of a
random process. He then [logically speaking] goes
on to ask concerning the evident FSCI in nature, and challenges those
who would explain it by reference to chance collocations of
atoms.
That is a good challenge, and it is one that should
not be ducked by worldview-level begging of serious definitional
questions or -- worse -- shabby rhetorical misrepresentations and
manipulations.
Therefore,
let us now consider in a little more detail a situation where an
apparent message is received. What does that mean? What does it imply
about the origin of the message . . . or, is it just noise that "got lucky"?
- If an apparent message is received, it means that
something is working as an intelligible -- i.e. functional
-- signal for the receiver. In effect, there is a
standard way to make and send and recognise and use messages in some
observable entity [e.g. a radio, a computer network, etc.], and there
is now also some observed event, some variation in a physical
parameter, that corresponds to it. [For instance, on this web page as
displayed on your monitor, we have a pattern of dots of light and dark
and colours on a computer screen, which correspond, more or less, to
those of text in English.]
- Information theory, as Fig A.1 illustrates, then
observes that if we have a receiver, we credibly
have first had a transmitter, and a channel
through which the apparent message has come; a meaningful message that
corresponds to certain codes or standard patterns
of communication and/or intelligent action. [Here, for instance,
through HTTP and TCP/IP, the original text for this web page has been
passed from the server on which it is stored, across the Internet, to
your machine, as a pattern of binary digits in packets. Your computer
then received the bits through its modem, decoded the digits, and
proceeded to display the resulting text on your screen as a complex, functional coded pattern of dots of light and colour. At each stage,
integrated, goal-directed intelligent action is deeply involved,
deriving from intelligent agents -- engineers and computer programmers.
We here consider of course digital signals, but in principle anything
can be reduced to such signals, so this does not affect the generality
of our thoughts.]
- Now, it is of course entirely possible, that the
apparent message is "nothing but" a lucky burst of noise
that somehow got through the Internet and reached your machine. That
is, it is logically and physically possible [i.e.
neither logic nor physics forbids it!] that every
apparent message you have ever got across the Internet -- including not
just web pages but also even emails you have received -- is nothing but
chance and luck: there is no intelligent source that actually sent such a message
as you have received; all is just lucky
noise:
"LUCKY NOISE"
SCENARIO: Imagine a world in which somehow all the "real"
messages sent "actually" vanish into cyberspace and "lucky noise"
rooted in the random behaviour of molecules etc, somehow substitutes
just the messages that were intended -- of course, including whenever
engineers or technicians use test equipment to
debug telecommunication and computer systems! Can you find a
law of logic or physics that: [a] strictly
forbids such a state of affairs from possibly existing;
and, [b] allows you to strictly
distinguish that from the "observed world" in which we think we live?
That is, we are back to a Russell "five-
minute- old- universe"-type
paradox. Namely, we cannot empirically distinguish the world we think
we live in from one that was instantly created five minutes ago with
all the artifacts, food in our tummies, memories etc. that we
experience. We solve such paradoxes by worldview
level inference to best explanation, i.e. by insisting that unless
there is overwhelming, direct evidence that leads us to that
conclusion, we do not live in Plato's
Cave of
deceptive shadows that we only imagine is reality, or that we are
"really" just brains in vats stimulated by some mad scientist, or we
live in a The Matrix
world, or the like. (In turn, we can therefore see just how deeply embedded key
faith-commitments are in our very rationality, thus all worldviews and
reason-based enterprises, including science. Or, rephrasing for
clarity: "faith" and
"reason" are not opposites; rather, they are inextricably intertwined
in the faith-points
that lie at the core of all worldviews. Thus, resorting
to selective
hyperskepticism
and objectionism to dismiss another's faith-point [as noted above!], is
at best self-referentially inconsistent; sometimes, even hypocritical
and/or -- worse yet -- willfully deceitful. Instead, we should
carefully work through the
comparative difficulties
across live options at worldview level, especially
in discussing matters of fact. And it is in that context of
humble self consistency and critically aware, charitable
open-mindedness that we can now reasonably proceed with this
discussion.)
- In short, none of us
actually lives or can consistently live as though s/he seriously
believes that: absent absolute proof to the contrary, we must
believe that all is noise. [To see the force of this,
consider an example posed by Richard Taylor. You are sitting in a
railway carriage and seeing stones you believe to have been
randomly arranged, spelling out: "WELCOME TO WALES." Would
you believe the apparent message? Why or why not?]
Q:
Why then do we believe in intelligent sources behind the web pages and
email messages that we receive, etc., since we cannot ultimately
absolutely prove that such is the case?
ANS:
Because we believe the
odds of such "lucky noise" happening by chance are so
small, that we intuitively simply ignore it. That is, we all
recognise that if an apparent message is contingent [it
did not have to be as
it is, or even to
be at all], is functional within
the context of communication, and is sufficiently complex that it is
highly unlikely to have happened by chance, then it is much better to
accept the explanation that it is what it appears to be -- a message
originating in an intelligent [though perhaps not wise!] source -- than
to revert to "chance" as the default assumption. Technically,
we compare how close the received signal is to legitimate messages, and
then decide that it is likely to be the "closest" such message. (All of
this can be quantified, but this intuitive level discussion is enough
for our purposes.)
In short, we all intuitively and even routinely
accept that: Functionally
Specified, Complex Information, FSCI, is a signature
of messages originating in intelligent sources.
Thus, if we then try to dismiss the study of such
inferences to design as "unscientific," when they may cut across our
worldview preferences, we are plainly being grossly inconsistent.
Further to this, the common attempt to pre-empt the
issue through the
attempted secularist redefinition of science as
in effect "what can be explained on the premise of evolutionary
materialism - i.e. primordial matter-energy joined
to cosmological- + chemical- + biological macro- + sociocultural-
evolution, AKA 'methodological
naturalism' " [ISCID def'n: here]
is itself yet
another begging of the linked worldview level questions.
For in fact, the issue in the communication
situation once an apparent message is in hand is:
inference to (a) intelligent
-- as opposed to supernatural
-- agency [signal] vs. (b) chance-process [noise]. Moreover,
at least since Cicero,
we have recognised that the presence of functionally specified complexity
in such an apparent message helps us make that decision. (Cf.
also Meyer's closely related discussion of the demarcation
problem here.)
More
broadly the decision faced once we see an apparent message, is first to
decide its source across a trichotomy: (1) chance; (2) natural regularity rooted in
mechanical necessity
(or as Monod
put it in his famous 1970 book, echoing
Plato, simply: "necessity");
(3) intelligent agency.
These are the three commonly observed causal forces/factors in our
world of experience and observation. [Cf. abstract of a
recent technical, peer-reviewed, scientific discussion here.
Also, cf. Plato's remark in his The
Laws, Bk X, excerpted below.]
Each
of these forces stands at the same basic level as an
explanation or cause,
and so the proper question is to rule in/out relevant factors at work,
not to decide before the fact that one or the other is not admissible
as a "real" explanation.
This often confusing issue is best initially approached/understood through a concrete example . . .
A CASE STUDY ON CAUSAL
FORCES/FACTORS -- A Tumbling Die: Heavy objects tend to fall under
the law-like natural
regularity we
call gravity. If the object is a die, the face that ends up on the top
from the set {1, 2, 3, 4, 5, 6} is for practical purposes a matter of chance.
But, if the die is cast
as part of a game, the results are as much a product of agency as of natural
regularity and chance. Indeed, the agents in question are
taking advantage of natural regularities and chance to achieve their purposes!
This
concrete, familiar illustration should suffice to show that the three causal factors
approach is not at all arbitrary or dubious -- as some are
tempted to imagine or assert. [More details . . .]
Then also, in certain highly important
communication situations, the next issue after detecting agency as best causal explanation, is whether the detected signal
comes from (4) a trusted source, or (5) a malicious interloper, or is a
matter of (6) unintentional cross-talk. (Consequently, intelligence
agencies have a significant and very practical interest in the
underlying scientific questions of inference to agency then
identification of the agent -- a potential (and arguably, probably
actual) major application of the theory of the inference to design.)
Next, to
identify which of the three is most important/ the best explanation in
a given case, it is useful to extend the principles of statistical
hypothesis testing through Fisherian elimination to create the Explanatory Filter:
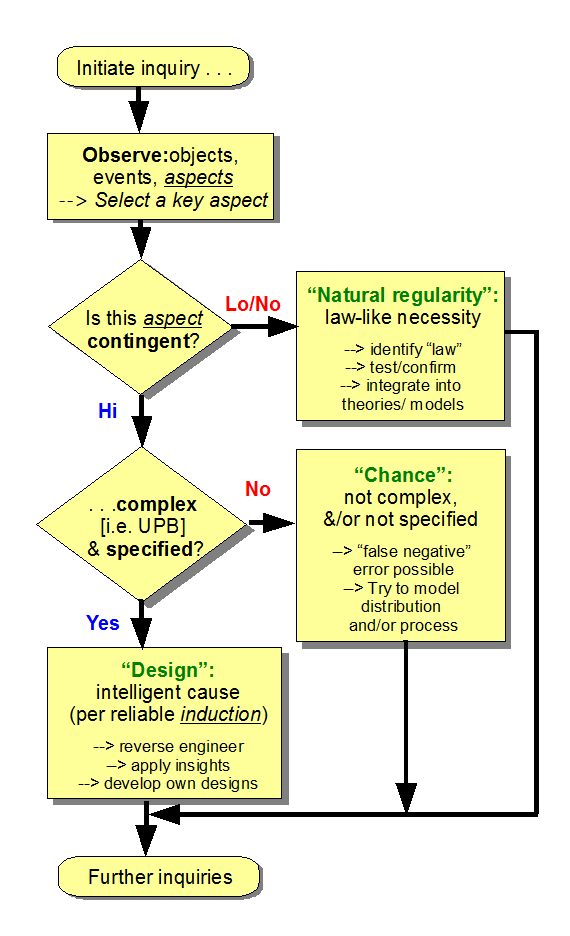
|
Fig A.2: The explanatory filter allows for an evidence-based investigation of causal factors. By setting a quite strict threshold between chance and intelligence, i.e. the UPB, a reliable inference to design may be made when we see especially functionally specific, complex information
[FSCI] -rich patterns, but at the cost of potentially ruling "chance"
incorrectly.
UNDERLYING LOGIC: Once the aspect of a process, object or phenomenon under
investigation is significantly contingent, natural regularities rooted in mechanical necessity can plainly be ruled out as the dominant factor for that facet. So, the key issue is whether the observed high contingency is unambiguously evidently purposefully directed; relative to the type and body of experiences or observations that would warrant a reliable inductive inference. For this, the UPB sets a reasonable, conservative and reliable threshold:
Unless (i) the search resources of the observed cosmos would generally be fruitlessly exhausted
in an attempt to arrive at the observed result (or materially similar
results) by random searches, AND (ii) the outcome is [especially
functionally] specified, observed high contingency is by default assigned to "chance."
Thus, FSCI and the associated wider concept, complex, specified information [CSI] are identified as reliable (but not exclusive) signs of intelligence. [In fact, even though -- strictly -- "lucky noise" could account for the existence of apparent messages such as this web page, we routinely identify that if an apparent message has functionality, complexity and specification, it is better explained by intent than by accident and confidently infer to intelligent rather than mechanical cause. This is proof enough -- on pain of self-referentially incoherent selective hyperskepticism -- of just how reasonable the explanatory filter is.]
________________ |
The second
major step is to refine our thoughts, through discussing the
communication theory definition of and its approach to measuring
information. A good place to begin this is with British Communication
theory expert F. R Connor, who gives us an excellent
"definition by discussion" of what information
is:
From a human point of view the word 'communication'
conveys the idea of one person talking or writing to another in words
or messages . . . through the use of words derived from an alphabet
[NB: he here means, a "vocabulary" of possible signals]. Not all words
are used all the time and this implies that there is a minimum number
which could enable communication to be possible. In order to
communicate, it is necessary to transfer information to another person,
or more objectively, between men or machines.
This naturally leads to the definition of the word
'information', and from a communication point of view it does not have
its usual everyday meaning. Information is not what is
actually in a message but what could constitute a
message. The word could implies a
statistical definition in that it involves some selection of the
various possible messages. The important quantity
is not the actual information content of the message but rather its
possible information content.
This is the quantitative definition of information
and so it is measured in terms of the number of selections that could
be made. Hartley was the first to suggest a logarithmic unit . . . and
this is given in terms of a message probability. [p. 79, Signals,
Edward Arnold. 1972. Bold emphasis added. Apart from the justly
classical status of Connor's series, his classic work dating from
before the ID controversy arose is deliberately cited, to give us an
indisputably objective benchmark.]
To quantify the above definition of what is perhaps
best descriptively termed information-carrying
capacity, but has long been simply termed information
(in the "Shannon sense" - never mind his disclaimers . . .), let us
consider a source that emits symbols from a vocabulary: s1,s2,
s3, . . . sn, with
probabilities p1, p2, p3,
. . . pn. That is, in a "typical" long string of
symbols, of size M [say this web page], the average number that are
some sj, J, will be such that the ratio J/M
--> pj, and in the limit attains
equality. We term pj the a priori
-- before the fact -- probability of symbol sj.
Then, when a receiver
detects sj, the question arises as to
whether this was sent. [That is, the mixing in of noise
means that received messages are prone to misidentification.] If on
average, sj will be detected correctly a
fraction, dj of the time, the a
posteriori -- after the fact -- probability of sj
is by a similar calculation, dj. So, we now
define the information content of symbol sj as,
in effect how much it surprises us on average when
it shows up in our receiver:
I = log [dj/pj],
in bits [if the log is base 2, log2]
. . . Eqn 1
This
immediately means that the question of receiving information
arises AFTER an apparent symbol sj has been
detected and decoded. That is, the
issue of information inherently implies an inference to
having received an intentional signal in the face of the possibility
that noise could be present. Second, logs are
used in the definition of I, as they give an additive property: for,
the amount of information in independent signals, si
+ sj, using the above definition, is such that:
I total = Ii + Ij
. . . Eqn 2
For
example, assume that dj for the moment is 1,
i.e. we have a noiseless channel so what is transmitted is just what is
received. Then, the information in sj is:
I = log [1/pj] = - log pj
. . . Eqn 3
This
case illustrates the additive property as well, assuming that symbols si
and sj are independent. That means that the
probability of receiving both messages is the product of the
probability of the individual messages (pi *pj);
so:
Itot = log1/(pi
*pj) = [-log pi] + [-log pj]
= Ii + Ij . . . Eqn 4
So
if there are two symbols, say 1 and 0, and each has probability 0.5,
then for each, I is - log [1/2], on a base of 2, which is 1 bit. (If
the symbols were not equiprobable, the less probable binary digit-state
would convey more than, and the more probable, less than, one
bit of information. Moving over to English text, we can
easily see that E is as a rule far more probable than X, and that Q is
most often followed by U. So, X conveys more information than E, and U
conveys very little, though it is useful as redundancy, which gives us
a chance to catch errors and fix them: if we see "wueen"
it is most likely to have been "queen.")
Further
to this, we may average the information per symbol in the communication
system thusly (giving in termns of -H to make the additive relationships clearer):
- H
= p1 log p1 + p2
log p2 + . . . + pn log pn
or, H = - SUM [pi log pi]
. . . Eqn 5
H,
the average
information per symbol transmitted [usually, measured as: bits/symbol], is
often termed the Entropy; first, historically, because it resembles one
of the expressions for entropy in statistical thermodynamics. As Connor
notes: "it is often referred to as the
entropy of the source." [p.81, emphasis added.] Also,
while this is a somewhat controversial view in Physics, as is briefly
discussed in Appendix 1below, there
is in fact an informational interpretation of
thermodynamics that shows that informational and thermodynamic entropy
can be linked conceptually as well as in mere mathematical
form. Though somewhat controversial even in quite recent years, this is
becoming more broadly accepted in physics and information theory, as
Wikipedia now discusses [as at April 2011] in its article on Informational Entropy (aka Shannon Information, cf also here):
At an everyday practical level the links between information entropy
and thermodynamic entropy are not close. Physicists and chemists are apt
to be more interested in changes in entropy as a system spontaneously evolves away from its initial conditions, in accordance with the second law of thermodynamics, rather than an unchanging probability distribution. And, as the numerical smallness of Boltzmann's constant kB indicates, the changes in S / kB
for even minute amounts of substances in chemical and physical
processes represent amounts of entropy which are so large as to be right
off the scale compared to anything seen in data compression or signal
processing.
But, at a multidisciplinary level, connections can be made
between thermodynamic and informational entropy, although it took many
years in the development of the theories of statistical mechanics and
information theory to make the relationship fully apparent. In fact, in
the view of Jaynes (1957), thermodynamics should be seen as an application
of Shannon's information theory: the thermodynamic entropy is
interpreted as being an estimate of the amount of further Shannon
information needed to define the detailed microscopic state of the
system, that remains uncommunicated by a description solely in terms of
the macroscopic variables of classical thermodynamics. For example,
adding heat to a system increases its thermodynamic entropy because it
increases the number of possible microscopic states that it could be in,
thus making any complete state description longer. (See article: maximum entropy thermodynamics.[Also,another article remarks: >>in the words of G. N. Lewis
writing about chemical entropy in 1930, "Gain in entropy always means
loss of information, and nothing more" . . . in the
discrete case using base two logarithms, the reduced Gibbs entropy is
equal to the minimum number of yes/no questions that need to be answered
in order to fully specify the microstate, given that we know the
macrostate.>>]) Maxwell's demon
can (hypothetically) reduce the thermodynamic entropy of a system by
using information about the states of individual molecules; but, as Landauer
(from 1961) and co-workers have shown, to function the demon himself
must increase thermodynamic entropy in the process, by at least the
amount of Shannon information he proposes to first acquire and store;
and so the total entropy does not decrease (which resolves the paradox).
Summarising Harry Robertson's Statistical Thermophysics
(Prentice-Hall International, 1993) -- excerpting desperately and
adding emphases and explanatory comments, we can see, perhaps, that
this should not be so surprising after all. (In effect, since we do not
possess detailed knowledge of the states of the vary large number of
microscopic particles of thermal systems [typically ~ 10^20 to 10^26; a
mole of
substance containing ~ 6.023*10^23 particles; i.e. the Avogadro
Number], we can only view them in terms of those gross averages we term
thermodynamic variables [pressure, temperature, etc], and so we cannot
take advantage of knowledge of such individual particle states that
would give us a richer harvest of work, etc.)
For,
as he astutely observes on pp. vii - viii:
.
. . the standard assertion that molecular chaos exists is nothing more
than a poorly disguised admission of ignorance, or lack of detailed
information about the dynamic state of a system . . . . If I am able to perceive order, I
may be able to use it to extract work from the system, but if
I am unaware of internal correlations, I cannot use them for
macroscopic dynamical purposes. On this basis, I shall
distinguish heat from work, and thermal energy from other forms
. . .
And,
in more details, (pp. 3 - 6, 7, 36, cf
Appendix 1 below for a more detailed development of
thermodynamics issues and their tie-in with the inference to design;
also see recent ArXiv papers by Duncan and Samura here
and here):
.
. . It has long been
recognized that the assignment of probabilities to a set represents
information, and that some probability sets represent more information
than others . . . if one of the probabilities say p2
is unity and therefore the others are zero, then we know that the
outcome of the experiment . . . will give [event] y2.
Thus we have complete information . . . if we have no basis . . . for
believing that event yi is more or less likely
than any other [we] have the least possible information about the
outcome of the experiment . . . . A remarkably simple and clear
analysis by Shannon [1948]
has provided us with a quantitative measure of the uncertainty, or
missing pertinent information, inherent in a set of probabilities [NB:
i.e. a probability different from 1 or 0 should be seen as, in part, an index of ignorance]
. . . .
[deriving
informational entropy, cf. discussions here,
here,
here,
here
and here;
also Sarfati's discussion of debates and the issue of open systems here
. . . ]
H({pi}) = - C [SUM over i] pi*ln pi, [. . . "my" Eqn 6]
[where
[SUM over i] pi = 1, and we can define also
parameters alpha and beta such that: (1) pi =
e^-[alpha + beta*yi]; (2) exp [alpha] = [SUM
over i](exp - beta*yi) = Z [Z being in effect the
partition function across microstates, the "Holy Grail" of
statistical thermodynamics]. . . .
[H], called the
information entropy,
. . . correspond[s] to the thermodynamic
entropy [i.e. s, where also it was shown by
Boltzmann that s = k ln w], with C = k, the Boltzmann constant, and yi an energy level, usually ei, while [BETA] becomes 1/kT, with T
the thermodynamic temperature . . . A thermodynamic system
is characterized by a microscopic structure that is not observed in
detail . . . We attempt to develop a theoretical
description of the macroscopic properties in terms of its underlying
microscopic properties, which are not precisely known. We attempt to
assign probabilities to the various microscopic states . . . based on a
few . . . macroscopic observations that can be related to averages of
microscopic parameters. Evidently the problem that we attempt
to solve in statistical thermophysics is exactly the one just treated
in terms of information theory. It should not be surprising, then, that
the uncertainty of information theory becomes a thermodynamic variable
when used in proper context . . . .
Jayne's
[summary rebuttal to a typical objection] is ". . . The entropy of a
thermodynamic system is a measure of the degree of ignorance of a
person whose sole knowledge about its microstate consists of the values
of the macroscopic quantities . . . which define its thermodynamic
state. This is a perfectly 'objective' quantity . . . it is a function
of [those variables] and does not depend on anybody's personality.
There is no reason why it cannot be measured in the laboratory." . . .
. [pp. 3 - 6, 7, 36; replacing Robertson's use of S for Informational
Entropy with the more standard H.]
As
is discussed briefly in Appendix 1,
Thaxton, Bradley and Olsen [TBO], following
Brillouin et al, in the 1984
foundational work for the modern Design Theory, The Mystery of Life's Origins
[TMLO], exploit
this information-entropy link, through the idea of moving
from a random to a known microscopic configuration in the creation of
the bio-functional polymers of life, and then -- again following Brillouin
-- identify a quantitative information metric for the information of
polymer molecules. For, in
moving from a random to a functional molecule, we have in effect an
objective, observable increment in information about the molecule. This
leads to energy constraints, thence to a calculable concentration of
such molecules in suggested, generously "plausible" primordial "soups."
In effect, so unfavourable is the resulting thermodynamic balance, that
the concentrations of the individual functional molecules in such a
prebiotic soup are arguably so small as to be negligibly different from
zero on a planet-wide scale.
By many orders of magnitude, we
don't get to even one molecule each of the required polymers per
planet, much less bringing them together in the required proximity for
them to work together as the molecular machinery of life.
The linked chapter gives the details. More modern analyses [e.g.
Trevors and Abel, here
and here],
however, tend to speak directly in terms of
information and probabilities rather than the more arcane world of
classical and statistical thermodynamics, so let us now return to that
focus; in particular addressing information in its functional sense, as
the third step in this preliminary analysis.
As the third major step, we now turn
to information technology, communication systems and computers, which
provides a vital clarifying side-light from another view on how complex,
specified information functions
in information processing systems:
[In the context of computers] information
is data -- i.e. digital representations of raw
events, facts, numbers and letters, values of variables, etc. -- that
have been put together in ways suitable for storing in special data
structures [strings of characters, lists, tables, "trees" etc], and for
processing and output in ways that are useful [i.e. functional]. . . .
Information is distinguished from [a] data: raw events, signals, states
etc represented digitally, and [b] knowledge: information that has been
so verified that we can reasonably be warranted, in believing it to be
true. [GEM, UWI FD12A Sci Med and Tech in Society
Tutorial Note 7a, Nov 2005.]
That is, we
have now made a step beyond mere capacity to carry or convey
information, to the function
fulfilled by meaningful -- intelligible, difference making -- strings
of symbols. In effect, we here introduce into the concept,
"information," the meaningfulness, functionality
(and indeed, perhaps even
purposefulness) of messages
-- the fact that they make a
difference to the operation and/or structure of systems using such
messages, thus to outcomes;
thence, to relative or absolute success or failure of information-using
systems in given environments.
And, such outcome-affecting functionality is of
course the underlying reason/explanation for the use of information in
systems. [Cf. the recent peer-reviewed, scientific discussions here,
and here
by Abel and Trevors, in the context of the molecular
nanotechnology of life.] Let us note as well that since in general
analogue signals can be digitised [i.e. by some form of
analogue-digital conversion], the discussion thus far is quite general
in force.
So, taking these three main points together, we can
now see how information is conceptually and quantitatively
defined, how it can be measured in bits, and how it is used in
information processing systems; i.e., how it becomes functional.
In short, we can now understand that:
Functionally
Specific, Complex Information [FSCI]
is a
characteristic of complicated messages that function in systems to
help them practically solve problems faced by the systems in their
environments. Also, in cases where we directly and independently know
the source of such FSCI (and its accompanying functional organisation)
it is, as a general rule, created by purposeful, organising intelligent agents. So, on empirical observation based induction, FSCI is a reliable sign of such design,
e.g. the text of this web page, and billions of others all across the
Internet. (Those who object to this, therefore face the burden of
showing empirically that such FSCI does in fact -- on observation
-- arise from blind chance and/or mechanical necessity without
intelligent direction, selection, intervention or purpose.)
Indeed, this FSCI perspective lies at the foundation of
information theory:
(i) recognising signals as intentionally constructed messages transmitted in the face of the possibility
of noise,
(ii) where also, intelligently constructed signals have characteristics of purposeful specificity, controlled complexity and system- relevant functionality based on meaningful rules that distinguish them from meaningless noise;
(iii) further noticing that signals exist in functioning generation- transfer and/or storage- destination systems that
(iv)
embrace co-ordinated transmitters, channels, receivers, sources and sinks.
That this
is broadly recognised as true, can be seen from a surprising source,
Dawkins, who is reported to have said in his The Blind
Watchmaker (1987), p. 8:
Hitting upon
the lucky number that opens the bank's safe [NB: cf. here the case in
Brown's The Da Vinci
Code] is the equivalent, in our analogy, of hurling scrap
metal around at random and happening to assemble a Boeing 747. [NB:
originally, this imagery is due to Sir Fred Hoyle, who used it to argue
that life on earth bears characteristics that strongly suggest design.
His suggestion: panspermia
-- i.e. life drifted here, or else was planted here.] Of all the
millions of unique and, with hindsight equally improbable, positions of
the combination lock, only one opens the lock. Similarly, of all the
millions of unique and, with hindsight equally improbable, arrangements
of a heap of junk, only one (or very few) will fly. The uniqueness of
the arrangement that flies, or that opens the safe, has nothing to do
with hindsight. It is specified in advance. [Emphases and parenthetical note added,
in tribute to the late Sir Fred Hoyle. (NB: This case also shows that
we need not see boxes labelled "encoders/decoders" or
"transmitters/receivers" and "channels" etc. for the model in Fig. 1
above to be applicable; i.e. the model is abstract rather
than concrete: the critical issue is functional, complex information,
not electronics.)]
Here, we see how the significance of FSCI naturally
appears in the context of considering the physically and logically
possible but vastly improbable creation of a jumbo jet by
chance. Instantly, we see that mere random chance acting in a context
of blind natural forces is a most unlikely explanation, even though the
statistical behaviour of matter under random forces cannot rule it
strictly out. But it is so plainly vastly improbable, that, having seen
the message -- a flyable jumbo jet -- we then make
a fairly easy and highly confident inference to its most likely origin:
i.e. it is an intelligently designed artifact. For, the a posteriori
probability of its having originated by chance is obviously minimal --
which we can intuitively recognise, and can in principle
quantify.
FSCI
is also an observable, measurable quantity; contrary to what is
imagined, implied or asserted by many objectors. This may be most
easily seen by using a quantity we are familiar with: functionally specific bits [FS bits], such as those that define the information on the screen you are most likely using to read this note:
1 --> These bits are functional, i.e. presenting a sceenful of (more or less) readable and coherent text.
2 --> They are specific,
i.e. the screen conforms to a page of coherent text in English in a web browser
window; defining a relatively small target/island of function by comparison with the
number of arbitrarily possible bit configurations of the screen.
3 --> They are contingent,
i.e your screen can show diverse patterns, some of which are
functional, some of which -- e.g. a screen broken up into "snow" --
would not (usually) be.
4 --> They are quantitative:
a screen of such text at 800 * 600 pixels resolution, each of bit depth
24 [8 each for R, G, B] has in its image 480,000 pixels, with
11,520,000 hard-working, functionally specific bits.
5 --> This is of course well beyond a "glorified common-sense" 500 - 1,000 bit rule of thumb complexity threshold at which contextually and functionally specific information is sufficiently complex that the explanatory filter would confidently rule such a screenful of text "designed," given that -- since there are at most that many quantum states of the atoms in it -- no search on the gamut of our observed cosmos can exceed 10^150 steps:
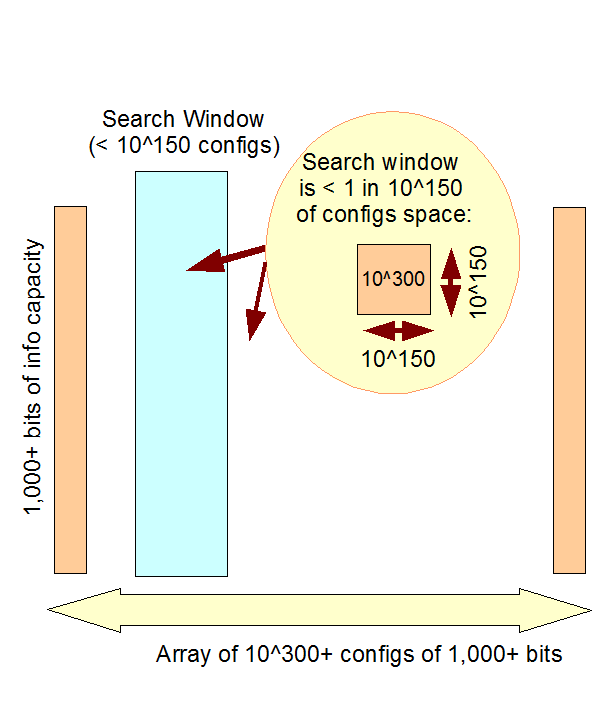 |
| Fig A.3: The needle- in-the haystack search challenge: the credibly accessible search window for our observed cosmos (< 10^150 states) is a tiny fraction of the configuration space specified by 1,000 or more bits of information storage capacity. |
EXPLANATION: This empirically anchored rule of thumb limit credibly works because the set of locally accessible states
[at ~ 10^43 states/second] for our observed cosmos as a whole [~ 10^80 atoms] across its usually estimated
lifespan [~ 10^25 seconds] is ~ 10^150 states. These states are in large part dynamically (and thus
more or less "smoothly") connected to earlier, neighbouring ones; all
the way back to the big bang and its initial conditions and
constraints.
So, [a]
search in the space of possible states of an abstractly possible
universe is constrained relative to the credible starting conditions of
the observed cosmos; indeed, the observed cosmos will not be able to search out 10^150 states. For instance, MIT Mechanical Engineering professor Seth Lloy'd calculation is that "[t]he
amount of information that the Universe can register and the number
of elementary operations that it can have performed over its history
are calculated. The Universe can have performed 10^120 ops on
10^90 bits ( 10^120 bits including gravitational degrees of
freedom)." [Cf. discussions here and here.
It takes a significant number of such operations to carry out any
process (such as running the general dynamics of the universe), much less to do one step in a search process. So, by far and
away, most of the operations would not be available for a search
process.]
Now, too, it is known that [b]
observed functionality of systems and elements in systems is vulnerable to often quite slight
perturbation, i.e. we deal with islands of function in a sea of
non-function, and also that [c] the functions delimited by 500 - 1,000+ bits of information-storing capacity are complex. This leads to: [d] deep isolation of the islands of function, or at least of the archipelagos in which they may sit.
[This is why for instance, even ardent Darwinists typically fear
exposure to mutation inducing trauma, e.g. chemicals or radiation -- we
all know from observation that dysfunctions such as cancer are the
overwhelmingly likely result from significant random changes to genes or other
functional molecules in the cells of our bodies. Similarly, it fits
well with the fossil record's observed pattern of sudden emergence, structural-functional stasis and disappearance. Likewise, contrary to the urban legend
on monkeys and typewriters, Mr Gates does not write new versions of his
operating system by putting Bonobos to bang away at keyboards, thus
modifying the existing OS at random! (This family of PC operating
systems also shows that effective design is not necessarily "perfect" or
even "optimal" relative to any one purpose or aspect: trade-offs and constraints
are key challenges of real-world design, especially if it has to be
robust against the vagaries of a highly uncertain environment.)]
So,
if [e] we suggest a provisional upper limit for the universal probability
bound based on in aggregate as many functional states as there are
accessible quantum states for our observed comsos, i.e. 10^150, and
[f] isolate the islands and archipelagos at least to the degree that a search window of that many
states are at most 1 in 10^150 of the states in the configuration space set by
the 1,000+ bits [cf. Fig. A.4], then [g] it becomes maximally unlikely
to initially get to the islands of function, or to hop beyond very
local archipelagos, through random search processes culling by degree
of functional success. That sets up 10^300 states as a plausible upper
bound; where also 1,000 bits corresponds to 2^1,000 ~ 1.071 * 10^301
accessible states.
To
see what that means for bio-functionality, consider now a hypothetical
enzyme of 232 amino acid residues [20^232 ~ 2^1,000], where each AA is
of general form H2N-CHR-COOH; proline being the main exception, as its R-group bonds back to the N-atom, making it technically an imino acid.
The "hypothesine" protein would be functional in a specific reaction, and in a particular
cluster of processes in the cell; being useless (or worse than merely
useless) in the wrong cell-process contexts. (For, function is contextually specific.) Now, consider for a simple initial argument that --
bearing in mind that the different R-groups are considerably divergent
in shape, size, reactivity, H-atom locations, tendency to mix with aqueous media, etc. -- on average 150 of the R-groups could
take up any of 10 AA values each in any
combination; the remainder being fixed by, say, the requisites of
key-lock fittting and/or chemical functionality. This would give us a variability of 10^150
configurations that preserve the required specific functionality.
(AT A MORE COMPLEX LEVEL: If,
instead, we model the the individual AA's as varying at random among 4 - 5 "similar" R-group
AA's on average without causing dys-functional change, the full 232-length string
would vary across 10^150 states. As a cross-check, Cytochrome-C, a commonly studied protein of about 100 AA's that is used for taxonomic research, typically varies
across 1 - 5 AA's in each position, with a few AA positions showing more variability
than that. About a third of the AA positions are invariant across a
range from humans to rice to yeast. That is, the observed variability,
if scaled up to 232 AA's, would be well within the 10^150 limit
suggested; as, e.g. 5^155 ~ 2.19 * 10^108. [Cf also this summary of a study of the same protein among 388 fish species.]
Moreover, from Voegel's summary of Hurst, Haig and Freeland, the real-world DNA code evidently exhibits a near-optimal degree of built-in
redundancy
such that typical random single-point changes in three-letter codons
will replace the
R-group with one of a few chemically and/or structurally very
similar
ones; reducing the likelihood of functional deranging of folded
[secondary] and/or agglomerated [tertiary] structures. [Variablity at
random across all 20 AA's is not reasonable; as that would make proline
typically ~ 5% of the changes, and proline's structural rigidity due to
the R-group's bonding back to the N-atom would most likely destroy
desired folding and onward structures, thus deranging functionality. It is
noteworthy, for instance, that sickle-cell anaemia is typically caused by a single point change in a haemoglobin AA sequence.]
Given the
key-lock fitting requisites of working proteins in the cell, this sort
of "close replacement" is credibly responsible for most of the
variability across AA configurations as is studied for say the
Cytosine-C taxonomic trees for life-forms.)
Similarly, a 143-element ASCII text
string (about eighteen typical English words, with provision for spaces
and punctuation) has a contingency space of ~ 2^1,000. Starting from
such a string that is correctly spelled, has correct grammar and is
contextually relevant, it would be quite hard to get 10^150 random
variations of characters that would also be of correct spelling and
grammar, and just as much contextually relevant. It would be even
harder to get to the first such sentence by random chance.
In short, the rule of thumb is plausible and has a reasonable fit to a key context, the biological world.
Ultimately,
though, the warrant for such a rule of thumb is provisional (as are all
significant scientific findings and models) and based on
empirical tests. In effect: can
you identify a well established case of independently known origin
where a functionally specified entity with at least 1,000 bits of
storage capacity has been generated by chance + necessity without the
intelligent intervention of an agent (e.g through an "oracle" in a
genetic algorithm that broadcasts information on and so rewards
closeness to islands of function)? [A routine example of such a
test would be contextually relevant ASCII text in English
embracing 143 or more characters, as 128^143 ~ 2^1,000. That is, the
test is very widely carried out and the rule is strongly empirically supported.]
6 --> So we can construct a rule of thumb functionally specific bit metric for FSCI:
a] Let complex contingency [C]
be defined as 1/0 by comparison with a suitable exemplar, e.g. a tossed
die that on similar tosses may come up in any one of six states: 1/ 2/
3/ 4/ 5/ 6; joined to having at least 1,000 bits of information storage capacity. That is, diverse configurations of the component parts
or of outcomes under similar initial circumstances must be credibly
possible, and there must be at least 2^1,000 possible configurations.
b]
Let specificity [S] be identified as 1/0 through specific functionality [FS] or
by compressibility of description of the specific information [KS] or similar
means that identify specific target zones
in the wider configuration space. [Often we speak of this as "islands
of function" in "a sea of non-function." (That is, if moderate
application of random noise altering the bit patterns will beyond a
certain point destroy function [notoriously common for engineered
systems that require working parts mutually co-adapted at an operating
point, and also for software and even text in a recognisable language]
or move it out of the target zone, then the topology is similar to that
of islands in a sea.)]
c]
Let degree of complexity [B]
be defined by the quantity of bits
to store the relevant information, where from [a] we already see how
500 - 1,000 bits serves as the
threshold for "probably" to "morally certainly" sufficiently
complex to meet the FSCI/CSI threshold by which a random walk from an
arbitrary initial configuration backed up by trial and error is utterly
unlikely to ever encounter an island of function, on the gamut of our
observed cosmos. (Such a random walk plus trial and error is a
reasonable model for the various naturalistic mechanisms proposed for
chemical and body plan level biological evolution. It is worth noting
that "infinite monkeys" type tests have shown
that a search space of the order of 10^50 or so is searchable so
that functional texts can be identified and accepted on trial and
error. But searching 2^1,000 = 1.07 * 10^301 possibilities for islands
of function is a totally different matter.)
d] Define the vector {C, S, B}
based on the above [as we would take distance travelled and time
required, D and t: {D, t}], and take the element product C*S*B [as we
would take the element ratio D/t to get speed].
e] Now we identify the simple FSCI metric, X:
C*S*B = X,
. . . the required FSCI/CSI-metric in [functionally] specified bits.
f] Once we
are beyond 500 - 1,000 functionally specific bits, we are comfortably
beyond a threshold of sufficient complex and specific functionality
that the search resources of the observed universe would by far
and away most likely be fruitlessly exhausted on the sea of
non-functional states if a random walk based search (or generally
equivalent process) were used to try to get to shores of function on
islands of such complex, specific function.
[WHY: For, at 1,000 bits, the 10^150 states scanned by the observed universe acting as search engine would be comparable to: marking
one of the 10^80 atoms of the universe for just 10^-43 seconds out of
10^25 seconds of available time, then taking a spacecraft capable of
time travel and at random going anywhere and "any-when" in the observed
universe, reaching out, grabbing just one atom and voila that atom is
the marked atom at just the instant it is marked. In short, the
"search" resources are so vastly inadequate relative to the available
configuration space for just 1,000 bits of information storage capacity
that debates on "uniform probability distributions" etc are moot: the whole observed universe acting as a search engine could not put up a credible search of such a configuration space. And,
observed life credibly starts with DNA storage in the 100's of kilo
bits of information storage. (100 k bits of information storage
specifies a config space of order ~ 9.99 *10^30,102; which vastly
dwarfs the ~ 1.07 * 10^301 states specified by 1,000 bits.)]
7 --> For instance, for the 800 * 600 pixel PC screen, C = 1, S = 1, B = 11.52 * 10^6, so C*S*B = 11.52
* 10^6, FS bits. This is well beyond the threshold. [Notice that if the
bits were not contingent or were not specific, then X = 0
automatically. Similarly, if B < 500, the metric would indicate the
bits as functionally or compressibly etc specified, but
without enough bits to be comfortably beyond the UPB threshold. Of
course, the DNA strands of observed life forms start
at about 200,000 FS bits, and that for forms that depend on others for
crucial nutrients. 600,000 - 10^6 FS bits is a reported reasonable
estimate for a minimally complex independent life form.]
8 --> A more sophisticated (though sometimes controversial) metric has of course been given by Dembski, in a 2005 paper, as follows:
define
ϕS as . . . the number of patterns for which [agent] S’s
semiotic description of them is at least as simple as S’s
semiotic description of [a pattern or target zone] T. [26] . . . .
where M is the number of semiotic agents [S's] that within a context of
inquiry might also be witnessing events and N is the number of
opportunities for such events to happen . . . . [where also] computer
scientist Seth Lloyd has shown that 10^120 constitutes the maximal
number of bit operations
that the known, observable universe could have performed throughout
its entire multi-billion year history.[31] . . . [Then] for any
context of inquiry in which S might be endeavoring
to determine whether an event that conforms to a pattern T happened
by chance, M·N will be bounded above by 10^120. We thus define
the
specified complexity
[χ] of T given [chance hypothesis] H [in bits] . . . as [the negative base-2 log of the conditional probability P(T|H) multiplied by the number of similar cases ϕS(t) and also by the maximum number of binary search-events in our observed universe 10^120]
χ
= – log2[10^120
·ϕS(T)·P(T|H)].
9 --> When 1 >/= χ,
the probability of the observed event in the target zone or a similar
event is at least 1/2, so the available search resources of the observed cosmos across its estimated lifespan
are in principle adequate for an observed event [E] in the target zone to credibly occur by chance. But if χ
significantly exceeds 1 bit [i.e. it is past a threshold that as shown
below, ranges from about 400 bits to 500 bits -- i.e. configuration
spaces of order 10^120 to 10^150], that becomes increasingly
implausible. The
only credibly known and reliably observed cause for events of this last
class is intelligently directed contingency, i.e. design. Given the scope of the Abel plausibility bound for our solar system, where available probabilistic resources
qΩs = 10^43 Planck-time quantum [not chemical -- much, much slower] events per second x
10^17 s since the big bang x
10^57 atom-level particles in the solar system
Or, qΩs = 10^117 possible atomic-level events [--> and perhaps 10^87 "ionic reaction chemical time" events, of 10^-14 or so s],
. . . that is unsurprising.
10
--> Thus, we have a rule of thumb informational X-metric and a more
sophisticated informational Chi-metric for CSI/FSCI, both providing
reasonable grounds for confidently inferring to design. As will be shown below, both
rely on finding a reasonable measure for the information in an item on
a target or hot zone -- aka island of function where the zone is set
off observed function -- and then comparing this to a reasonable
threshold for sufficently complex that non-foresighted mechanisms (such
as blind watchmaker random walks from an initial start point and
leading to trial and error), will be maximally unlikely to reach such a
zone on the gamut of resources set by our observable cosmos. the Durston et al metric helps us see how that works.
11 --> Durston, Chiu, Abel and Trevors provide a third metric, the Functional H-metric in functional bits or fits, a functional bit extension of Shannon's H-metric of average information per symbol, here. The
way the Durston et al metric works by extending Shannon's H-metric of
the average info per symbol to study null, ground and functional states
of a protein's AA linear sequence -- illustrating and providing a
metric for the difference between order, randomness and functional
sequences discussed by Abel and Trevors -- can be seen from an excerpt
of the just linked paper. Pardon length and highlights, for clarity in
an instructional context:
Abel and Trevors have delineated three qualitative aspects of linear digital sequence complexity [2,3],
Random Sequence Complexity (RSC), Ordered Sequence Complexity (OSC) and
Functional Sequence Complexity (FSC). RSC corresponds to stochastic
ensembles with minimal physicochemical bias and little or no tendency
toward functional free-energy binding. OSC is usually patterned either
by the natural regularities described by physical laws or by
statistically weighted means. For example, a physico-chemical
self-ordering tendency creates redundant patterns such as
highly-patterned polysaccharides and the polyadenosines adsorbed onto
montmorillonite [4].
Repeating motifs, with or without biofunction, result in observed OSC
in nucleic acid sequences. The redundancy in OSC can, in principle, be
compressed by an algorithm shorter than the sequence itself. As Abel and
Trevors have pointed out, neither RSC nor OSC, or any combination of
the two, is sufficient to describe the functional complexity observed in
living organisms, for neither includes the additional dimension of
functionality, which is essential for life [5]. FSC includes the dimension of functionality [2,3]. Szostak [6] argued that neither Shannon's original measure of uncertainty [7] nor the measure of algorithmic complexity [8]
are sufficient. Shannon's classical information theory does not
consider the meaning, or function, of a message. Algorithmic complexity
fails to account for the observation that 'different molecular
structures may be functionally equivalent'. For this reason, Szostak
suggested that a new measure of information–functional information–is
required [6] . . . .
Shannon uncertainty, however, can be extended to measure the joint variable (X, F), where X represents the variability of data, and F functionality.
This explicitly incorporates empirical knowledge of metabolic function
into the measure that is usually important for evaluating sequence
complexity. This measure of both the observed data and a conceptual
variable of function jointly can be called Functional Uncertainty (Hf) [17], and is defined by the equation:
H(Xf(t)) = -∑P(Xf(t)) logP(Xf(t)) . . . (1)
where Xf denotes the conditional variable of the given sequence data (X) on the described biological function f which is an outcome of the variable (F).
For example, a set of 2,442 aligned sequences of proteins belonging to
the ubiquitin protein family (used in the experiment later) can be
assumed to satisfy the same specified function f, where f might
represent the known 3-D structure of the ubiquitin protein family, or
some other function common to ubiquitin. The entire set of aligned
sequences that satisfies that function, therefore, constitutes the
outcomes of Xf. Here, functionality relates to the whole protein family which can be inputted from a database . . . .
In our approach, we leave the specific defined meaning of functionality
as an input to the application, in reference to the whole sequence
family. It may represent a particular domain, or the whole protein
structure, or any specified function with respect to the cell.
Mathematically, it is defined precisely as an outcome of a
discrete-valued variable, denoted as F={f}. The set of
outcomes can be thought of as specified biological states. They are
presumed non-overlapping, but can be extended to be fuzzy elements . . . Biological function is mostly, though not entirely determined by the organism's genetic instructions [24-26].
The function could theoretically arise stochastically through
mutational changes coupled with selection pressure, or through human
experimenter involvement [13-15] . . . .
The ground state g (an outcome of F) of a system is
the state of presumed highest uncertainty (not necessarily equally
probable) permitted by the constraints of the physical system, when no
specified biological function is required or present. Certain physical
systems may constrain the number of options in the ground state so that
not all possible sequences are equally probable [27].
An example of a highly constrained ground state resulting in a highly
ordered sequence occurs when the phosphorimidazolide of adenosine is
added daily to a decameric primer bound to montmorillonite clay,
producing a perfectly ordered, 50-mer sequence of polyadenosine [3]. In this case, the ground state permits only one single possible sequence . . . .
The null state, a possible outcome of F denoted as ø, is defined here as a special case of the ground state of highest uncertainly when the physical system imposes no constraints at all, resulting in the equi-probability of all possible sequences or options. Such sequencing has been called "dynamically inert, dynamically decoupled, or dynamically incoherent" [28,29].
For example, the ground state of a 300 amino acid protein family can be
represented by a completely random 300 amino acid sequence where
functional constraints have been loosened such that any of the 20 amino
acids will suffice at any of the 300 sites. From Eqn. (1) the functional
uncertainty of the null state is represented as
H(Xø(ti))= - ∑P(Xø(ti)) log P(Xø(ti)) . . . (3)
where (Xø(ti)) is the
conditional variable for all possible equiprobable sequences. Consider
the number of all possible sequences is denoted by W. Letting the length of each sequence be denoted by N and the number of possible options at each site in the sequence be denoted by m, W = mN. For example, for a protein of length N = 257 and assuming that the number of possible options at each site is m = 20, W = 20257. Since, for the null state, we are requiring that there are no constraints and all possible sequences are equally probable, P(Xø(ti)) = 1/W and
H(Xø(ti))= - ∑(1/W) log (1/W) = log W . . . (4)
The change in functional uncertainty from the null state is, therefore,
ΔH(Xø(ti), Xf(tj)) = log (W) - H(Xf(ti)). (5)
. . . . The measure of Functional Sequence Complexity, denoted as ζ, is defined as the change in functional uncertainty from the ground state H(Xg(ti)) to the functional state H(Xf(ti)), or
ζ = ΔH (Xg(ti), Xf(tj)) . . . (6)
The resulting unit of measure is defined on the joint data and functionality variable, which we call Fits (or Functional bits). The unit Fit thus defined is related to the intuitive concept of functional information,
including genetic instruction and, thus, provides an important
distinction between functional information and Shannon information [6,32].
Eqn. (6) describes a measure to calculate the functional information
of the whole molecule, that is, with respect to the functionality of the
protein considered. The functionality of the protein can be known and
is consistent with the whole protein family, given as inputs from the
database. However, the functionality of a sub-sequence or particular
sites of a molecule can be substantially different [12]. The functionality of a sub-molecule, though clearly extremely important, has to be identified and discovered . . . .
To avoid the complication of considering functionality at the
sub-molecular level, we crudely assume that each site in a molecule,
when calculated to have a high measure of FSC, correlates with the
functionality of the whole molecule. The measure of FSC of the whole
molecule, is then the total sum of the measured FSC for each site in the
aligned sequences.
Consider that there are usually only 20 different amino acids
possible per site for proteins, Eqn. (6) can be used to calculate a
maximum Fit value/protein amino acid site of 4.32 Fits/site [NB: Log2 (20) = 4.32]. We use the
formula log (20) - H(Xf) to calculate the functional information at a site specified by the variable Xf such that Xf corresponds to the aligned amino acids of each sequence with the same molecular function f.
The measured FSC for the whole protein is then calculated as the
summation of that for all aligned sites. The number of Fits quantifies
the degree of algorithmic challenge, in terms of probability, in
achieving needed metabolic function. For example, if we find that the
Ribosomal S12 protein family has a Fit value of 379, we can use the
equations presented thus far to predict that there are about 1049 different
121-residue sequences that could fall into the Ribsomal S12 family of
proteins, resulting in an evolutionary search target of approximately 10-106 percent
of 121-residue sequence space. In general, the higher the Fit value,
the more functional information is required to encode the particular
function in order to find it in sequence space. A high Fit value for
individual sites within a protein indicates sites that require a high
degree of functional information. High Fit values may also point to the
key structural or binding sites within the overall 3-D structure.
11 --> Thus, we here see an elaboration, in the peer reviewed literature, of the concepts of Functionally Specific, Complex Information [FSCI] (and related, broader specified complexity) that were first introduced by Orgel and Wicken in the 1970's. This metric gives us a way to compare the fraction of residue space that is used by identified islands of function, and so validates the islands of function in a wider configuration space concept.
So, we can profitably go on to address the issue of how plausible it is
for a stochastic search mechanism to find such islands of funciton on
essentially random walks and trial and error without foresight of
location or functional possibilities. We already know that intelligent
agents routinely create entities on islands of function based on
foresight, purpose, imagination, skill, knowledge and design.
12 --> Such entities typically exhibit FSCI, as Wicken describes:
‘Organized’
systems are to be carefully distinguished from ‘ordered’ systems.
Neither kind of system is ‘random,’ but whereas ordered systems are
generated according to simple algorithms[i.e. “simple” force laws
acting on objects starting from arbitrary and common- place initial
conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [originally . . . ] external ‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’ [“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65. (Emphases and notes added. Nb: “originally” is added to highlight that for self-replicating systems, the blue print can be built-in.)]
13 --> The Wicken wiring diagram
is actually a very useful general concept. Strings of elements -- e.g.
S-T-R-I-N-G -- are of course a linear form of the nodes, arcs and
interfaces pattern that is common in complex structures. Indeed,
even the specification of controlled points and a "wire mesh" that
joins them then is faceted over in digital three-dimensional image
modelling and drawing, is an application of this principle. Likewise,
the flow network or the flowchart or blocks and arrows diagrams common
in instrumentation, control, chemical engineering and software design
are another application. So is the classic exploded view used to guide
assembly of complex machinery. All such can be reduced to combinations
of strings thsat specify nodes, interfaces and interconnecting
relationships. From this set of strings, we can get a quantitiative
estimate of the functionally specific complex information embedded in
such a network, and can thus estimate the impact of random changes to
the components on functionality. This allows clear identification and
even estimating the scope of Islands of Function in wider
configuration spaces, through a Monte Carlo type sampling of the
impacts of random variation on known functional configurations.
(NB:
If we add in a hill climbing subroutine, this is now a case of a
genetic algorithm. Of course the scope of resources available limits
the scope of such a search, and so we know that such an approach cannot
credibly initially find such
islands of function from arbitrary initial points once the space is
large enough. 1,000 bits of space is about 1.07 * 10^301 possibilities,
and that is ten times the square of the number of Planck-time states
for the 10^80 or so atoms in our obsereved cosmos. That is why genetic
type algorithms can model micro-evolution but not body-plan origination
level macro-evolution, which credibly requires of the order of 100,000+
bits for first life and 10,000,000+ for the origin of trhe dozens of
main body plans. So far, also, the range of novel functional
informaiton "found" by such algorithms navigating fitness
landscapes within islands of funciton -- intelligently specified, BTW
-- seems (from the case of ev) to have peaked at less than 300
bits. HT, PAV.)
14
--> Indeed, the use of the observed variability of AA sequences in
biological systems by Durston et al, is precisely an example of thisan
entity thst is naturally based on strings that then fold to the actual
functional protein shapes.
15 --> Going beyond this, and building on some recent open notebook science work by Torley and Giem
at the blog Uncommon Descent, we may do some integration of the various
metrics of CSI and FSCI, showing how they are based on the idea of bits
beyond a reasonable threshold of complexity to eliminate blind
watchmaker searches as a plausible cause. That is . . .
[VJT in
his original post makes] the following remark, after various
[corrective and simplifying] mods to Dembski’s Chi-metric for CSI; I
insert Eqn numbers:
CSI-lite=-log2(1-(1-p)^(10^150)) . . . Eqn 1,
where p is the probability of the locally observed probability
distribution having the anomalous value or range of values. Where p is
very small, we can approximate this by:
CSI-lite=-log2[(10^150).p] . . . Eqn 2
Following up . . . Dr Giem observed that:
Your math equation for large numbers can be simplified by noting that
(1 + 1/t) ^ t
approaches e as t approaches infinity . . . .
(1 – 1/t) ^ at ~ 1/e^(-a)
Thus if we define D as 10^150, your formula
CSI-lite=-log2((1-(1-p))^(10^150)) . . . Eqn 1
can be very closely approximated by
CSI-lite=-log2(1-(1-p)^D)
=-log2(1-(1-p)^(D*p/p))
=-log2(1-e^(-D*p)) . . . Eqn 3
for D*p much smaller
than 1 (but above zero), we have as a very close approximation (because
the slope of e^x is 1 at x=0) [NB: the slope of e^x at x = 0.01 is
1.01, at x = 0.1 it is 1.105, at 1 it is 2.72], e^(-D*p) = 1-D*p,and so we have, approximately
CSI-lite = -log2(D*p), . . . Eqn 4
which is of course the approximation you gave.
Now, let
us look a bit more closely at that rough (~order of magnitude) then
increasingly good approximation as p falls further and further below
1/D; in light of the Hartley-Shannon view of information as a negative
log metric:
C = – log2(D*p) = -log2(D) -log2(p)
That is, C = I – K, . . . Eqn 5
where I is the [Hartley] info metric for p, in bits.
What we are doing above is specifying a threshold K, beyond which
we are confident in inferring to the relevant info-set being a product
of art not chance and/or necessity . . . .
Define a metric Q, for K-C compressibility [and being functional in a
specific -- reducible to algorithmic or data structure -- way will fit
in such] and st it to 0/1 — or even a sliding scale where 1 is a peak
value, and multiply the above by it, i.e if the constraint is not met
the metric is forced to a zero, and if we use the sliding scale version
it forces a higher and higher complexity threshold as specificity falls:
C’ = [Q] * [-log2(D*p)] . . . Eqn 6
Now, let us revert to the case where D = 10^150, or more helpfully, D = 2^500:
Where C = I – K, . . . Eqn 5
and K = 500 bits
C’ = I – 500 bits . . . Eqn 7
THAT IS, THE C’ METRIC IS BASED ON IDENTIFYING A THRESHOLD BEYOND
WHICH THE SPECIFIC OUTCOME OF LOW PROBABILITY ON A CHANCE HYP, IS
INFERRED AS MAXIMALLY UNLIKELY TO BE THE RESULT OF BLIND WATCHMAKER TYPE
PROCESSES OF CHANCE AND/OR NECESSITY.
16 --> Taking this as a rough but reasonable enough approximation
[which will work even though the Dembski result is not based on the
analytically exact forms], we may now analyse what is going on in the
Dembski metric given under point 8 above:
χ
= – log2[10^120
·ϕS(T)·P(T|H)].
This can be broken up:
χ
= – log2[2^398
·D2·P(T|H)].
Or, as - log2(P(T|H)) = I(T):
χ = I(T) - 398 - K2
Where, K2 has a natural upper limit of about 100 further bits.
That
is the Dembski metric boils down to analysing the informaiton in T as
compared tothe space of possibilites, in terms of how far it is beyond
a variable threhold of about 400 - 500 bits.
17
--> This allows us to tie the various metrics together. For, what is
being done is to assess an information estimate for a functional or
otherwise specified target zone in a config space then estimate how
hard it is to find on a random walk leading to trial and error, from an
arbitrary initial point, as an estimate of the informaiton in it. By
comparing that quantum of informaiton to a threshold that measures a
size beyond which it is credible that such a search would be maxmally
unlikely to succeed, we can then get an estimate of whether or not the
best explanation of the FSCI or CSI being seen is intelligence. (For,
intelligence can clearly make arbitrarily large cases of functionally
specific complex information.)
18
--> In that context, the Durston metric gives us a way to estimate
sizes of islands of function, and information content in a more
sophisticated way than using the Laplace-Bernouilli indifference
approximation, useful as that is. It also provides a
conceptual-analytical apparatus for validating the islands of function
approach.
19
--> And, the simple brute force X-metric identified in 6(a) - (f)
just above, X = C*S*B, is seen as simply imposing a threshold so large
that the specifics of probability models are irrelvant as the search
resources of the cosmos are swamped by the scope of the config space;
which comes at a surprisingly small level: 1,000 bits or 125 bytes or
143 ASCII characters worth of information.
(Those
experienced with programming system controllers will readily
acknowledge that 1,000 bits or 125 bytes is a surprisingly small
quantum for such a program to have to fit in to be reachable by random
walk searches leading to trial and error. So, since the evidence is
that first life requires about 100 k bits or more, and that novel body
plans require 10+ M bitrs, these are not credibly reachable by such
blind watchmaker mechanisms. That leaves intelligence as the best --
and as a known -- cause of that sort of level of FSCI.)
20 --> And so, we have now opened the way to the scientific investigation of:
(i) natural regularities tracing to mechanical forces of lawlike necessity [law],
(ii) naturally variable outcomes tracing to undirected contingency [chance], and
(iii) artificially variable outcomes tracing to directed contingency [design].
So,
let us now take a preview of the case in the main for this note.
For instance, as
Robert Shapiro, a well-known "metabolism first" origin of life [OOL]
theorist, in a
recent Scientific American article, notes of the currently
popular RNA world OOL model:
RNA's
building blocks, nucleotides, are complex substances as organic
molecules go. They each contain a sugar, a phosphate and one of four
nitrogen-containing bases as sub-subunits. Thus, each RNA nucleotide
contains 9 or 10 carbon atoms, numerous nitrogen and oxygen atoms and
the phosphate group, all connected in a precise three-dimensional
pattern. Many
alternative ways exist for making those connections,
yielding thousands of plausible nucleotides that could readily join in
place of the standard ones but that are not represented in RNA. That
number is itself dwarfed by the hundreds of thousands to millions of
stable organic molecules of similar size that are not nucleotides . . .
.
The
RNA nucleotides are familiar to chemists because of their abundance in
life and their resulting commercial availability. In a form of
molecular vitalism, some scientists have presumed that nature has an
innate tendency to produce life's building blocks preferentially,
rather than the hordes of other molecules that can also be derived from
the rules of organic chemistry. This idea drew inspiration from . .
. Stanley Miller. He applied a spark discharge to a mixture of
simple gases that were then thought to represent the atmosphere of the
early Earth. ["My" NB: Subsequent research has sharply undercut this
idea, a point that is unfortunately
not accurately reflected in Sci Am's caption on a picture of
the Miller-Urey apparatus, which in part misleadingly reads, over six
years after Jonathan Wells' Icons of Evolution was
published: The famous Miller-Urey experiment showed how
inanimate nature could have produced amino acids in Earth's primordial
atmosphere . . .] Two amino acids of the set of 20 used to
construct proteins were formed in significant quantities, with others
from that set present in small amounts . . . more than 80
different amino acids . . . have been identified as components of the
Murchison meteorite, which fell in Australia in 1969 . . . By
extrapolation of these results, some writers have presumed that all of
life's building could be formed with ease in Miller-type experiments
and were present in meteorites and other extraterrestrial bodies. This
is not the case.
A
careful examination of the results of the analysis of several
meteorites led the scientists who conducted the work to a different
conclusion: inanimate nature has a bias toward the formation of
molecules made of fewer rather than greater numbers of carbon atoms,
and thus shows no partiality in favor of creating the building blocks
of our kind of life . . . I have observed a similar pattern in the
results of many spark discharge experiments . . . . no
nucleotides of any kind have been reported as products of spark
discharge experiments or in studies of meteorites, nor have the smaller
units (nucleosides) that contain a sugar and base but lack the
phosphate.
To
rescue the RNA-first concept from this otherwise lethal defect, its
advocates have created a discipline called prebiotic synthesis. They
have attempted to show that RNA and its components can be prepared in
their laboratories in a sequence of carefully controlled reactions,
normally carried out in water at temperatures observed on Earth . . .
. Unfortunately, neither chemists nor laboratories were
present on the early Earth to produce RNA . . . .
Shapiro
then acidly observes -- in a remark that inadvertently also applies to his preferred metabolism
first scenario -- that:
The analogy that comes to mind
is that of a golfer, who having played a golf ball through an 18-hole
course, then assumed that the ball could also play itself around the
course in his absence. He had demonstrated the possibility of the
event; it was only necessary to presume that some combination of
natural forces (earthquakes, winds, tornadoes and floods, for example)
could produce the same result, given enough time. No physical law need
be broken for spontaneous RNA formation to happen, but the chances
against it are so immense, that the suggestion implies that the
non-living world had an innate desire to generate RNA. The majority of
origin-of-life scientists who still support the RNA-first theory either
accept this concept (implicitly, if not explicitly) or feel that the
immensely unfavorable odds were simply overcome by good luck.
The
equally famous OOL researcher [and, again, not an ID supporter] Orgel
wrote a January
2008 posthumous rejoinder to Shapiro that is just as telling.
Thus, each of these two distinguished researchers exposes the holes in
the other's favoured model, underscoring that neither evolutionary
materialist school of thought on origin of life has a credible, robust chance
+ necessity only model for the origin of the FSCI in life:
If
complex cycles analogous to metabolic cycles could have operated on the
primitive Earth, before the appearance of enzymes or other
informational polymers, many of the obstacles to the construction of a
plausible scenario for the origin of life would disappear . . . Could a
nonenzymatic “metabolic cycle” have made such compounds available in
sufficient purity to facilitate the appearance of a replicating
informational polymer?
It must be recognized that
assessment of the feasibility of any particular proposed prebiotic
cycle must depend on arguments about chemical plausibility, rather than
on a decision about logical possibility . . . few would believe
that any assembly of minerals on the primitive Earth is likely to have
promoted these syntheses in significant yield. Each proposed metabolic cycle,
therefore, must be evaluated in terms of the efficiencies and
specificities that would be required of its hypothetical catalysts in
order for the cycle to persist. Then arguments based on
experimental evidence or chemical plausibility can be used to assess
the likelihood that a family of catalysts that is adequate for
maintaining the cycle could have existed on the primitive
Earth . . . .
Why should one believe that an ensemble of minerals that
are capable of catalyzing each of the many steps of [for instance] the
reverse citric acid cycle was present anywhere on the primitive Earth [8],
or that the cycle mysteriously organized itself topographically on a
metal sulfide surface [6]?
The lack of a supporting background in chemistry is even more evident
in proposals that metabolic cycles can evolve to “life-like”
complexity. The most serious challenge to proponents of metabolic cycle
theories—the problems presented by the lack of specificity of most
nonenzymatic catalysts—has, in general, not been appreciated. If it
has, it has been ignored. Theories of
the origin of life based on metabolic cycles cannot be justified by the
inadequacy of competing theories: they must stand on their own . . .
.
The
prebiotic syntheses that have been investigated experimentally almost
always lead to the formation of complex mixtures. Proposed polymer
replication schemes are unlikely to succeed except with reasonably pure
input monomers. No solution of the origin-of-life problem will be
possible until the gap between the two kinds of chemistry is closed.
Simplification of product mixtures through the self-organization of
organic reaction sequences, whether cyclic or not, would help
enormously, as would the discovery of very simple replicating polymers.
However, solutions
offered by supporters of geneticist or metabolist scenarios that are
dependent on “if pigs could fly” hypothetical chemistry are unlikely to
help.
In
short, there is a distinct difference and resulting massive,
probability-based credibility gap between having components of a
complex, information-rich functional system with available energy but
no intelligence to direct the energy to construct the system, and
getting by the happenstance of "lucky noise," to that system. Physical
and logical possibility is not at all to be equated with probabilistic
credibility -- especially when there are competing explanations on
offer -- here, intelligent agency -- that routinely generate the sort
of phenomenon being observed.
Howbeit,
this point -- while it does underscore the significance and inherent
credibility of intelligent intervention in the creation of tightly
functionally integrated, complex, information-rich systems -- is
getting a little ahead of the main argument. But, through multiplying
the many similar familiar cases, we can plainly make a serious argument
that FSCI is highly likely to be a "signature" or reliable sign that
points to intelligent -- purposeful -- action. [Indeed, there are no
known cases where, with independent knowledge of the causal story of
the origin of a system, we see that chance forces plus natural
regularities without intelligent action has produced systems
that exhibit FSCI. On the contrary, in every such known case of the
origin of FSCI, we see the common factor of intelligent agency at
work.]
Consequently,
we freely infer on a best and most likely explanation basis [to be
further developed below], that:
But, then, what do we make of -- say -- the case of DNA? Of the origin of the diversity of life?
Or, that of the evidently fine-tuned
cosmos? Does the known absence of human intelligent agents at
the origin of such cases materially alter the balance of our inference?
Why or why not?
B]
Case I: DNA as an informational macromolecule
Now, this is perhaps the most hotly debated case
where we do not directly know the causal story of origin of a complex
information-using system, especially as it makes an empirically
anchored observation that goes to the heart of the dominant secularist,
evolutionary
materialist, modernist
and/or post-/hyper-
modernist worldview held by a critical mass among the elites
of the West (including many theologians!).
However, the force of the inference to design here can be seen from the
title of a textbook I vividly recall often seeing in my old
University's Natural Sciences Library, over 20 years ago now: Functional
Design in Fishes. Accordingly, we see two
contrasting stances:
Dembski: intelligent
design is . . . a scientific investigation into how
patterns exhibited by finite arrangements of matter can signify
intelligence.
Dawkins: biology
is the study of complicated things that give the appearance of having
been designed for a purpose. [Elsewhere, he defines that
systems which only appear to be designed should be
viewed as designoid.]
We can of course immediately observe that --
however many Darwinists may wish to disown him, Dawkins is here
reflecting a pattern that is obvious. Plainly, if something seems to exhibit
FSCI as above, and thus gives the strong appearances of being designed,
we need a very good cluster of evidence and argument to reject the
obvious conclusion that such things appear designed for the excellent
reason that they are.
Equally plainly, an implicit reference to a worldview's claims (and
usually, without a careful comparative
difficulties assessment across live options) just will not do.
So, to address this vexed issue, let us begin with
a summary of the challenge from a
recent review article:
There is an enormous leap from pre-biotic
chemistry to the complexity of DNA replication, protein manufacture and
biochemical pathways existing at the time of the primary divergence of
life. Although progress is being made on the evolution of
some structural components and biochemical pathways, there remain
numerous unsolved ‘chicken and egg’ problems. Margulis (1996a ) said,
‘To go from a bacterium to people is less of a step than to go from a
mixture of amino acids to that bacterium’, yet accumulated evidence
from the physical and biological sciences indicates that advanced life
existed at a very early stage of Earth’s development . . . . Hence the
enigma: an origin of life on Earth appears highly
improbable, an origin elsewhere is highly conjectural. While this
conundrum has been identified in various forms for several decades, its
magnitude has dramatically increased over the last five years as new
constraints are placed on the timing of the primary divergence of the
domains of life. (Shen et al., 2001. Emphases added.)
This article then goes on to speculate on possible
evolution at hydrothermal vents on some other planet (which dodges the
twin bullets of UV radiation and oxygen poisoning of pre-life chemistry
that have put atmospheric and surface pond scenarios to rest for now at
least), then the drifting of life to earth -- "panspermia." That openly
confessed resort to the highly conjectural, unobserved and improbable
is telling.
For a further illustration, we may also observe, in
a
recent PLoS summary article by a science writer:
Give biologists a cell, and they'll give you the
world. [cf Case II below]
But beyond assuming the first cell must have somehow come into
existence, how do biologists explain its emergence from the prebiotic
world four billion years ago? The short answer is that they can't, yet
. . . . While the past half century has seen an explosion of knowledge
about the evolution of life after it began, there has been relatively
little progress in the past half century on how it began—the so-called
origin question . . . . finding the answer to the origin question will
require not only money but also progress in understanding how the most
basic of biological molecules were put together before life began, how
they became organized and self-sustaining, and how they developed into
the membrane-bound cells that are our ancestors. Scientists
have come a long way from the early days of supposing that all this
would inevitably arise in the “prebiotic soup” of the ancient oceans;
indeed, evidence eventually argued against such a soup, and the concept
was largely discarded as the field progressed. But significant problems
persist with each of the two competing models that have arisen—usually
called “genes
first” and “metabolism
first”—and neither
has emerged as a robust and obvious favorite. [Robinson,
2005. Emphases and remarks in parentheses added.]
What is the underlying, unresolved issue? We can
perhaps best get at it by presenting some remarks by Dr Gary Parker of
ICR, as excerpted by Royal Trueman:
A cell needs over 75 "helper molecules", all
working together in harmony, to make one protein (R-group series) as
instructed by one DNA base series. A few of these molecules are RNA
(messenger, transfer, and ribosomal RNA); most are highly specific
proteins. ‘When it comes to "translating" DNA’s instructions for making
proteins, the real "heroes" are the activating enzymes. Enzymes are
proteins with special slots for selecting and holding other molecules
for speedy reaction. Each activating enzyme has five slots: two for
chemical coupling, one for energy (ATP), and most importantly, two to
establish a non-chemical three-base "code name" for each different
amino acid R-group. You may find that awe-inspiring, and so do my
cell-biology students! [Even more awe-inspiring, since the more recent
discovery that some of the activating enzymes have editing machinery to
remove errant products, including an ingenious "double sieve"
system.[2],[3]] ‘And that’s not the end of the story. The living cell
requires at least 20 of these activating enzymes I call "translases,"
one for each of the specific R-group/code name (amino acid/tRNA) pairs.
Even so, the whole set of translases (100 specific active sites) would
be (1) worthless without ribosomes (50 proteins plus rRNA) to break the
base-coded message of heredity into three-letter code names; (2)
destructive without a continuously renewed supply of ATP energy [as
recently shown, this is produced by ATP synthase, an enzyme containing
a miniature motor, F1-ATPase.[4],[5],[6],[7]] to keep the translases
from tearing up the pairs they are supposed to form; and (3) vanishing
if it weren’t for having translases and other specific proteins to
re-make the translase proteins that are continuously and rapidly
wearing out because of the destructive effects of time and chance on
protein structure! [8] [Cf also, Abel and Trevors, here.]
The
proteins involved in this work of the cell are similarly highly complex
and quite specific as to both monomer sequence and folded,
three-dimensional "key- and- lock- fit" structure. That is, as we consider the
nanotechnology of the cell, we are looking at evident, sequence-
perturbation- sensitive functional
finetuning resting on complex information. As
Meyer recently
noted:
By the mid-1950s, biochemists
recognized that . . . [i]n addition to their complexity,
proteins also exhibit specificity, both as one-dimensional arrays
and three-dimensional structures. Whereas proteins are
built from chemically rather simple amino acid “building blocks,” their
function
(whether as enzymes, signal transducers, or structural components in
the cell) depends crucially on a complex but specific arrangement of
those building blocks.13 In particular, the
specific sequence of amino acids in a chain and the resultant chemical
interactions between amino acids largely determine the specific
three-dimensional structure that the chain as a whole will adopt.
Those structures or shapes in turn determine what function, if any, the
amino acid chain can perform in the cell.
For a functioning protein, its
three-dimensional shape gives it a hand-in-glove fit with other
molecules, enabling it to catalyze specific chemical reactions or to
build specific structures within the cell. Because of its three
dimensional specificity,
one protein can usually no more substitute for another than one tool
can substitute for another. A topoisomerase can no more
perform the job of a polymerase than a hatchet can perform the function
of a soldering iron. Instead, proteins perform functions only by virtue
of their three-dimensional specificity of fit, either with other
equally specified and complex molecules or with simpler substrates
within the cell. Moreover,
the three-dimensional specificity derives in large part from the
one-dimensional sequence specificity in the arrangement of the amino
acids that form proteins. Even slight alterations in sequence often
result in the loss of protein function . . . .
Whereas the function of the
protein molecule derives from the specific arrangement of twenty
different types of amino acids, the function of DNA depends on the
arrangement of just four kinds of bases. This lack of a one-to-one
correspondence means that a group of three DNA nucleotides (a triplet)
is needed to specify a single amino acid. [NB: observe that 4
x 4 x 4 = 64, but 4 x 4 = 16 where 16 < 20, so we need
at least and not more than the triplet, usually termed a codon.] In any
case, the sequential arrangement of the nucleotide bases determines (in
large part) the one-dimensional sequential arrangement of amino acids
during protein synthesis.26 Since protein function depends critically
on amino acid sequence and amino acid sequence depends critically on
DNA base sequence, the sequences in the coding regions of DNA
themselves possess a high degree of specificity relative to the
requirements of protein (and cellular) function . . . .
The essentially digital
character of the nucleotide bases in DNA and of the amino acid residues
in proteins enabled molecular biologists to calculate the
information-carrying capacity (or syntactic information) of those
molecules using the new formalism of Shannon’s theory. Because at every
site in a growing amino acid chain, for example, the chain may receive
any one of twenty amino acids, placement of a single amino acid in the
chain eliminates a quantifiable amount of uncertainty and increases the
Shannon or syntactic information of a polypeptide by a corresponding
amount. Similarly, since at any given site along the DNA backbone any
one of four nucleotide bases may occur with equal probability, the p
value for the occurrence of a specific nucleotide at that site equals
1/4, or .25.[30] The information- carrying capacity of a sequence of a
specific length n can then be calculated using Shannon’s familiar
expression (I =–log2p) once one computes a p
value for the occurrence of a particular sequence n nucleotides long
where p = (1/4)^n. The p value thus yields a corresponding measure of
information-carrying capacity or syntactic information for a sequence
of n nucleotide bases.[31] . . . .
Biological organisms also
exhibit specifications, though not necessarily semantic or subjectively
“meaningful” ones. The nucleotide base sequences in the coding regions
of DNA are highly specific relative to the independent functional
requirements of protein function, protein synthesis, and cellular life.
To maintain viability, the cell must regulate its metabolism, pass
materials back and forth across its membranes, destroy waste materials,
and do many other specific tasks. Each of these functional requirements
in turn necessitates specific molecular constituents, machines, or
systems (usually made of proteins) to accomplish these tasks. Building
these proteins with their specific three-dimensional shapes requires
specific arrangements of nucleotide bases on the DNA molecule. [Bold
emphasis and parenthesis on codon triplets added.]
In short, the functioning cell is an enormously
sophisticated, specific and complex, fine-tuned information-carrying
and information- processing system -- vastly beyond anything we have as
yet been able to design and develop. For, it is inter alia a
self-regulating,
self-repairing, self-replicating automaton -- a class
of system we have yet to design and implement with human technologies;
even though John
Von Neumann long ago specified the required subsystems to
achieve this high degree of functionality, indeed, reportedly
predicting that the cell would exhibit this sort of systemic structure,
even before the microbiological revolution of fifty-odd years ago
now.
The cell is also controlled by the information
stored in the DNA, using a
computer language based on three-letter codons that (1) give
procedures, such as: start/stop, and (2) specify amino acid
chains for proteins, the workhorse molecules of the cell. Other
portions (3) provide regulatory functions. Yet others are often called
(4) "junk DNA," as for these no function has as yet been identified
(though in some parts, that
is changing as we speak). Now, of course, DNA is error-prone
and has to be replicated. These critical tasks are achieved by the
cell's molecular machinery; which in turn is manufactured based on
DNA's stored information -- a classic "chicken-and-egg" dilemma, as
Shen et al. remark on. So, the big (and growing) problem faced by
evolutionary materialists is to account for this evident FSCI and
associated molecular processing machinery on the basis of spontaneous
chemistry in plausible prebiotic environments, given the decisive issue
of the adverse
thermodynamics of such environments.
The magnitude of that challenge to make the evident
FSCI in DNA (and thus cells) out of in effect chemical and thermal
noise in hydrothermal vents or some new version of Darwin's prebiotic
soup in a small warm pond, can best be appreciated in light of
observations made at popular level by Dan Peterson in a
recent American Spectator article:
. . . . suppose my computer keyboard had only one
key, and all I could type was:
AAAAAAAAAAAAAAAAAAAAAA
My computer would be incapable of producing contingency.
This is rather like the operation of many physical laws in nature . . .
. The sequence of 22 letters:
KAZDNHF OPZSJHQL ZXFNV
is complex
in a certain sense,
because that exact pattern is highly unlikely to be produced by chance
. . . The total number of unique sequences of [27] characters that
could be produced would be 27 multiplied by itself 22 times, or 27 to
the 22nd power . . . If we . . . generate random strings 22 characters
long . . . [with] a trillion tries every second, the odds would still
be against producing this exact sequence by chance in 20 billion years
. . . .
The third criterion is specification.
Here's
another 22-character sequence:
THE AMERICAN SPECTATOR
. . . . [which] is complex . . . It
is also specified in relation to a pre-existing
standard or function;
in this case, the rules,
spelling, and vocabulary of the English language . . . . In every case
in which we know the "causal story" underlying complex
specified information (writing a sonnet, creating a computer
program, or sculpting Mount Rushmore) we know that it has been produced
by an intelligence. [Source: "The Little Engine That
Could...Undo
Darwinism," Published 8/5/2005. Bold emphases added.]
Then also, in TMLO,
Ch 8, Thaxton
et al (the first technical authors in the modern Design framework) show
-- cf. Appendix 3 below
-- that the concept, complex,
functionally specified information, emerged organically from
the natural development of OOL studies, through the work of Polanyi,
Orgel, Yockey and Wickens in particular. CSI,
or, as I have expressed its relevant subset, FSCI, is therefore NOT an
alien imposition on OOL studies by "Creationists," whether hiding in
"cheap tuxedos" or otherwise. Indeed, in this context, Mr Dembski's
work is best understood as
a serious and arguably at least partly successful attempt to give
mathematical formalism and definition through a
probabilistic-statistical model tied to information theory, to an
existing concept. Indeed, as the cite a the head of this page shows,
that concept was first seriously
broached in Western culture, as early as ~ 50 BC, by Cicero.
Irreducible
Complexity, Behe's
concept [which builds on Darwin's
suggestion for an empirical test of his scheme, cf. the next section below],
is in turn a subset of FSCI,
relating to systems made up from components, containing a core fraction
that is such that removal of any of these critical components disrupts
its proper
function. (This is very familiar from say, the experience of anyone who
has experienced breakdown of a car, or a PC or a television set due to
failure of just one key component. in biology, genetic knockout studies
work by knocking out one genetic component at a time and seeing what
breaks down. E.g., by such studies Scott Minnich
-- as
he testified to at Dover -- reports that he has empirically shown that
the bacterial flagellum is irreducibly complex. [NB:
observe remarks here
as well on informational
redundancy in the genome and its potential impact on such
studies.)
The relevance of this lies in the
observation, ever since Polanyi and Yockey et al that DNA
is in fact a functional, complex, digitally encoded, data string based
on chains of nucleic acids. This observation was
followed up by Thaxton,
Bradley and Olsen [TBO] in the early 1980's; then
thereafter by the Design Theory movement that emerged
from their breakthrough 1984 technical level book, The Mystery of
Life's Origin [TMLO]. For, as just noted, highly
complex informational macromolecules control the core functions of
life; constituting a communication system with digitally coded messages
that are functional, specified and complex. As Peterson therefore goes
on to note:
The DNA in genes and chromosomes . . . makes up the
blueprint for life . . . There are four potential bases for any "slot"
in the sequence, often abbreviated by the letters A, C, G, and T . . .
. Like computer code or language, the sequencing of those four bases is
contingent -- the nucleotides don't bond with
the nucleotides next to them in a necessary, repeating sequence. DNA
sequences are also complex. In the human genome
(that is, in the DNA present in each of our cells) there are about
three billion such slots. The amount of information in the DNA of every
human cell is greater than the information in all of the volumes of the
Encyclopedia Britannica. Most importantly, DNA
sequences in living things are specified in
relation to a function: building a human, animal, or plant that can, at
minimum, survive and reproduce.
In short, on the face of it, there is an excellent
case that DNA [and other molecules of life] bear the characteristics of
complex, functionally specific messages beyond the credible reach of
undirected chance forces and blind natural regularities, and indeed
vastly compound the point by having these function together in an
integrated entity, the cell. That immediately raises what is in several
quarters a very unwelcome inference: DNA is probably the
product of a purposeful, intelligent agent, i.e. it is the product of
design.
It is also
worth pausing to further cite Peterson's remarks on a way to set a
"reasonable" yardstick for rejecting chance explanation through
improbability, as has been proposed by William Dembski; especially as
this is often a focus for misunderstanding. For, we can move beyond
simply hypothesising a supercomputer that can make a trillion tries a
second and lasts for the lifetime of the cosmos, to create a more
natural bound for "improbability":
Dembski
has formulated what he calls the "universal
probability bound." This is a number beyond which, under
any
circumstances, the probability of an event occurring is so small that
we can say it was not the result of chance, but of design. He
calculates this number by multiplying the number of
elementary particles in the known universe (10^80) by the
maximum number of alterations in the quantum states of matter per
second (10^45) by the number of seconds between creation and when the
universe undergoes heat death or collapses back on itself (10^25). The
universal probability bound thus equals 10^150, and represents all of
the possible events that can ever occur in the history of the universe.
If an event is less likely than 1 in 10^150, therefore, we are quite
justified in saying it did not result from chance but from design.
Invoking billions of years of evolution to explain improbable
occurrences does not help Darwinism if the odds exceed the universal
probability bound. [Link added. Cf. Dembski's more technical
discussions that are available online here
and here.
The related philosophical challenge due to Hume and his current
followers, including especially Elliott Sober, is discussed here.]
For instance, if I type out a paragraph of 120
characters, all in upper case English Alphabet letters, without spaces
or punctuation [so-called scriptua continua, as
the oldest manuscripts of the New Testament often use], then the set of
all possible strings is: 26^120, which is about 6.26 * 10^169. If I
were to factor in the usual set of 128 ASCII characters, there would be
about 7.33 * 10^252 possible random strings of 120 characters. In
short, once we specify it, it would be most improbable to reproduce any
given 120-character string of characters merely by chance. So, when we
see, not an arbitrary nonsense string -- i.e. any random set of keys
would do: jnfvjwqyue2bfhaewfh . . . . , or:
l,fchjfvcyodyflxpd87r0ejkf . . . . , or: bfytfdiidtclsp;strfhid
. . . . etc. -- but rather specific text in English, we
have good reason to infer that such is an intentional message, not a
matter of the famous million monkeys hitting keyboards at random for a
million years, or the like.
CASE
STUDY -- of Monkeys and keyboards (updated): Updating this
tired C19 rhetorical counter-example used by Darwinists, take a million
PC's, with floppy drives modified to spew magnetic noise across the
inserted initially unformatted disks, perhaps using zener diode noise
circuits or the like source of guaranteed random noise. Then once every
30 seconds for a year, run the noise circuit, and then test for a
formatted disk with 500 or more bits of data in any standard PC format.
We get thereby 10^12 tests per year. Continue for the lifetime of the
observed cosmos, i.e. 10^25 seconds or so, giving 10^37 tests. Is it
credible that we will ever get a properly formatted disk, or thence a
message at this reasonable threshold of complexity by chance?
[NB:
The 500-bit threshold is chosen as 2^500 ~ 10^150, and because it is
credible that the molecular nanotechnology of life has in it orders of
magnitude more information than that, judging by the 300 - 500,000
4-state elements (equivalent to 600,000 to 1 million 2-state elements)
in the DNA code of the simplest existing unicellular life forms. Also,
observe that we are here putting a far more realistic threshold of
accidentally generated functional complexity than we see in the often
met with cases of designed genetic algorithms that
carry out targetted searches, step by step promoting increments towards
the target. Random walk-type searches, or searched reducible to that,
in short, only "work" when the searched space is sufficiently richly --
and implausibly [Cf here Denton's telling discussion in his classic 1985
Evolution, a Theory in Crisis, ch 13] -- populated by islands
of functional complexity.]
Of course, in some cases, code-makers deliberately
produce nonsense-like strings, but that can be recognised once an
appropriate receiver (and its decoder) can decode them. We can rule out this situation,
without loss of force on the main point: first, receive and decode your
message, then discuss whether it comes from
noise or intelligence. In
short, we do not need to have a
"super-definition" of functionally specified complex information and/or
an associated super-algorithm in hand that can instantly recognise and
decode any and all such ciphers, to act on a case by case basis once
we have already identified a code.
This is of course another
common dismissive rhetorical tactic. Those who use it should consider
whether we cannot properly study cases of life under the label
"Biology," just because there is no such generally accepted definition
of "life." In any case, precise definitions that identify all
and only cases of a given entity X, depend for their credibility on the
prior fact that we recognise that there are cases of X, and cases of
NOT-X, which the definition reliably separates. That is, intuitive,
conceptual recognition on a case by case basis is prior to precising
definition.
DNA, in any case, is already long since
[partially] decoded, so we can turn back from this rabbit trail to the
material issue: how do we account for what we do know about
this case?
Now, too, DNA strings take on four values in any
position, G/C/A/T [and in odd cases, U], with certain constraints.
Thus, there is an apparent coded
message, where three letters in sequence correspond to
certain amino acids in protein chains. We also see in real cells DNA
strands with 500,000 or so for the simplest functional cells; up to
3,000,000,000 or more base pairs, for species such as man -- plainly a
functional and complex coded message.
But, log manipulations on a pocket calculator will
soon show that just 500,000 four-state elements have 9.9 * 10^301,029
possible combinations, and the constraints on on sequences do not bring
an exponent of over 300,000 down below the threshold, 10^150.
For
instance, let us assume that only 10% of the code in the bacteria with
DNA strands at the lower end of the range is functional, and that at
each minimally contingent functional point, there is a pair of nucleic
acids, thus, that we have a binary sequence with 25,000 positions.
[That is, in effect at each point, we assume minimal contingency: two
choices not four.] The number of possible states for such a digital DNA
string of data would then be: 2^25,000; or, ~ 5.62 * 10^7,525. Now,
too, it is credible that here have been less than 10^500 DNA-based life
forms in our cosmos, so the functional states (which would cluster
species by species) would be impossibly sparse in the resulting
"DNA-space." (To give an idea, we observe perhaps 10^80 atoms in the
cosmos, and if every atom were to become another whole universe of
similar scale, we would then have 10^80 universes of 10^80 atoms each,
giving 10^160 atoms overall. We would then have to multiply the number
of atoms similarly four times over again to get to 10^5120 atoms, which
is still vastly below the number just given.) Finally, on this, we note
that knockout studies reportedly lead to disintegration of life
function when the remaining active DNA in such "simple" bacteria is ~
360,000. NB: For a more elaborate discussion [which in particular
addresses "chance-plus" scenarios and shows in summary why they are
unsatisfactory], cf. here,
esp. from p. 239 on.
This point may be extended by recognising that the observed genome
reportedly currently ranges from about 160 - 500,000 four-state
elements up to about 130 - 670 *10^9 such elements. We may
therefore look at an illustrative case study:
CASE STUDY: on getting to "islands" of bio-functionality in the "digital genome ocean": In effect, since genomes commonly
range from about half a million to three to four billion elements, we
may consider the genome as constituting a configuration space based on five-state digital elements [G, C, A, T or 0,
this last meaning (a) the relevant genome has no digit at the place in
question [the real genome has truncated], or (b) while it may have a
physical digit, it is non-functional, i.e.
so-called "junk"]. Every genome thus would be of nominal length
700*10^9 elements, per the more or less upper limit of observed
genomes. That way,
we may display all actual and possible genomes in a common digital configuration space.(Conceptually,
for the purposes of visualising the configuration space,
we can view the DNA string as if it formed a "loop," so that there
is no one preferred location or direction of reading it, even though we
may [again in our imaginations] tag some digit as the first for each
string so that we have a reference point for uniquely identifying each
possible loop. Similarly, for convenience, we may imagine that the
resulting space fans out from the "zero-length genome" in an arc, with
the radius from the origin at any given cell being proportional to the
string-length of the physical genome. Similar genomes are, of course,
clustered together.)
Using
this model,
we may now view each configuration as occupying one cell [pixel], so
that the genomic space is imagined as a vast digital "Pacific Ocean,"
with an overall configuration space of 5^[700*10^9] ~ 1.63
*10^489,279,003,035 states or cells. (NB: There are a "mere" 10^80 or
so atoms
in the observed universe, which as Dembski calculates, would take up ~ 10^150 quantum states across its typically estimated lifetime.)
Within
that vast, fan-shaped imaginary mathematical ocean, every possible genome from 0 elements up to 700 * 10^9
elements can be mapped as sitting in the sea of non-function, or on
an island of functionality. Each of
these islands can be imagined as having a shoreline of minimally functional configurations, ranging up to an
inland range of hills of increasingly effective then ultimately locally
optimal bio-functionality at its peaks. (In short, each island corresponds to a functional body plan, with room for enough variation to take in every possible individual functional expression of that plan.)
Within that digital Pacific, we will expect to observe islands and perhaps archipelagos or even continents of bio-function,
corresponding to observed and possible bio-forms. Indeed, they correspond to every past, existing and even possible individual cell-based lifeform. [Of
course, if we observe yet longer genomes, we can easily enough extend
the space beyond 700 billions, but that would simply further underscore
the force of the point.]
The
first challenge of abiogenesis is to start from the 0 square [genome
length zero], and in a plausible chemical environment, (i) get to a viable
and sustainable prebiotic soup with the requisite monomers in it, then (ii) move to the first islands of
function. (For the moment, we will simply assume for the sake of our
argument that once a proto-genome reaches the shores of a viable
island, it may then proceed through hill-climbing processes such
as "random variation" and "natural selection" [i.e. culling based on
differential average reproductive success], to move to the mountains of
peak performance in that bio-functional niche.)
The
immediate problem is that the first such observed islands are of order
100,000 - 1,000,000 base pairs; and in a context where the organisms at
the lower end are in effect typically dependent on more complex life
forms to make life components they cannot. The relevant 1 million
chain-length sub-space has about 1.010 * 10^698,970 configurations,
which is again a very large number, which will easily swamp the search
resources of the observed cosmos. Even if we take 100,000 elements as a
working lower limit, that puts us at 1.001 * 10^69,897; still well
beyond the available search resources of the observed cosmos. In
effect, if an inflatable but slowly
leaking raft [i.e. there are finite, exhaust-able search resources . . . ] were to drift from
the zero-length cell in the digital Pacific at random until it grounds
on an island of function or sinks due to a loss of air, it would be
maximally improbable for it to reach a shore before sinking.
Why is that so?
First,
biofunction is observed to be code based and specific, i.e. it is
vulnerable to perturbation. For instance, three of the 64 possible
three-letter codons code for STOP. So, immediately, if we form a
substring of three DNA letters at random, the odds are just under
5% that they will be a stop codon. This alone means that in a prebiotic
scenario -- even ignoring the basic thermodynamics challenge of
climbing up the energy and complexity hill to spontaneously synthesise
the monomers in adequate concentration (itself a major challenge, cf. Appendix
1) -- randomly formed codon sub-strings will tend to be too short to be functional in
coding for a protein. That means that functional genomes must be quite
rare in the configuration space, even in the initial short-genome
corner. For instance:
.
. . consider a hypothetical genome that requires 100
"necessary" proteins, each with just 100 residues, using
altogether 10,000 codons, or 30,000 DNA base pairs. This will require
10,000 codons without an accidental stop in the wrong place, to get the
required complement of proteins. The fraction of such 30,000-length
genomes that would not be truncated by wrongly placed stop
codons is (61/64)^10,000 ~ 1 in [3 * 10^208]. This in itself
would make it maximally unlikely that we would get by chance
concatenation of DNA elements to a single such minimally functional
genome; on the gamut of our observed universe across its typically estimated lifetime. (Nor will autocatalysis of RNA molecules in a hypothetical RNA world, get us to bio-functional, protein-making DNA codes.)
Next,
to get to actual bio-function is itself a challenge.
For, the DNA molecule is a code
storing component in cell-based life. It must inter alia code for
proteins that must fold to specific shapes and have various appropriate
functional groups dependent on the overall structures of the protein
chains. To express that code, DNA requires a large number of associated
molecules to put it to work. That is, as we observe in the
cell, we require a rather carefully organised cluster of complex
molecular scale machines, that work together in close coordination to
produce biofunction. Without the molecules in the correct proximity,
arrangement and order of operation, the step by step -- i.e algorithmic
-- processes of life will not work. To assemble and preserve such
molecules in the correct proximity is also a further major challenge;
again, easily beyond the available search resources of our observed
cosmos. In short, to get to just having the molecules for observed life
function, we are already iterating the search space problem, vastly
compounding its impact.
Worse, life function is observed to be based on algorithms and codes;
which constitute functional, specific, complex information. Such algorithms and codes are observed to
have but one empirically observed source: intelligent agents. (And, this is apparently for the
excellent reason that chance processes run into the same isolated islands of function in a sea of non-functional configurations
challenge.) Genetic algorithms and the like are not counter-examples,
as they are in effect rather constrained hill-climbing searches, within
a wider program that is already intelligently designed and functional.
Often, the target is pre-specified and closeness of approach to the
desired target is rewarded; i.e. they are premised on exactly the sort of
foresighted purposiveness that Darwinian evolutionary processes, on
pain of transformation into intelligently designed processes, cannot have.
After the origin of life hurdle, we may then briefly look at the challenge of breaking out into the wider genome space.
For
that, starting from the low-length genome corner above, we have to
generate the required considerably larger genomes required to
sustain novel major body plans at, e.g., the kingdom and phylum level.
This arguably initially requires moving from maybe 1 million to ~ 100
million base pairs. The 100 million base pair sub-space has in it about
2.714 * 10^69,897,000 configurations; that is, the search space problem
has further exploded.
Thus,
it is reasonable to at least consider whether the natural, chance +
necessity causal factors that are often held to drive the origin and
body plan level diversification of life are inadequate to explain the
origin of such functionally specified complexity. Especially, given the
routinely observed source of functionally specified, complex
information: intelligent agents.
To further see what such "beyond imaginable" numbers mean, let us for the
moment turn to the related point that most molecules of life show a
certain "handedness," similar to the mirror-image shapes of left and
right hands, and also we know that the resulting geometry is a critical
issue in bio-functionality. So, as we may see in a
recent Royal Society paper by Martin and Russell
on the subject, "On the origins of cells: a hypothesis for the
evolutionary transitions from abiotic geochemistry to chemoautotrophic
prokaryotes, and from prokaryotes to nucleated cells," Section 6:
none of the [current abiogenesis] models
have proposed a solution to one of the more vexing
origin problems: chirality. Three-dimensional molecules such
as sugars and amino acids can exist in two mirror-image forms, like
left and right hands (chiros is Greek for hand). Any nonbiological
synthesis of such molecules, as would have occurred before life arose,
produces equal amounts of each type. Nonetheless, modern
cells use exclusively left-handed amino acids and right-handed ribose
sugars, and interference from the wrong kind shuts down
biological reactions. How could chiral life arise
in the presence of so much interference?
It's a serious problem, Orgel admits, but not an
overwhelmingly serious one. Orgel suggests that one of
several possible solutions may be chance, a frozen
accident that brought together, and kept together, molecules of the
right chirality. Such an accident is perhaps not so unlikely,
says Martin, who calculates that a mixture of every possible left- and
right-handed combination of a 25 amino acid peptide (amino acid chain)
would weigh 25 kilograms. Any smaller sample is imperfect, he says.
[Emphases added.]
COMMENT: Here, the attempt is
made to exhaust the possible combinations of 25-acid-length peptides
[protein components], to credibly arrive at the required bioactive
components relative to life as we know it. This is of course
essentially the project of shuffling though the available possible
states to get to those that "work" at random, as Dembski in effect
discusses as the threshold for complexity. Now, also, since Glycine is
achiral, we have 39 possible monomers at each stage, and also from
empirical studies of bond frequency for such amino acids only half of
the bonds might be the "right" kind. Taking in the first only we are
looking at 39^25 ~ 5.99*10^39 possible molecules, ~ 9.94*10^15 moles.
(If we factor in bonding, that takes us to something like 78^25
possible molecular configuration states for our "25 kg ball.")
But, something is evidently and tellingly wrong
with the "25 kg" estimate made by Martin. For, if we use a simplistic
estimate of 100 AMU per amino acid monomer [4*C = 48, N = 14, 2*O = 32,
just for starters, ignoring H], we see that a 25-acid molecule should
have molecular mass ~ 2,500 AMU, thus molar mass 2,500 g [similar to
the estimates used by TBO in TMLO]. But then, 9.94*10^15 mol would
weigh in at ~ 2.49*10^16 kg. 1,000 kg is a tonne, so we are looking at
~2.5*10^13 tonnes, a rather large quantity and not one credible for a
spongy mass of FeS at an undersea hydrothermal vent in a primordial
ocean -- the suggested context for abiogenesis through chemical
evolution being discussed. And, the issue compounds itself rapidly when
we go to the other molecules needed to get life going, all of which
have to be right geometrically and sequentially -- and in the right
proximity, for biochemical activities to work. So, there are serious issues on the
possibility of chemical evolution, which is antecedent to
biological evolution. ( In turn, biological macroevolution meets
similar difficulties of information generation other than by
intelligent processes, as is ably discussed by Meyer
and Lönnig,
in two recent peer-reviewed
papers.)
In short, DNA as observed in life forms, is plainly
comfortably complex beyond the Dembski-type bound of sets of states
reachable by random search strategies in the scope of matter and time
that cosmologists often give for the observed universe. Plainly, then, DNA
is a credible candidate for an observed bio-functionally specified,
complex message from an intelligent agent. The same holds
therefore, for the rest of the core machinery of the cell.
Observe, also, that we have not proposed an
identity for such an agent, only inferred that it is
credible that DNA
be viewed as a message-entity; which is best explained through the
logic of explanation as a signature of intelligent agency. Such an
explanation is not a science-stopper either: e.g. it invites the onward
project of reverse-engineering life, and forward engineering systems
that take advantage of what we so discover in the information systems
of life. For that matter, as with all scientific reasoning,
it is defeatable, thus provisional: i.e., subject to correction in
light of further empirical findings and logical/mathematical analysis.
Perhaps
even more interesting is the observation by Hurst, Haig and Freeland,
that the actual protein-forming code used by DNA is [near-] optimal. As
Vogel reports (HT: Mike Gene) in the 1998 Science article "Tracking the History of the Genetic Code," Science [281: 329]:
. . . in 1991, evolutionary biologists Laurence
Hurst of the University of Bath in England and David Haig of Harvard
University showed that of all the possible codes made from the four
bases and the 20 amino acids, the natural code is among the best at
minimizing the effect of mutations. They found that single-base changes
in a codon are likely to substitute a chemically similar amino acid and
therefore make only minimal changes to the final protein.
Now [circa 1998] Hurst's graduate student Stephen Freeland
at Cambridge University in England has taken the analysis a step
farther by taking into account the kinds of mistakes that are most
likely to occur. First, the bases fall into two size classes, and
mutations that swap bases of similar size are more common than
mutations that switch base sizes. Second, during protein synthesis the
first and third members of a codon are much more likely to be misread
than the second one. When those mistake frequencies are factored in,
the natural code looks even better: Only one of a million randomly
generated codes was more error-proof. [3] [Emphases added]
 |
Fig
B.1 The actual standard DNA code is in the top one-millionth or so of a random
sample of codes, in capacity to buffer against deleterious mutations. (Adapted, Freeland et al, 2000. TIBS 25: 44 - 45. [HT: MG.]) |
As
the pseudonymous Mike Gene then summarises, when various biosynthetic
pathway restrictions [the codes seem to come from families sharing an
initial letter] and better metrics of amino acid similarity are
factored in, it is arguable that the code becomes essentially optimal.
So, he poses the obvious logical question:
. . . the take home message from these studies, and several others, is that nature's code is very good at
buffering against deleterious mutations. This theme nicely fits with
many other findings that continue to underscore how cells have layers
and layers of safeguards and proof-reading mechanisms to ensure minimal
error rates. Thus, contrary to Miller's assertion, the "universal code"
is easily explained from an ID perspective - if you have designed a
code that is very good at buffering against deleterious mutations, why
not reuse it again and again?
In
short, not only is the DNA code a code that functions in an algorithmic
context, but of the range of possible code assignments, the actual one
we see seems very close to optimal against the impacts of random
changes. Further, the codons themselves fall into a highly structured pattern, as "amino acids from the same biosynthetic pathway are generally assigned to codons sharing the same first base." [Taylor and Coates 1989, cited, Freeland SJ, Knight RD, Landweber LF, Hurst LD. 2000 in "Early fixation of an optimal genetic code." Mol Biol Evol 17(4):511-8. (HT: MG.)] That is, the DNA code itself is significantly non-random in how it assigns base pairs to amino acids.
(But also, I must note that such suggests an inference: (a) the coding assignments are not driven by the mechanical necessity of the underlying chemistry of chaining either nucleic acids or proteins, and (b) they are not a matter of random chance. An observation of (c) a structured coding pattern tied to the one-stage-removed chemistry of synthesis of the amino acids that are components to be subsequently chained to form proteins therefore strongly supports that (d) the code is an intelligent act of an orderly-minded, purposeful designer.
For, of the three key causal factors, if neither chance nor necessity
is credibly decisive, that lends itself to the conclusion that
intentional choice (here, tied to a prior component assembly
stage!) is at work. In short, intelligent design.)
Gene tellingly concludes:
. . . there are two very good (and obvious) reasons for a designer to have
employed the same code in bacteria and eukaryotes: 1) The code is
extremely good at preventing deleterious amino acid substitutions and;
2) the shared code allows for the lateral transfer of genetic material
and facilitates symbiotic unions. That Miller thought ID incapable of explaining the code, and Pace thought the shared code proved the common descent of bacteria and eukaryotes, only shows how an a priori commitment to non-teleological explanations creates a large intellectual blind spot.
Once these and other
reasons why DNA is a credible candidate for a real message from an
intelligent agent are on the table, we may then briefly address the
usual objections:
- Denying the validity of the sort of probability
calculation used, e.g., by proposing that a fairly high fraction of
random short RNA strands show catalytic effects. Often, this is joined
to the idea that primitive life was so much less complex that it could
have started by chance, e.g. in a so-called RNA world; which then
builds up on itself until, we see life as we know it. (However,
this has of course not as yet been observed. Second, the implied highly
improbable spontaneous origin of the DNA's language and codes for
proteins by random processes is simply passed over in silence. Also,
this does not address the core issue: the creation of the OBSERVED
complex, functional information system. For, DNA is based on a code
stored in a class of molecules that are not just chemically catalytic,
but drive a step-by-step controlled processing system that carries out
the observed biochemical pathways of life using a large cluster of
molecules that are themselves coded for in the DNA. (Cf. a special
issue of the Journal Cell, on the observed cellular
machines, linked here.)
In short, this first objection is a resort to faith in unobserved,
speculative pathways to life that dodges the twin thermodynamics
and origin of information
challenges. Besides, the islands of function in genomic space issue above is NOT a direct probability calculation, but a search-space and search resources exhaustion challenge.)
- Inference to design is inherently "unscientific,"
as this inference violates the rules of science. In short, science is here
being redefined as so-called "methodological naturalism." More or less,
this boils down to claiming that science is the best evolutionary
materialist account of the cosmos from hydrogen to humans.
That is, it makes conformity to the theories/models of cosmological,
then chemical, then biological then socio-cultural evolution the test
of whether or not an idea is scientific. (This obviously and
massively begs the question, and
it is inaccurate to the history of modern science, which
originated in C16 - 17 Europe through men who had been shaped by the
Judaeo-Christian thought world, and therefore sought to understand the
orderliness of the universe as God's handiwork: "thinking God's
thoughts after him." Science,
is better understood as an open-ended, provisional approach to
knowledge through observation, theorising, experiment and debate among
the community of the informed. As such, it has no proper basis for
ruling out ahead of time any of the three generally known sources of
cause: chance, regularities of nature, agency. [Also cf.
AiG's remarks
on the rules of science.])
- Inference
to design is unjustified because it is
untestable, unless one has independent knowledge of the designer and
what such an agent is likely to do. (This objection would
carry greater force if it were not now so obviously a case of special
pleading in the teeth of the implications of detecting FSCI as is
discussed above. But also,
thanks to Elliott Sober's confession, in
a footnote in his 1999 Presidential lecture to the American
Philosophical Association, "Testability," we see that this objection is
more rhetorical than substantial: “To infer watchmaker from watch, you
needn’t know exactly what the watchmaker had in mind; indeed, you don’t
even have to know that the watch is a device for measuring time.
Archaeologists sometimes unearth tools of unknown function, but still
reasonably draw the inference that these things are, in fact, tools.”
In short, we CAN properly infer to design from its objective traces in
the entities being observed, without having to refer to independent
knowledge of the designers, their intent and characteristics. So as
long as, say, the search for extraterrestrial intelligence, SETI, is
held to be scientific, the objectors are guilty of selective
hyperskepticism. At a more serious level, this objection is
based on arguing for Bayesian rather than Fisherian reasoning about
using probability to eliminate chance hypotheses. But in fact, as Dembski
summarises, the former predominates in real-world praxis: we
set up a chance hypothesis as the null, then eliminate it if the
observed cases fall into the rejection regions at some reasonable
threshold. And for excellent reason: the latter raises a string of
issues that in the end reveal its frequent impracticability and
dependence on the former. Dembski's universal probability bound, of
course, is a case in point of a "reasonable" yardstick for a rejection
region -- one with greater warrant than the usual 0.05 or 0.01
thresholds used in the social sciences.)
- Expanding the assumed scope of the universe beyond
what we observe. In effect, it is claimed that (1) the currently
observed universe is an arbitrarily restrictive scope, and (2) probably
there is an in effect [or even actual] infinite
wider universe as a whole, and (3) we are in that sub-universe that
happened to be such that life emerged. In short, the speculated scope
of the universe as a whole -- which has not been observed,
let us emphasise -- is so large that it swamps out the odds above.
(Notice the resort to faith in unseen proposed realities. More to the
point, the Dembski-type bound is a measure of improbability that
asserts that beyond a certain reasonable point, it is more credible to
infer to intent than to spontaneous origin to explain functionally
specific information, i.e. the threshold of "complexity." It is a
matter of inconsistency and selective
hyperskepticism to on the one hand routinely infer to design
on encountering FSCI in a great many communicative contexts where the
probabilities are similar [cf. above],
but then insist that on the issue of DNA origin, the best answer "must
be" that the universe as a whole is wider than we thought. Underneath,
lurks the issue of worldviews, and the inference to a speculative,
wider universe to keep evolutionary materialist views going. But, on
such a metaphysical question, the proper approach is to use comparative difficulties
across ALL live options. In short, the Dembski bound is an excellent
filter of the point where the discussion crosses over -- often
unacknowledged -- from observationally controlled science to
metaphysical speculation!)
- There are underlying, as yet undiscovered, laws of
nature that force the emergence of life, i.e. life is not a random
chance-driven event. That is, life is not contingent, so probability is
irrelevant. (Notice the resort to faith in unobserved, yet to
be discovered laws of nature. In effect, this concedes the point, and
it raises interesting implications: where did such a strange law of
nature come from? That leads to the issue under Case III below.)
Summarising, the first of these
of course simply fails to address the issue, by substituting a simpler
and arguably irrelevant, fundamentally unobserved model for empirically
anchored science. The second and third
attempt to rule design out of court by unjustifiably changing the rules
of science, taking it out of the context of being an open-ended,
open-minded, empirically controlled search for truth. At a more serious
level, the third would also substitute a more difficult approach that
is dependent on the one it objects to, as a basis for eliminating
chance hypotheses. The fourth is an outright resort
to speculative metaphysics on the nature of the cosmos as a whole, not
science as such; for science must plainly be accountable to
observations -- and the proposed infinite array of
subuniverses model is plainly not so constrained. But, if we are
constructing philosophical worldviews, the proper method is comparative difficulties:
putting all the major live options on the table and
seeing which is more factually adequate, coherent and powerful as an
explanation. Once that is done, it is an obvious point that design is
at least as credible as the unobserved quasi-infinite universe: we
observe what intelligence does all the time, and we here have a case of
a highly complex, biofunctionally specified molecule and associated
molecular information processing system. The fifth,
is simply a promissory note, as yet unredeemed after 50 years of
active, heavily funded research in this and linked fields. It also has
perhaps surprising implications, i.e. it immediately raises the
question: why would the laws of nature force the origin of
life on planets with the appropriate chemical and physical conditions?
These last two objections therefore also bleed over
into Case III below, but
first let us pause and address an extension of Case I:
C]
Case II: Macroevolution and the Diversity of Life
Here, we move from the origin of life to its
diversity as observed in the current world and as is generally inferred
from the fossil record and geological dating schemes. (It is not my
purpose here to challenge the generally accepted dating systems and
their "standard" chronology. [Cf. ICR's summary remarks here
for a start if you are interested in that secondary issue. Also cf.
Wiens' remarks here
from the Old Earth Creationist view, as well as J P Moreland, here,
on the related Bible interpretation issues. The YEC view is summarised here,
in a report on a debate:
Ross/Lisle.] Nor is it my purpose to attempt to refute
that at some significant level macroevolution may have happened across
time. Only, let us take time to rethink the credibility of the claims
made by the predominant school of thought on the origin of life.)
The underlying issue to be addressed, then, is that
there is reason to infer that the observed and inferred diversity
cannot credibly be accounted for on the basis of a fundamentally random
process of genetic mutation and a selection filter. For, there is a
need to generate FUNCTIONAL and highly complex genetic information that
works in an integrated organism by chance processes in the context of
blind natural forces. The reason for that, is the observation that this
requires FSCI, and the claim that such can be generated through
essentially random processes, is not credible. So, it is useful to
first cite from Lönnig's
recent [2004] paper on "Dynamic genomes, morphological
stasis, and the origin of irreducible complexity."
Speaking of the horseshoe crab as an organism that
seems to have been morphologically static across 250 million years of
fossil record and on into the contemporary world, he notes:
examples like the horseshoe crab are by no means
rare exceptions from the rule of gradually evolving life forms . . . In
fact, we are literally surrounded by 'living fossils' in the present
world of organisms when applying the term more inclusively as "an
existing species whose similarity to ancient ancestral species
indicates that very few morphological changes have occurred over a long
period of geological time" [85] . . . . Now, since all these "old
features", morphologically as well as molecularly, are still with us,
the basic genetical questions should be addressed in the face of all
the dynamic features of ever reshuffling and rearranging, shifting
genomes, (a) why are these characters stable at all and (b) how is it
possible to derive stable features from any given plant or animal
species by mutations in their genomes? . . . .
A first hint for answering the questions . . . is
perhaps also provided by Charles Darwin himself when he suggested the
following sufficiency test for his theory [16]: "If it could be
demonstrated that any complex organ existed, which could not possibly
have been formed by numerous, successive, slight modifications, my
theory would absolutely break down." . . . Biochemist
Michael J. Behe [5] has refined Darwin's statement by introducing and
defining his concept of "irreducibly complex systems", specifying: "By irreducibly
complex I mean a single system composed of several
well-matched, interacting parts that contribute to the basic function,
wherein the removal of any one of the parts causes the system to
effectively cease functioning" . . . [for example] (1) the cilium, (2)
the bacterial flagellum with filament, hook and motor embedded in the
membranes and cell wall and (3) the biochemistry of blood clotting in
humans . . . .
One point is clear: granted that there are indeed
many systems and/or correlated subsystems in biology, which have to be
classified as irreducibly complex and that such systems are essentially
involved in the formation of morphological characters of organisms,
this would explain both, the regular abrupt appearance of new forms in
the fossil record as well as their constancy over enormous periods of
time. For, if "several well-matched, interacting parts that contribute
to the basic function" are necessary for biochemical and/or anatomical
systems to exist as functioning systems at all (because "the removal of
any one of the parts causes the system to effectively cease
functioning") such systems have to (1) originate in a non-gradual
manner and (2) must remain constant as long as they are reproduced and
exist. And this could mean no less than the enormous time periods
mentioned for all the living fossils hinted at above. Moreover, an
additional phenomenon would also be explained: (3) the equally abrupt disappearance
of so many life forms in earth history . . . The reason why irreducibly
complex systems would also behave in accord with point (3) is also
nearly self-evident: if environmental conditions deteriorate so much
for certain life forms (defined and specified by systems and/or
subsystems of irreducible complexity), so that their very existence be
in question, they could only adapt by integrating further
correspondingly specified and useful parts into their overall
organization, which prima facie could be an
improbable process -- or perish . . . .
According
to Behe and several other authors [5-7, 21-23, 53-60, 68, 86] the only
adequate hypothesis so far known for the origin of irreducibly complex
systems is intelligent design (ID) . . . in connection with Dembski's
criterion of specified complexity . . . . "For something to exhibit
specified complexity therefore means that it matches a conditionally
independent pattern (i.e., specification) of low specificational
complexity, but where the event corresponding to that pattern has a
probability less than the universal probability bound and therefore
high probabilistic complexity" [23]. For instance, regarding the origin
of the bacterial flagellum, Dembski calculated a probability of 10^-234[22].
Now, first, we must observe that Darwin's proposed
test, on at least one major interpretation, is less generous than it
first appears: "If it could be demonstrated that any complex organ
existed, which could not possibly have
been formed by numerous, successive, slight modifications, my
theory would absolutely break down." For, as Shapiro acidly but aptly noted,
on the defects in such an appeal to bare possibility in defense of the
RNA world hypothesis -- making a remark that, we observe, inadvertently
also applies to his preferred
metabolism first scenario -- that:
The analogy that comes to mind
is that of a golfer, who having played a golf ball through an 18-hole
course, then assumed that the ball could also play itself around the
course in his absence. He had demonstrated the possibility of the
event; it was only necessary to presume that some combination of
natural forces (earthquakes, winds, tornadoes and floods, for example)
could produce the same result, given enough time. No physical law need
be broken for spontaneous RNA formation to happen, but the chances
against it are so immense, that the suggestion implies that the
non-living world had an innate desire to generate RNA. The majority of
origin-of-life scientists who still support the RNA-first theory either
accept this concept (implicitly, if not explicitly) or feel that the
immensely unfavorable odds were simply overcome by good luck.
In
short, there is a distinct difference and resulting massive,
probability-based credibility gap between having components of an
irreducibly complex,tightly integrated, information-rich functional
system with available energy but no intelligence to direct the energy
to construct the system, and getting by the happenstance of "lucky
noise," to that system. That is, physical and logical possibility are
not at all to be equated with probabilistic credibility -- especially
when there are competing explanations on offer -- here, intelligent
agency -- that routinely generate the sort of phenomenon being
observed.
So, having duly noted this caveat, through
reasoning within the generally accepted framework of the geological
record, and using a classic abductive
approach (If X, then otherwise puzzling facts F1,
F2, . . . follow at once; so the facts support but do not
prove explanation X; this is the core agenda of
science, and its core epistemological characteristic) we can see that
irreducible complexity and FSCI, working together, can explain major
and otherwise unexplained [for 150 - 200 years] features of the fossil
record of life. Of course, this sort of claim has not remained
unchallenged, and in particular the case of the bacterial
flagellum -- a cellular outboard motor that has an ion-driven
rotor tied to a hooked filament, that drives the bacterium as it spins
at up to upwards of 10,000 rpm -- has been a focus for debate.
On this, we can sum up the current score by again citing
Peterson:
Behe's most famous example is the bacterial
flagellum described above. If you take away the driveshaft from the
flagellar motor, you do not end up with a motor that functions less
well. You have a motor that does not function at all. All of the
essential parts must be there, all at once, for the motor to perform
its function of propelling the bacterium through liquid . . . . that is
precisely what Darwinian evolution cannot accomplish. Darwinian
evolution is by definition "blind." It cannot plan ahead and create
parts that might be useful to assemble a biological machine in the
future. For the machine to be assembled, all or nearly all the parts
must already be there and be performing a function. Why must they
already be performing a function? Because if a part does not confer a
real, present advantage for the organism's survival or reproduction,
Darwinian natural selection will not preserve the gene responsible for
that part. In fact, according to Darwinian theory, that gene will
actually be selected against. An organism that
expends resources on building a part that is useless handicaps itself
compared to other organisms that are not wasting resources, and will
tend to get outcompeted . . . .
Behe the biochemist . . . search[ed] the relevant
scientific journals, books, and proceedings of meetings to find out
what the Darwinists had really proven about the origin of complex
biochemical systems . . . . "There has never been a meeting, or a book,
or a paper on details of the evolution of complex biochemical systems"
. . . Behe, recalling the "fierce resistance" he encountered after the
publication of Darwin's Black Box, remarks that much of it came from
"Internet fans of Darwinism who claimed that, why, there were hundreds
or thousands of research papers describing Darwinian evolution of
irreducibly complex biochemical systems." Except that there aren't.
Well, this sent the Darwinians scrambling. Kenneth
Miller, a biologist at Brown University who argues in favor of
Darwinian evolution, made a splash when he announced (and he bolded the
language in his article) that "the bacterial flagellum is not
irreducibly complex." Miller cited a cellular structure known
as the type III secretory system (TTSS) that allows certain bacteria to
inject toxins through the cell walls of their hosts . . . .
But . . . the bubonic plague bacterium already
has the full set of genes necessary to make a flagellum.
Rather than making a flagellum, Y. pestis uses only part of the genes
that are present to manufacture that . . . injector instead. As pointed
out in a recent article by design theorist Stephen Meyer and
microbiologist Scott Minnich (an expert on the flagellar system), the
gene sequences suggest that "flagellar proteins arose first and those
of the pump came later." If evolution was involved, the pump came from
the motor, not the motor from the pump. Also, "the other
thirty proteins in the flagellar motor (that are not present in the
[pump]), are unique to the motor and are not found in any other living
system." . . . In short, the proteins in the TTSS do not
provide a "gradualist" Darwinian pathway to explain the step-by-step
evolution of the irreducibly complex flagellar motor.
Further to this, Meyer's
discussion of the Cambrian life revolution (which -- despite
much rhetoric to the contrary -- evidently
passed proper peer review by renowned scientists) in the same
record shows that the underlying pattern of sudden diversification is
particularly present and challenging for the Neo-Darwinian Theory [NDT]
at the point where the record first shows a dramatic widening of the
range of animal life at the highest level, the phylum, with dozens of
basic body plans appearing within a fairly narrow temporal window in
the record:
The
Cambrian explosion represents a remarkable jump in the
specified complexity or "complex specified information" (CSI) of the
biological world. For over three billions years, the biological realm
included little more than bacteria and algae (Brocks et al. 1999).
Then, beginning about 570-565 million years ago (mya), the first
complex multicellular organisms appeared in the rock strata, including
sponges, cnidarians, and the peculiar Ediacaran biota (Grotzinger et
al. 1995). Forty million years later, the Cambrian explosion occurred
(Bowring et al. 1993) . . . One way to estimate the amount of new CSI
that appeared with the Cambrian animals is to count the number of new
cell types that emerged with them (Valentine 1995:91-93) . . . the more
complex animals that appeared in the Cambrian (e.g., arthropods) would
have required fifty or more cell types . . . New cell types
require many new and specialized proteins. New proteins, in turn,
require new genetic information. Thus an increase in the
number of cell types implies (at a minimum) a considerable increase in
the amount of specified genetic information. Molecular
biologists have recently estimated that a minimally complex
single-celled organism would require between 318 and 562 kilobase pairs
of DNA to produce the proteins necessary to maintain life (Koonin 2000).
More complex single cells might require upward of a million base pairs.
Yet to build the proteins necessary to sustain a complex arthropod such
as a trilobite would require orders of magnitude more coding
instructions. The genome size of a modern arthropod, the
fruitfly Drosophila melanogaster, is approximately 180 million base
pairs (Gerhart & Kirschner 1997:121, Adams et al.
2000). Transitions from a single cell to colonies of cells to complex
animals represent significant (and, in principle, measurable) increases
in CSI . . . .
In order
to explain the origin of the Cambrian animals, one must account not
only for new proteins and cell types, but also for the origin of new
body plans . . . Mutations in genes that are expressed late in the
development of an organism will not affect the body plan. Mutations
expressed early in development, however, could conceivably produce
significant morphological change (Arthur 1997:21) . . . [but] processes
of development are tightly integrated spatially and temporally such
that changes early in development will require a host of other
coordinated changes in separate but functionally interrelated
developmental processes downstream. For this reason, mutations will be
much more likely to be deadly if they disrupt a functionally
deeply-embedded structure such as a spinal column than if they affect
more isolated anatomical features such as fingers (Kauffman 1995:200) .
. . McDonald notes that genes that are observed to vary within natural
populations do not lead to major adaptive changes, while genes that
could cause major changes--the very stuff of macroevolution--apparently
do not vary. In other words, mutations of the kind that
macroevolution doesn't need (namely, viable genetic mutations in DNA
expressed late in development) do occur, but those that it does need
(namely, beneficial body plan mutations expressed early in development)
apparently don't occur.6 [Emphases added. Cf a more easily
readable (and also peer-reviewed) but longer discussion, with
illustrations, here.]
Now, this analysis highlights a significant
distinction we need to make: micro-evolutionary changes
are late-developing, and do not affect the core body plan and its
associated functions. Such mutations are indeed possible and are
observed. But, when the mutations get to the fundamental level of
changing body plans -- i.e. macro-evolution -- they
face the implication that we are now disturbing the core of a tightly
integrated system, and so the potential for destructive change is much
higher. Consequently, the genes that control such core features are
stabilised by a highly effective negative feedback effect: random
changes strongly tend to eliminate themselves through loss of integrity
of vital body functions.
In response, it is often claimed that sufficient
microevolution accumulates across time to constitute macroevolution.
But, what we "see" in the fossil record of the Cambrian rocks is just
that innovation at the core levels coming first, and coming massively
-- just the opposite of what the NDT model would lead us to expect.
For, as Dan Peterson summarises
in his recent article:
To take just one example, a well-known (and
unsolved) problem for Darwinism is the Cambrian Explosion. As noted by
Stephen Meyer in the book Debating Design, this
event might be better called the Cambrian Information Explosion. For
the first three billion years of life on Earth, only single-celled
organisms such as bacteria and bluegreen algae existed. Then,
approximately 570 million years ago, the first multi-cellular
organisms, such as sponges, began to appear in the fossil record. About
40 million years later, an astonishing explosion of life took place.
Within a narrow window of about 5 million years, "at least nineteen and
perhaps as many as 35 phyla (of 40 total phyla) made their first
appearance on Earth...." Meyer reminds us that "phyla constitute the
highest categories in the animal kingdom, with each phylum exhibiting
unique architecture, blueprint, or structural body plan." These high
order, basic body plans include "mollusks (squids and shellfish),
arthropods (crustaceans, insects, and trilobites), and chordates, the
phylum to which all vertebrates belong."
These new, fundamental body plans appeared all at once, and without the
expected Darwinian intermediate forms.
In
addition, we should observe in passing that there is also an underlying
problem with the commonly
encountered natural
selection
model, in which small variations confer
significant cumulative advantages in populations,and cumulate to give
the large changes that would constitute body-plan level macroevolution.
To see this, let us excerpt a
typical definition of natural selection:
Natural
selection is the process by which favorable heritable
traits become more common in successive generations of a population of
reproducing organisms, and unfavorable heritable traits become less
common. Natural selection acts on the phenotype,
or the observable characteristics of an organism, such that individuals
with favorable phenotypes are more
likely to survive and reproduce than those with less favorable
phenotypes. The phenotype's genetic basis . . . will
increase in frequency
over the following generations. Over time, this process can result in
adaptations that specialize organisms for particular ecological niches
and may eventually result in the emergence of new species.
In other words, natural selection is the mechanism by which evolution
may take place in a population of a specific organism. [Emphases added.]
From this, we may immediately
observe that natural selection is envisioned as a probabilistic
culler of competing sub-populations with varying adaptations coming
from another source [usually some form of chance-based variation]. That
is, it does not cause
the actual variation, it is only a term that
summarises differences in likelihood
of survival and reproduction and possibly resulting cumulative effects
on
populations across time.
So, when innovations in life-forms require the origin of functionally
specific, information-rich organised complexity, we are back to some
form of chance variation to explain it, and soon run right back into
the FSCI-origination barrier.
Moreover, there are linked issues with the related gambler's
ruin challenge (as is discussed here).
For,
if a given selection advantage is small and the absolute numbers of the
sub-population
with the innovation are also relatively low, most of the time, such an
innovation will simply be lost due to the overwhelming effects of mere
chance on odds of survival and reproduction. In other words, one has to
have enough population resources to "spend" for long enough to get to
the long-run
point where modest differential effects will pay off to one's
advantage. And, if we take isolation to a niche without competition as
a typical example by which such innovations will have a good chance to
grow into a viable sub-population that can then migrate back and
compete with then dominate over the original population, we still have
not accounted for the rise of information-rich organically coherent
innovations, especially at that core body-plan level which expresses
itself in the vulnerable early phases of the embryological development
process.
Pulling the strands of analysis together, we may
see
that, in light of the evident FSCI embedded in life-forms at cellular
level, and its implications, the NDT has a major challenge accounting
precisely for the macro-evolution that it sets out to explain. But, by
sharp contrast, the concepts of irreducible complexity and FSCI/CSI
leading to design as a new paradigm are in fact able to relatively
easily account for these phenomena, within the generally accepted
geochronological and fossil frameworks.
Thus, it is fair
comment to observe that the
design inference seems to better explain
the generally accepted framework than the dominant paradigm, NDT.
This is in addition to the basic fact that,
strictly, the NDT does not
address the origin of life -- a situation where the dominant school in
biology (as seen above),
after 50 years of various models, still struggles to find a robust,
empirically adequate model. So, whatever objections may be made -- and
are often made, sadly, to the point of evident
workplace harassment in some cases [cf. US Congress Committee
staff investigation summary here
and main report here
with appendix here;
also the earlier OSC Letter here
as well as the Klinghoffer reports that publicly broke
and now follow
up the story] -- this basic contrast of explanatory
failure/success should be soberly reckoned with.
D]
Case III: The evidently fine-tuned cosmos
In this section, we focus on the underlying point
Cicero was making in his remarks cited
above, at the head of this web page: the complex arrangement
of the cosmos as a whole is credibly a signature of agency as the force that
brought it into being.
To address this, we will turn to cosmological finetuning:
how the
life-facilitating underlying physics of our observed cosmos seems to
exhibit fine-tuned
organised complexity. In effect, if
we were to give an outline description of the physical laws, constants
and ratios for the observed cosmos, we
would find a fairly complex,
quite mathematically elegant set of delicately balanced information.
For, if we were to start from the values we
observe then perturb them slightly
[just how much depends on the particular relationship or parameter], for
many, many cases, the resulting changed cosmos would be
radically unfriendly to life as we observe it.
To get an idea of the degree of functionally
specified complex information involved in that organised complexity, we
can consider just four fine-tuned parameters of the observed cosmos and
their precision and estimate the number of bits required to define the
numbers, using the relationship that lg[a]/lg [b] = logb[a]:
Fine
Tuning of the Physical Constants of the Universe
| Parameter |
Max.
Deviation* |
Estimated number of
"required" bits |
| Ratio
of Electrons:Protons |
1:1037 |
123 |
| Ratio
of Electromagnetic Force:Gravity |
1:1040 |
133 |
| Expansion
Rate of Universe |
1:1055 |
183 |
| Mass
of Universe1 |
1:1059 |
196 |
|
Cosmological Constant |
1:10120 |
399 |
| *These
numbers represent the maximum deviation from the accepted values, that
would either prevent the universe from existing now, not having matter,
or be unsuitable for any atom-based form of life. (Cf. below
for details.) |
TOTAL:
1,034
|
Table
D.1: Degree of Fine-tuning
of four key parameters of the observed cosmos. [Adapted: Deem,
R, of RTB. Ref 1 links onward
to Prof Ed White of UCLA. The Cosmological constant is in effect the
requisite energy density of free space to compensate for the "missing"
matter density, consistent with the observed accelerating expansion of
the universe.]
Thus, just these four initial fine-tuned parameters
would require 1,034 bits of information capacity to store them, whilst
there are dozens of other parameters and an entire framework of physics
for them to fit in. Now, too, 500 to 1,000 bits express a configuration
space with ~ 3.27*10^150 to *10^301 cells. That is, we are looking at a
clear instance of functionally specified, complex information[FSCI];
as, to get just these
four parameters right at the same time, we would need to be in
just the right one of ~1.84*10^311 cells.
But, we have got a bit ahead of ourselves and we
need to pause to discuss what "fine tuning" means.
So, since, by common consent, it is he who first
identified a major cosmological finetuning issue, it is appropriate to
give pride of place to a cite from the late, great Sir Fred Hoyle:
From 1953 onward,
Willy Fowler and I have always been intrigued by the remarkable
relation of the 7.65 MeV energy level in the nucleus of 12 C to the
7.12 MeV level in 16 O. If you wanted to produce carbon and oxygen in
roughly equal quantities by stellar nucleosynthesis, these are the two
levels you would have to fix, and your fixing would have to be just
where these levels are actually found to be. Another put-up job?
Following the above argument, I am inclined to think so. A
common sense interpretation of the facts suggests that a super
intellect has "monkeyed" with the physics as well as the chemistry and
biology, and there are no blind forces worth speaking about in nature. [F.
Hoyle, Annual Review of Astronomy and Astrophysics, 20 (1982):
16.Cited, Bradley, in "Is
There Scientific Evidence for the Existence of God? How the Recent
Discoveries Support a Designed Universe". Emphasis added.]
Why is this particular balance so important?
Astrophysicist Hugh Ross, in his The
Creator and the Cosmos (Colorado Springs: NavPress, 1993),
explains -- based on the conditions and consequences for nuclear fusion
reactions in stars -- that: "In the late 1970's and early 1980's, Fred
Hoyle discovered that an incredible fine tuning of the nuclear ground
state energies for helium, beryllium, carbon and oxygen was necessary
for any kind of life to exist. The ground state energies for these
elements cannot be higher or lower with respect to each other by more
than 4% without yielding a universe with insufficient oxygen or carbon
for life." [p. 107.]
Later, Ross notes that "[b]oron and silicon are the
only other elements on which complex molecules can be based, but boron
is extremely rare, and silicon can hold together no more than about a
hundred amino acids. Given the constraints of physics and chemistry, we
can reasonably assume that life must be carbon-based." [p.125.] He also
notes that:
there is one life-essential heavy element that is
not made by supernovae, fluorine. It is made only on . . . the surfaces
of white dwarf stars bound into stellar systems with larger stellar
companions. The larger companion must orbit closely enough . . . that
it loses sufficient material to the white dwarf . . . [on whose
surface] some of the material is converted into fluorine. Then the
white dwarf must lose this fluoridated material into interstallar space
. . . . The location, types, rates and timings of both supernova events
and white dwarf binaries severely constrains the possibility of finding
a life support site. [p.125.]
In short, within the generally
accepted, Big Bang theory-derived framework for the origin of
the cosmos [here, string landscapes, brane
cosmologies and the like are viewed as so far more or less empirically
untested extensions -- and indeed, one of the latest "hot ideas," colliding branes that yield expanding universes, according to Linde et al, 2001, would require that "the branes [are] to be parallel to each other with an
accuracy better than 10^{-60} on a scale 10^{30} times greater than the
distance between the branes"], the conditions for creating the elements
foundational to biological life as we know it are quite constrained.
Similarly, the underlying forces in the cosmos are delicately balanced
indeed. For, as William Lane Craig summarised
in brief:
Changes in the gravitational or electromagnetic
forces, for example, by only one part in 10^40 would preclude the
existence of stars like our sun, making life impossible. Changes in the
speed of the expansion by only one part in a million million when the
temperature of the universe was 10^10 degrees would have either
resulted in the universe's recollapse long ago, or precluded galaxies'
condensing, in both cases making life impossible. The present
temperature of the universe is so isotropic [uniform] that Roger
Penrose of Oxford calculates that "the accuracy of the Creator's aim,"
when he selected this world from the set of physically possible ones,
must have been on the order of one part in 10^10(^124). [That is, 1
followed by 10^124 zeros, far more than there are atoms in the observed
universe.]
Altogether, there are dozens
of such in aggregate finely balanced parameters, perhaps the
most finely balanced being the so-called cosmological constant, which
seems to be accurate to better than one part in 10^100. Similarly, as
Ross also reports, "[u]nless the number of electrons is equivalent to
the number of protons to an accuracy of one part in 10^37, or better,
electromagnetic forces in the universe would have so overcome
gravitational forces that galaxies, stars, and planets never would have
formed." [p. 109.] But,
perhaps the most significant overall observation is due to John Leslie:
One striking thing about the fine tuning is that a
force strength or a particle mass often appears to require accurate
tuning for several reasons at once. Look at
electromagnetism. Electromagnetism seems to require tuning for there to
be any clear-cut distinction between matter and radiation; for stars to
burn neither too fast nor too slowly for life’s requirements; for
protons to be stable; for complex chemistry to be possible; for
chemical changes not to be extremely sluggish; and for carbon synthesis
inside stars (carbon being quite probably crucial to life). Universes
all obeying the same fundamental laws could still differ in the
strengths of their physical forces, as was explained earlier, and
random variations in electromagnetism from universe to universe might
then ensure that it took on any particular strength sooner or later.
Yet how could they possibly account for the fact that the
same one strength satisfied many potentially conflicting requirements,
each of them a requirement for impressively accurate tuning? [Our
Place in the Cosmos, 1998 (courtesy Wayback Machine) Emphases added.]
So robust is this pattern of
convergent, integrated, finely balanced parameters, that the majority
of scientific cosmologists currently accept that the finetuning is
real; the question is to
account for it. Nor, plainly, does this
ultimately rely on there being just one cosmos,
i.e. the currently observed one. For, as he also notes, through the
metaphor of the fly on the wall:
. . . the need for such explanations does not
depend on any estimate of how many universes would be
observer-permitting, out of the entire field of possible universes.
Claiming that our universe is ‘fine tuned for observers’, we base our
claim on how life’s evolution would apparently have been rendered
utterly impossible by comparatively minor
alterations in physical force strengths, elementary particle masses and
so forth. There is no need for us to ask whether very great alterations
in these affairs would have rendered it fully possible once more, let
alone whether physical worlds conforming to very different laws could
have been observer-permitting without being in any way fine tuned. Here
it can be useful to think of a fly on a wall, surrounded by an empty
region. A bullet hits the fly Two explanations suggest themselves.
Perhaps many bullets are hitting the wall or perhaps a marksman fired
the bullet. There is no need to ask whether distant areas of the wall,
or other quite different walls, are covered with flies so that more or
less any bullet striking there would have hit one. The important point
is that the local area contains just the one fly. [Emphasis his.]
Walter Bradley gives
the wider context, by laying out some general "engineering
requisites" for a life-habitable universe; design specifications, so to
speak:
- Order to provide the stable environment that is
conducive to the development of life, but with just enough chaotic
behavior to provide a driving force for change.
- Sufficient chemical stability and elemental
diversity to build the complex molecules necessary for essential life
functions: processing energy, storing information, and replicating. A
universe of just hydrogen and helium will not "work."
- Predictability in chemical reactions, allowing
compounds to form from the various elements.
- A "universal connector," an element that is
essential for the molecules of life. It must have the chemical property
that permits it to react readily with almost all other elements,
forming bonds that are stable, but not too stable, so disassembly is
also possible. Carbon is the only element in our
periodic chart that satisfies this requirement.
- A "universal solvent" in which the chemistry of
life can unfold. Since chemical reactions are too slow in the solid
state, and complex life would not likely be sustained as a gas, there
is a need for a liquid element or compound that readily dissolves both
the reactants and the reaction products essential to living systems:
namely, a liquid with the properties of water. [Added note: Water
requires both hydrogen and oxygen.]
- A stable source of energy to sustain living systems
in which there must be photons from the sun with sufficient energy to
drive organic, chemical reactions, but not so energetic as to destroy
organic molecules (as in the case of highly energetic ultraviolet
radiation).
- A means of transporting the energy from the source
(like our sun) to the place where chemical reactions occur in the
solvent (like water on Earth) must be available. In the process, there
must be minimal losses in transmission if the energy is to be utilized
efficiently. [Emphases added.]
Robert C. Koons, in discussing "Post-Agnostic
Science," therefore draws out the logical skeleton of the associated
design inference. So, he argues, first to an intelligence, and that
could include a system of nature that is in itself intelligent, then
onward to the required nature of such an agent, one capable of and
actually creating a cosmos. (But note that, while it is compatible
with such a worldview, this inference to explanation of the finetuning
of the cosmos argument is not at all the same as an inference to a
specifically theistic
-- much less, the Judaeo-Christian -- Creator. That
broader question goes into broader philosophical,
historical, biblical
and theological
rather than strictly scientific issues, and so most design thinkers
hold these to be strictly beyond the remit of science proper. Of
course, though, in a science-dominated age it is important to be able
to see and show that the actual scientific data are compatible with
such a theistic view. [Cf. Ross's critique of the general design theory
view on these points, here.])
Specifically, Koons argues:
1]
The physical constants of the cosmos take anthropic values [that is,
those conducive to C-based, intelligent life].
2]
This coincidence must have a causal explanation (we set aside for the
moment the possibility of a chance explanation through the many-worlds
hypothesis [cf. on this, the points raised by Leslie as cited above; noting too that
such a wider "multiverse" is speculative rather than observationally
anchored]).
________________________________________________
3]
Therefore, the constants take the values that they do because these
values are anthropic (i.e., because they cause the conditions needed
for life).
4]
Therefore, the purpose of the values of these constants is to permit
the development of life (using the aetiological definition of purpose).
5]
Therefore, the values of these constants are the purposive effects of
an intelligent agent (using the minimalist conception of agency).
6]
Therefore, the cosmos has been created.
Now, of course, objections and alternatives have
been put forth. These are of course fairly easy to find on the
Internet, as the compatibility of the above line of reasoning with
theistic worldviews rubs a raw nerve in many secularist quarters.
(Counters to these objections can also be found, and so forth.)
Here, we
can briefly summarise several typical objections and associated
questions, and note briefly on them:
- Multiple sub-universes: It is
asserted that there is an at least quasi-infinite array of
sub-universes that have popped up out of the underlying eternal
universe as a whole, with randomly scattered parameters. So, we are in
the one that just happened to get lucky: somebody
will as a rule win a lottery! We should therefore not be surprised, and
there is nothing more to "explain." (Of course, this first
resorts to suggesting that there is/must be a vast, unobserved
wider universe as a whole. So, right from the start it moves into the
province of a worldview claim; it is not at all properly a scientific
theory. It therefore cannot fairly exclude other worldview claims from
the table of comparative
difficulties analysis, nor can it stand apart from the other
claims of the underlying worldview it attempts to save: that morally indefensible
and factually
inadequate and logically self-defeating naturalistic
philosophical system that can be best described as evolutionary
materialism. Moreover, following
Koons, we may paraphrase Leslie tellingly: let us think of a
miles-long wall, some of whose sections are actually carpeted with
flies; but there is a 100-yard or so stretch with just one fly. Then,
suddenly, a bullet hits it. Is it more credible to think that the fly
is just monstrously unlucky, or do we celebrate the marksmanship of the
hidden shooter? That is, in the end, a locally rare and
finetuned possibility is just as wondrous as a globally finetuned one.)
- But, Science cannot think in terms of the
supernatural: That is, "science" is here redefined in terms
of so-called methodological
naturalism, which in effect implies that a claim can only be
deemed scientific if it explains in terms compatible with the
materialist's sequence of postulated evolutions: cosmological,
chemical, biological, socio-cultural. (That is not only
demonstrably historically
inaccurate, but it also reduces to: imposition of
philosophical materialism by implication. In short, it reduces to philosophical
materialism disguised as science. Nor is it fair: in fact the
distinction the inference to design makes, strictly is to selecting
intelligent agency from the three-way split: chance, regularity of
nature [aka necessity], agency. If FSCI is a signature of intelligence,
then its detection points us to intelligence, and so we should not
resort to intellectual gerrymandering to rule out such possibilities.)
- "Chance" is good enough, we just plain got
lucky: In effect, odds mean nothing as SOMEONE has to win a
lottery, and there is probably much more universe out there than we
happen to see just now. (First, not all lotteries are
winnable, and cosmologically evolving a life-habitable universe that
then forms life is not set up to deliver a winner, on pain of reducing
to yet another design inference -- cf. Leslie's argument above on the point that the cosmos
is designed to get to life, even through a random array of sub-cosmi.
But, of course, the point of the fly on the wall analogy is that, a
locally rare and finetuned possibility is just as wondrous as a
globally rare one. More to the point, the argument self-refutes through
its underlying inconsistency: routinely, in the face of the logical
possibility that all apparent messages we have ever decoded are simply
lucky noise, we infer to intent as the explanation of many things, once
they exhibit FSCI: in effect, we take the "welcome to Wales sign" made
out of arranged stones seriously, and do not dismiss it as a quirk of
geology. In short, the selective resort to "chance" to explain some of
the most complex and functionally specific entities we observe is
driven by a worldview commitment, not a consistent pattern of
reasoning. So, the objector first needs to stop being selectively
hyperskeptical, and should fairly address the comparative difficulties
problems of his/her own worldview.)
- The "probabilities"/"Sensitivities" are
not credible: usually, this is said by, say challenging the
fineness of the balance, perhaps by asserting that some of the
parameters may be linked, or that they are driven by an underlying
regularity, one that is not as yet discovered. It may even be asserted
that the scope of the universe as a whole is such that the size swamps
the probabilities in the "little" sub-cosmos we can see. (The
first two of these face the problem that while say the Carbon-Oxygen
balance is of the order of several percent, the ratio of electrons to
protons is unity to within 10^-37, and other parameters that simply do
not depend on the accident of how many electrons and protons exist, are
even finer. An underlying regularity that drives cosmic values and
parameters to such fine balances of course itself raises the issue of
design. And, not only is the proposed wider universe concept not
empirically controlled, thus strictly a philosophical issue; but also
it is manifestly an
after the fact ad hoc assertion driven by the discovery of
the finetuning.)
- You
can't objectively assign "probabilities": First, the argument strictly
speaking turns
on sensitivities,
not probabilities-- we have dozens of parameters, which
are locally quite sensitive in aggregate, i.e. slight [or modest in
some cases] changes relative to the current values will trigger radical
shifts away from the sort of life-habitable cosmos we observe. Further,
as Leslie has noted, in some cases the Goldilocks zone values are such
as meet converging constraints. That gives rise to the intuitions that
we are looking at complex, co-adapted components of a harmonious,
functional, information-rich whole. So we see Robin Collins observing, in
the just linked:"Suppose we went on a mission
to Mars, and found a domed structure in which everything was set up
just right for life to exist . . . Would we draw the conclusion that it
just happened to form by chance? Certainly not . . . . The
universe is analogous to such a "biosphere," according to recent
findings in physics. Almost everything about the basic structure of the
universe--for example, the fundamental laws and parameters of physics
and the initial distribution of matter and energy--is balanced on a
razor's edge for life to occur. As the eminent Princeton physicist
Freeman Dyson notes, "There are many . . . lucky accidents in physics.
Without such accidents, water could not exist as liquid, chains of
carbon atoms could not form complex organic molecules, and hydrogen
atoms could not form breakable bridges between molecules" (p. 251)--in
short, life as we know it would be impossible." So,
independent of whether or not we accept the probability estimates that
are often made, the fine-tuning argument in the main has telling force.
- Can
one assign reasonable Probabilities? Yes. Where
the value of a variable is not otherwise constrained across a relevant
range, one may use the Laplace criterion of indifference to assign
probabilities. In effect, since a die may take any one of six
values, in absence of other constraints, the credible probability of
each outcome is 1/6. Similarly, where we have no reason to
assume otherwise, the fact that relevant cosmological parameters may
for all we know vary across a given range may be converted into a
reasonable (though of course provisional -- as with many things in
science!) probability estimate. So,
for instance, the Cosmological Constant
[considered to be a metric of the energy density of empty space, which
triggers corresponding rates of expansion of space itself], there are
good physical science reasons [i.e. inter alia Einsteinian General
Relativity as applied to cosmology] to estimate that the credible
possible range is 10^53 times the range that is life-accommodating, and
there is no known constraint otherwise on the value. Thus, it is
reasonable to apply indifference to the provisionally known possible
range to infer a probability of being in the Goldilocks zone of 1 in
10^53. Relative to basic principles of probability reasoning and to the
general provisionality of science, it is therefore reasonable to infer
that this is an identifiable, reasonably definable value.
(Cf Collins'
discussion, for more details.)
- There are/may be underlying forcing laws
or circumstances: It is possible that as yet undiscovered
physics may lead us to see that the values in question are more or less
as they "have" to be. (However, such a "theory of everything"
would itself imply exquisitely balanced functionally specific
complexity in the cosmos as a whole, i.e. it is itself a prospect that
would lead straight to the issue of design as its explanation.)
- What about radically different forms of
life: We do not know for certain that life must be based on
carbon chemistry, so perhaps there is some strange configuration of
matter and/or energy (or perhaps, borrowing from the Avida
experiments, information) that can be called "life" without being based
on the chemistry of carbon and related atoms. (Indeed,
theists would immediately agree: spirit is a way
that life can exist without being tied down to atoms and molecules!
They would also immediately agree that information and -- more
fundamentally -- mind are key components of intelligent life. So, this
point may lead in surprising directions. But more on the direct point,
the proposal is again highly speculative and ad hoc, once it was seen
that the cosmos seems designed for life as we know it.)
- Naturalistic Anthropic Principles:
Perhaps, the most important version, the Weak form [WAP] asserts that
intelligent life can only exist in a cosmos that has properties
permitting their origin and existence. Then, it is inferred, if we are
here, we should not be surprised that the parameters are so tight: if
they were not met, we would not be here to wonder about it. (Now,
of course, if the universe did not permit life like ours, we would not
be here to see that we do not exist. But that still leaves open the
implications of the point that the cosmos in which we do exist is
exquisitely finely tuned for that existence, at least on a local basis.
That is, we are simply back to the fly on the wall gets swatted by a
bullet example; it is still wondrous and raises the question of
marksmanship and intent as the best explanation.)
While of course the above is (relatively speaking!)
brief and basic, it brings into focus the key point that the evident
finetuning of the cosmos for intelligent life puts the issue of design
squarely on the table. And, once that is on the table, since we are
dealing with the origins of the universe as we know it, with remarkable
finetuning and at a defined time in the past, some 13.7 BYA by current
estimates.
The alternative to a Creator as the explanation, it
soon turns out, is a speculative wider cosmos as a whole that is
eternal and necessary. Once that has been suggested -- often under the
label "science" though it is properly speculative metaphysics -- we
then hear the classic challenge: God of the gaps fallacy! [Cf.
here on the
arguments to/against God.]
To that, let us now turn:
E]
Broadening the Issue: Persistent "Gaps," Man, Nature, Science and Worldviews
"God of the Gaps!"
At the mere mention of the term -- one dripping
with memories of now-filled-in "gaps" in scientific explanations that
were once used as ill-advised "proofs" or "evidences" of God's existence, many thinkers
(especially some theistic ones) wish to look no further. Thus, under
this banner, the issue of inference to design as discussed so far is
then brushed aside as "obviously not proper
science." That is, in large
part through the rhetorical power of the phrase, God of the
gaps, the attempted redefinition of science as methodological
naturalism -- in effect "the best evolutionary
materialist account of the cosmos, from hydrogen to humans"
-- has far too often been allowed to prevail without facing squarely
(much less, having to satisfactorily work out in detail) the many
thorny challenges that lurk in the
underlying demarcation problem.
But, in fact, not only across the past 350 years
but currently, it
is simply not accurate nor justifiable to reduce science to
such terms. For, it is abundantly warranted by the history of the rise
of modern science, and by contemporary praxis, to accept the more
traditional -- and less philosophically loaded -- definition of science,
such as we may easily read in high-quality dictionaries:
science: a branch of knowledge
conducted on objective principles involving the systematized
observation of and experiment with phenomena, esp. concerned with the
material and functions of the physical universe. [Concise
Oxford, 1990 -- and yes, they used the "z" Virginia!]
scientific method: principles
and procedures for the systematic pursuit of knowledge [”the body of truth, information and principles
acquired by mankind”] involving
the recognition and formulation of a problem, the collection of data
through observation and experiment, and the formulation and testing of
hypotheses. [Webster's 7th Collegiate, 1965]
Further to this, not only in science but also in
wider worldview analysis, we are not dealing with that mythical holy
grail: proof beyond rational dispute. Instead, we
must grapple with the messy world of creative
abductive inferences to explanations and provisional warrant
in light of the challenge of comparative difficulties. That is, serious
explanations must face the three-headed issue of explanatory adequacy
directly and as compared with live option alternatives:
(1) adequacy
relative to the material facts -- those that make a difference to the
conclusion;
(2) coherence:
logical consistency without undue circularity; and,
(3) power:
elegant simplicity as opposed to being either simplistic or an ad hoc
patchwork.
Also, in the end we think as humans, beings who
inevitably wonder about how we came to be here;
beings who have to use and rely on our minds to think about such
problems; beings who find ourselves sensing a duty
to be honest and fair-minded in how we think about these things.
That
this is not just an academic exercise is aptly illustrated by the sad
course of events surrounding the evolution of Kansas Board of Education
state science standards (and in particular the definition of science),
from about 1999 to the present. For instance, we may contrast two
alternative definitions of science, the first a radical evolutionary
materialist agenda-driven redefinition attempt from 2001, the second, a
now unfortunately defeated attempted corrective from 2005; which was based on a more traditional, historically and philosophically well-warranted understanding similar to those cited just above:
2001 Definition: “Science is the human activity of seeking natural explanations of the world around us.”
2005 Definition:
“Science is a systematic method of continuing investigation, that uses
observation, hypothesis testing, measurement, experimentation, logical
argument and theory building, to lead to more adequate explanations of natural phenomena.” [Emphases added.]
Sadly, the 2001 radical
redefinition (NB: more or less reimposed, circa 2007: "Science is a human activity of systematically seeking natural explanations for what we observe in the world around us" [cf p. xii here]) is an implicit and improper
imposition of materialism in the name of science.
For, it was immemorial in the days of Plato's The Laws Book X, that what in our day
Monod termed "chance and necessity" do not exhaust the list of credible fundamental causal factors. As, what Plato termed "art" -- i.e. intelligent action -- is just as much an empirically observed and possible causal factor; including
specifically on origins. So, we must not a priori rule out possible
causal factors simply because certain possible candidates for the actual cause
of what we see may not fit comfortably with our worldview and associated
ideological agendas. At
least, if science is to retain the fundamental mission and vision that
it is an empirically anchored, unfettered, open-ended and open-minded
search for the truth about our universe based on observation,
hypothesis, predictions, experimental/observational testing and
objective reasoned argument.
But, sadly, in the 2001 redefinition "natural" is held to contrast with "supernatural," with the highly relevant, longstanding alternative contrast: nature/art
being passed over in a rhetorically convenient, strawman-shaped silence. So, by making a
tendentious contrast (often under the guise that science "must" apply
the rule of so-called "methodological naturalism"),
the idea is smuggled in that inference to design is inescapably or at
least invariably about bringing in an improper, empirically unsupported
inference to the supernatural. [Cf. typical rationales for the methodological naturalism rule here and here, a corrective rebuttal to such views here and here, a related discussion of its metaphysical connexions here, and also Plantinga's somewhat tangential but enriching discussion here and here. This discussion on a proposed successor, methodological neutralism, is also well worth a read.]
A
further illustration of what is going on can be seen from the current
US National Academy of Sciences update to/version of their booklet, Science, Evolution and Creationism, p. 10, where they provide a contextualised definition of science.
Standing
by itself, the 2008 NAS definition is generally reasonable (insofar as any
"simple" definition of so diverse a phenomenon as science is at all
possible):
Definition of Science
The
use of evidence to construct testable explanations and predictions of
natural phenomena, as well as the knowledge generated through this
process. [US NAS, 2008]
This is fine, insofar as it goes [on what is probably better termed Natural Science].
It closely parallels the high quality dictionaries cited above; and,
for that matter, the 2005 Kansas definition. What is not so fine,
however, is what happens in its immediate context; which is meant to
control how the definition is understood and used. Specifically, in the
paragraph leading up to the just cited definition, we may read:
In science, explanations must be based on naturally occurring
phenomena. Natural causes are, in principle, reproducible and therefore
can be checked independently by others. If explanations are based on
purported forces that are outside of nature, scientists have no way of
either confirming or disproving those explanations. Any scientific explanation has to be testable — there must be possible observational consequences that could support the idea but also ones that could refute it.
Unless a proposed explanation is framed in a way that some
observational evidence could potentially count against it, that
explanation cannot be subjected to scientific testing. [Emphases added.]
But of course, the very NAS scientists themselves provide instances of an alternative to forces tracing to chance and/or mechanical necessity: they
are intelligent, creative agents who act into the empirical world in
ways that leave empirically detectable and testable traces. (Indeed,
when such scientists set up an experiment then test for the results of
their interventions, they are not only studying natural causes and
phenomena, but also what intelligent investigators have artificially
induced; confident that there are underlying natural regularities that
will come out, even in artificially selected and set up circumstances.
Such regularities would include for instance, the probability
distributions of chance forces at work: flat, reverse-J, U,
"bell-shaped," Gaussian, binomial, Poisson, Weibull, etc. And, the open
assertion or implicit assumption that all such intelligences
"must" trace ultimately to chance and/or necessity acting within a
materialistic cosmos, is a debatable philosophical position on
the remote and unobserved past history of our cosmos; not at all
an established scientific "fact" on the level of direct and repeatable
observations that have led to the conclusion that the planets orbit the
sun. [Cf. here for a current instance of this unwarranted assertion, and below for the crucially important distinction between operational and origins studies in science.] )
In short, we see here yet another saddening illustration of the subtly fallacious, censoring insertion of the dichotomy: natural/ supernatural, in the teeth of the obvious alternative: natural/ artificial.
And, that, in a general situation where this precise alternative
is on the table and is much discussed; courtesy the efforts of the
design thinkers. So, the failure to frankly face and objectively engage
that alternative is a telling, prejudicial suppression
of materially relevant evidence and views. Such is
inexcusable on the part of scientists and educators who are presumably
dedicated to discovering and
communicating the truth about the world, based on empirical observation
and/or experiment, resulting collected evidence and inferred
provisional best explanations of those credible empirical facts.
The US
National Science Teachers Association [NSTA] as of July 2000, and over
the signature of its Board of Directors, makes the same
question-begging imposition of naturalism in its definition of the nature of science for educational purposes:
All those involved with science teaching and learning should have a
common, accurate view of the nature of science. Science is characterized
by the systematic gathering of information through various forms of
direct and indirect observations and the testing of this information by
methods including, but not limited to, experimentation. The principal
product of science is knowledge in the form of naturalistic concepts and
the laws and theories related to those concepts . . . . science, along with its methods, explanations and generalizations, must
be the sole focus of instruction in science classes to the exclusion of
all non-scientific or pseudoscientific methods, explanations,
generalizations and products . . . .
Although no single universal step-by-step scientific method captures the
complexity of doing science, a number of shared values and perspectives
characterize a scientific approach to understanding nature. Among these
are a demand for naturalistic explanations supported by empirical
evidence that are, at least in principle, testable against the natural
world. Other shared elements include observations, rational argument,
inference, skepticism, peer review and replicability of work . . . .
Science, by definition, is limited to naturalistic methods and
explanations and, as such, is precluded from using supernatural elements
in the production of scientific knowledge. [Emphases added.]
By strongest contrast with the above attempted dismissals by the NAS and NSTA et al, the design inference is an induction made based on a well supported empirical observation: intelligent agents act into our world, and when they do so they often leave characteristic signs of art-ificial -- or, intelligent -- action; such as functionally specified, complex information.
Notice again, as we are swimming against the tide here: on
empirical evidence and empirically reliable well-tested signs, we may
properly and reasonably contrast natural causes traceable to
chance and/or mechanical necessity from intelligent or artificial -- as
opposed to "supernatural" [that, is an intentionally polarising and
denigratory strawman caricature] -- causes. On the strength of this very well-supported observation, and the
common-sense principle that "like causes like," it is plainly an
empirically well justified and properly scientific induction to infer
from such observed signs to the action of such agents; regardless of
possible onward worldview level implications and debates -- which it is
no business of science to censor itself over.
Arguably, the impact of such "methodological
naturalism" as we have just seen is to subtly establish evolutionary materialistic Secular Humanism as a
de facto, functional equivalent to a religion backed by state power on
law, education, institutionalised science and many other aspects of the public square. ("Subtly?" Yes: in
Western cultures, we do not usually think of
non-theistic worldviews and associated ideologies and institutions they
influence in the terms of being potentially the functional equivalent
of established and potentially domineering institutionalised religions. Especially, if such non-theistic ideologies come to us
wearing the highly respected lab coat of the scientist . . . )
On this last, Richard Lewontin's notorious hidden agenda admission, in its actual context (a review of Sagan's The Demon-Haunted World), should give us serious pause:
.
. . to put a correct view of the universe into people's heads we
must first get an incorrect view out . . . the problem is
to get them to
reject irrational and supernatural explanations of the world, the
demons that
exist only in their imaginations, and to accept a social and
intellectual
apparatus, Science, as the only begetter of truth . . . . Sagan's
argument is straightforward. We exist as material beings in a
material world, all of whose phenomena are the consequences of physical
relations among material entities. The vast majority of us do not have
control
of the intellectual apparatus needed to explain manifest reality in
material
terms, so in place of scientific (i.e., correct material) explanations,
we
substitute demons . . . . Most of the chapters of The Demon-Haunted World are taken
up with exhortations to the reader to cease whoring after false gods and to
accept the scientific method as the unique pathway to a correct understanding
of the natural world. To Sagan, as to all but a few other scientists, it is
self-evident that the practices of science provide the surest method of
putting us in contact with physical reality, and that, in contrast, the
demon-haunted world rests on a set of beliefs and behaviors that fail every
reasonable test . . . .
Our willingness to accept scientific claims that are against common
sense is the key to an understanding of the real struggle between science and
the supernatural. We take the side of science in spite of the
patent absurdity of some of its constructs, in spite of its failure
to fulfill many of its extravagant promises of health and life, in
spite of the tolerance of the scientific community for unsubstantiated
just-so stories, because we have a prior commitment, a commitment to
materialism. It is not that the methods and institutions of science somehow compel us to accept a material explanation of the
phenomenal world, but, on the contrary, that we are forced by our a
priori adherence to material causes to create an apparatus of
investigation and a set of concepts that produce material explanations, no
matter how counter-intuitive, no matter how mystifying to the uninitiated.
Moreover, that materialism is absolute, for we cannot allow a Divine Foot in
the door. The eminent Kant scholar Lewis Beck used to say that anyone who
could believe in God could believe in anything. To appeal to an omnipotent
deity is to allow that at any moment the regularities of nature may be
ruptured, that miracles may happen.
This, sirs, is
worldview warfare, raw and naked and reeking of the outright subversion
of science in service to a wider agenda.
All, driven by the view that "Science" -- by that term, Lewontin plainly means evolutionary materialism (which, ironically, is inherently self-refuting and so inescapably irrational) -- is "the only begetter of truth," which gives us "correct material" that constitutes "the
surest method of
putting us in contact with physical reality." A "reality" that, with
disgust, dismisses the possibility of God from the outset, thus tilting
the playing field so that the committed "take the side of science in spite of the
patent absurdity of some of its constructs, in spite of its failure
to fulfill many of its extravagant promises of health and life, in
spite of the tolerance of the scientific community for unsubstantiated
just-so stories, because [they] have a prior commitment, a commitment to
materialism." [Link and final emphasis added.]
Science,
in the end -- whatever its many contributions to progress -- in
such hands and minds primarily becomes a stalking horse for
evolutionary materialism and for the imposition of associated
socio-cultural, policy and political agendas that would otherwise be
unacceptable.
Minds that are blinded to what the founding era scientists of three hundred years ago instinctively understood
from the basic principles and teachings of their Judaeo-Christian
worldview: a world created by the God who is "the author of order,
not confusion" would be set up, sustained and run according to
intelligible ordering principles manifesting themselves in reliable
cause-effect chains -- i.e. actual "laws" by an actual Legislator -- that would therefore obtain in
general. But at the same time, such a world would be open to the intervention of minds and Mind. Thus, too, the classic motto of the early modern scientists: thinking God's thoughts after him.
But,
consistent with the classic "divide and rule" political and propaganda
stratagem, the evolutionary materialist ideologues have now set up a
strawman opponent, which they have turned into a demonic bogeyman.
Even, as they push a ruthlessly pursued agenda that looks more and
more convincingly like the creation of an ideological establishment
with themselves as de facto Magisterium.
What that sort of agenda means on the ground can be clearly seen from the intervention
made in 2005 by the US National Academy of Sciences [NAS] and the
National Science Teachers Association [NSTA], through their joint
statement on the 2005 science education standards for Kansas.
The crucial paragraph of that statement reads, in its key part:
.
. . the members of the Kansas State Board of Education who produced
Draft 2-d of the KSES have deleted text defining science as a search
for natural explanations of observable phenomena, blurring the line between scientific and other ways of
understanding. Emphasizing controversy in the theory of evolution
-- when in fact all modern theories of science are continually tested
and verified -- and distorting the definition of science are inconsistent with our Standards and a disservice to the students
of Kansas. Regretfully, many of the statements made in the KSES related
to the nature of science and evolution also violate the document’s
mission and vision. Kansas students will not be well-prepared for
the rigors of higher education or the demands of an increasingly
complex and technologically-driven world if their science education is
based on these standards. Instead, they will put the students of
Kansas at a competitive disadvantage as they take their place in the
world.
This statement is deeply flawed and inadvertently highly revealing:
1 --> Immediately, there is no one "the
definition of science" that may be owned or authoritatively imposed by
any institution or group of institutions. Nor can such bodies, however
august, properly demand that we must take their presented definitions at
face value; without critical assessment or drawing our own conclusions
for ourselves in light of our own investigation and analysis. For,
science is a vital part of our common heritage as a civilisation, and
what it is, and how it works are matters of historically grounded fact
and philosophical discussion on comparative difficulties relative to those facts, not rulings by any officially established
or de facto "Magisterium." [Moreover, scientists and teachers are as a
rule not at all expert on the detailed ins and outs and resulting
balances on the merits of developments and arguments in the various
schools of thought on philosophy of science over recent decades.]
2
--> As a matter of fairly easily checked fact, the Kansas definition
of 2005, as cited above, reflects longstanding praxis, and the
resulting historic general consensus on what science is and should do; without imposing question-begging agendas.
This can easily be seen from a look at the sorts of summaries we
may read in high quality dictionaries from before the recent attempted
imposition of methodological naturalism as an alleged criterion of
science vs. non-science or pseudo-science.
3
--> Further to this, I happen to be a reasonably philosophically
literate, scientifically trained person who has worked in science and
technology education at secondary and tertiary level. Pardon my
ignorance if that is what is reflected in my own thoughts on the subject of defining and teaching science, but I must confess that I fail to see
which part of good and historically well-warranted scientific praxis
over the past three or so centuries is not properly reflected in the
2005 statement: “Science is
a systematic method of continuing investigation, that uses observation,
hypothesis testing, measurement, experimentation, logical argument and
theory building, to lead to more adequate explanations of natural phenomena.”
4 --> The phrase on "blurring
the line between scientific and other ways of understanding . .
." reflects, at best, a deep and disqualifying ignorance by the
representatives of the NAS and NSTA of the overall result after decades of intense philosophical debate over the demarcation lines between science and non-science. For, there
is no set of distinctive approaches to acquiring knowledge and
understanding or inferring to best explanation that are universal
across the conventionally accepted list of sciences, and/or that are so
necessary to, sufficient for and unique to scientific investigation and argument
that we may use them to mark a defining line between science and non-science. (For that matter, the real epistemological challenge
is not over attaching the prestigious label "science," but over [1]
whether we are using sound, effective, reliable and fair methods of
inquiry, and [2] the actual degree of warrant that attaches to what we
accept as knowledge, however labelled.)
5
--> Yet further, when coupled with the non-disclosure by the two
bodies of the effect of imposing the rule that science may only
seek "natural causes," such agenda-serving questionable demarcation criteria
mislead and can even manipulate the general public on the true status
of the relevant theories and factual claims being made on origins
science. For, the public at large still believes that science is an unfettered search for the truth about the world in light of evidence, instead of being what the rule enforces: the best evolutionary materialist -- note the censoring constraint -- explanation of the cosmos from hydrogen to humans. Non-disclosure
of the effects of such an imposition on the part of responsible parties
who know or should know better ["ignorance of the law is no excuse"],
on even the most charitable interpretation, must raise questions of
deception by gross and culpable negligence. (Such should therefore
pause and reflect soberly on "the definition" of this F-word.)
6
--> Next, it is simply and manifestly false that the [Neo-]
Darwinian Theory of Evolution is in the same well-tested, abundantly
empirically supported category as, say, Newtonian gravitation and
mechanics circa 1680 - 1880. (And,
let us observe: after
about 200 years of being the best supported and most successful
scientific theory, the Newtonian synthesis collapsed into being a
limiting case at best, in light of
unexpected findings in the world of the very small and the very fast;
provoking a scientific revolution from about 1900 to 1930 that
resulted in Modern Physics. Science is open-ended, provisional and
hopefully progressive. A pattern of progress in which theory replacement is at least as prominent as theory refinement.)
7 --> For, Newtonian dynamics was and is about currently and directly observable phenomena, i.e. so-called operational science: what are the evident patterns and underlying ordering principles of the currently operating, observable natural world?
8 --> By contrast, the material part of the Theory of Evolution -- we are not
talking about what has been termed microevolution -- is about
trying to make a "plausible" reconstruction
of an unobservable, projected remote past of life based on traces in the present and
on extrapolation of currently observed or "reasonable" processes and
principles. That is, it is an origins science, a fundamentally historical
investigation based on principles of inference to best explanation. Its
findings and explanations on the reconstructed, extrapolated and projected natural history of
life are thus inherently
less well tested than those of theories that deal with present
accessible and directly observable reality. Further to this, once
we observe that in developing or
studying any reasonably complex scientific theory, one is forced to
rely on the credibility of records, testimony, memories and other
traces of an unrepeatable past, one can see -- per point 4 just above -- that, on pain of Simon Greenleaf's selective hyperskepticism,
no wedge can properly be pushed between the methods of what are
conventionally labelled sciences and historical-forensic or other
serious objective investigations carried out by finite, fallible,
sometimes mistaken (or even ill-willed, or biased and/or outright
deceptive) human beings.]
9 --> So also, the
too often seen tendency to over-claim the degree of warrant for
evolutionary reconstructions of the remote past naturally
provokes controversies, especially where rhetorical resort is made (often, in the name of "education") to misleading icons. Therefore, broad-brush dismissive claims such as "all modern theories of science are continually tested and verified" -- i.e. in effect
confirmed as credibly true for practical purposes -- constitute a
highly misleading over-reach. Especially, when these claims are
coupled with the imposition of methodological naturalism and
non-disclosure of its censoring, worldview-level question-begging effects as pointed out at point 5 just above. [NB: Cf. here for remarks by AiG's Dr Jonathan Sarfati on what the much despised Creationists actually teach on this general issue.]
10 -->
Worse yet, given the primary reference in context of "these standards,"
all of this is backed up by a subtle -- and on the evidence of events
since 2005, successful -- unjustifiable intimidatory threat. For, it is
simply not true that students exposed to the traditional, historically
well-warranted understanding of what good science is (and/or should strive
to be) "will not be well-prepared for the rigors of higher education or the demands of an increasingly complex and technologically-driven world."
11 --> Instead, we can note that NAS
and NSTA hold significant prestige, and are viewed by a great many
people and institutions as responsible, reasonable and
authoritative. So, if they
refuse their imprimatur to the Kansas Board's work, then
it could materially damage the prospects for Kansan students to get
into
so-called "good" Colleges, jobs, etc. In short, the
children of the state were being held hostage by ideologised
institutions and associated individuals holding positions of great trust and responsibility,
but abjectly failing in their duties of care to truth, disclosure and justice.
12
--> Moreover, all of this was in a situation where a public relations
person for an oppositional "grassroots" group, Kansas Citizens For
Science [KCFS] in 2005, outlined the
following public relations strategy
on a KCFS online forum. That forum was moderated by a NCSE member-
cum- KCFS leader- cum- state education administrator and Statistics
teacher who sat on the experts committee consulted by the Board in 2004 - 5. In October 2004 this committee evidently suppressed the input of the minority. It is that suppressive action that evidently provoked the whistleblowing minority report that is a highly relevant context for the "breakers of rules" accusation in the just below:
My
strategy at this point is the same as it was in 1999: notify the
national and local media about what's going on and portray them in the
harshest light possible, as political opportunists, evangelical
activists, ignoramuses, breakers of rules, unprincipled bullies, etc.
There may no way to head off another science standards debacle, but we
can sure make them look like asses as they do what they do. Our target is the moderates who are not that well educated about the issues,
most of whom probably are theistic evolutionists. There is no way to
convert the creationists. The solution is really political. [Emphases
added. Note the significance of "[o]ur";
this is not just a personal
observation, but a longstanding strategy of an ideological movement in
dealing with its perceived opponents and the general public, presented
by one of those responsible for its public relations, and who worked
closely with its leadership.]
In short, in our post-/ultra- modern time -- one in which a certain politician, trying to justify himself in the public mind, notoriously said "It depends on what the definition of 'is,' is . . ."
-- the apparently simple question of what science is, is quite
prone to ideological manipulation in service to radical evolutionary
materialistic agendas.
So, we should be forewarned and forearmed.
Now, of course, we plainly do not have the space or
time to now go into a full-orbed tangential essay on the full range of worldview analysis issues and
topics that the above points to, but if we are to responsibly address the design
issue, it is necessary to at least highlight a few core points and
issues relevant to the above. So, it is perhaps best to start with the
intuitively obvious: we think, make decisions, argue as if it matters,
and expect others to respect moral principles such as fairness.
However, if we resort to evolutionary materialist accounts, we soon see
that characteristically, they reduce mentality to little more than an
illusion riding on top of "real" brain chemistry and neuronal activity,
and that there is an unbridgeable gap between the is and the ought:
what we do and what we thing we (or others!) should do.
As a result, there are serious gaps issues to be
faced by advocates of such a view, and to be pondered by the rest of
us, too:
1] Origin
and credibility of a reliable mind that you need to think
through these matters. (Here one must consider both the issues of
determinism and/or random noise and chance boundary conditions as the
root of "thinking" and the
question of getting the link between a world of the conscious, deciding
mind as we experience it and the naturalistic proposed world of
physical objects where mind reduces to one form or another of an
illusion that can have no effect on the physical world. Consider
especially the issue that our
direct intuitive knowledge that we think,
decide and act may well be more certain than the theories that imply
that such an experience is in effect an illusion, for thoughts and
decisions are driven by deterministic and/or random forces.
If that is
so, how can you trust the chains of thought and reasoning that may have
led you to decide to accept naturalism as true?)
2] Origin of a
cosmos that is so exquisitely and finely balanced as a locus
for life that it naturally raises the issue of intentional design by an
agent powerful and wise enough to pull it off successfully. If this is
logically on the table, can we properly use demarcation arguments to
rule it out of consideration? Should we not instead point out to
students and the general public that science exists within a wider
grand discourse of the ages, i.e. philosophy?
3] Origin and
diversification of life within the ambit of the observed
cosmos, given the complexity and integrated functionality of the
molecular machinery involved, as well as associated issues of getting
to such complexity through chance initial conditions and processes, plus associated known
natural laws such as those of thermodynamics. (Cf Voie's analysis here.)
4] The
validity of morals, again relative to evolutionary
materialist premises. [Note that quite often, advocates of evolutionary
materialism are expecting
us to believe in and act
according to binding moral principles. Okay, on such premises, where do
these principles come from? And, why should they be regarded as binding
-- apart from something that in the end sounds suspiciously
like: "might makes right"?]
This
cluster of challenges brings back into focus a line of philosophical thought
that is often unwelcome in current discourse among many who consider
themselves educated. As William Lane Craig put
the cosmological challenge:
We can summarize our argument as follows:
1. Whatever exists has a reason for its existence,
either in the necessity of its own nature or in an external ground.
2. Whatever begins to exist is
not necessary in its existence. [Here, we advert to both the evident
beginning of the observed universe and its fine-tuning as just
discussed.]
3. If the [observed]
universe [which is generally
viewed by cosmologists as originating in a "big bang" some
13.7 BYA] has an external ground of its existence, then there exists a
Personal Creator of the universe, who, sans the universe, is timeless,
spaceless, beginningless, changeless, necessary, uncaused, and
enormously powerful.
[NOTE: For, impersonal but deterministic causes
will produce a result as soon as they are present, e.g. as soon as
heat, fuel and oxidiser are jointly present, a fire bursts into being.
That is, it takes an agent cause to act in a structured fashion at a
particular beginning-point. See (4) below on the idea of sub-universes
popping up at random in an underlying infinite,
eternal universe as a whole.]
4. The [observed]
universe began to exist.
[NOTE:
To deny this, one in effect must propose a
speculative, eternally existing wider universe as a whole; in which
sub-universes (such as our own) pop up more or less at random. This, of
course is not at all what we have actually observed. Such a resort thus
brings out the underlying speculative -- and after-the-fact --
metaphysics embedded in such "multiverse" proposals. In light of (3)
just above, it also requires that points in the wider universe throw up
expanding sub-universes at random. But, when this
is wedded to the infinite proposed age, as Craig points
out, it leads to the issue that every point in that
wider universe as a whole should have birthed a sub-universe in
infinite time. Thus, we should see multiple expansions in our
zone of space, not just the observed number: one.
Similarly,the idea of sub-universes randomly budding off from earlier
expansions still implies a beginning, and the resort to imaginary time
is a mathematical device, one that collapses back into requiring a
beginning as soon as we get back to real time and space. In turn, there
is an even more specific speculation: multiple, independent,
non-interacting (and presumably undetectable) space-time domains --
but, how could we know of such, relative to
empirical tests? It also leads to the issue Leslie raised: this local,
observed domain exhibits the characteristics of the
lone fly on the wall suddenly hit by a bullet. And so on, as an
ad hoc patchwork slowly but surely emerges out of the
evolutionary materialist system. In short, the better approach to
explanation is to take the one observed, finely tuned universe and its
evident beginning seriously.]
From (2) and (4) it follows that
5. Therefore, the universe is not necessary in its
existence.
From (1) and (5) it follows further that
6. Therefore, the universe has an external ground
of its existence.
From (3) and (6) it we can conclude that
7. Therefore, there exists a Personal Creator of
the universe, who, sans the universe, is timeless, spaceless,
beginningless, changeless, necessary, uncaused, and enormously
powerful.
And this, as Thomas Aquinas laconically
remarked,{67} is what everybody means by God.
So, we are forced in the end to address the issue
of the worldview implications of what we have discovered over the past
century through science: (1) the observed universe shows abundant
evidence that it is finetuned for life, which (2) is itself based on a
tightly integrated and complex information system, and both have (3) a
beginning, so neither the universe nor life in it constitutes a
necessary being.
So, what best explains that?
CONCLUSION:
It is clear that the issue of FSCI cannot be easily brushed
aside, and should be soberly considered -- as Cicero long ago counselled -- before coming to a
conclusion for oneself. Nor should one allow him-/her- self to be
intimidated by those who claim "expertise," when issues as profound as
God and our nature as human beings are potentially on the table. Nor,
should we be impressed by question-begging attempted redefinitions of
science -- even when backed by impressive-sounding arguments and major
credentialled scientific institutions. For, the question of origins and
associated issues over inference to design in light of the existence of
FSCI are too big and serious to be left to the scientists and
philosophers, the rest of us then just taking their declarations at
face value. I therefore trust that the above notes (which present at
hopefully a relatively simple level an overview of
the side of the issue that is too often dismissed with contempt and
distortion), will be helpful to you as you think about these points for
oneself.
Also, it is worth citing another classical author
in this context, Paulo
Apostolo Mart; not least, as a caution that our thoughts on
these matters may not be as objective on the matters in the above as we
wish to imagine:
Rom
1:19 . . . what may be known about God is plain to them, because God
has made it plain to them. 20 For since the creation of the world God's
invisible qualities--his eternal power and divine nature--have been
clearly seen, being understood from what has been made, so that men are
without excuse.
RO 1:21 For although they knew God, they
neither glorified him as God nor gave thanks to him, but their thinking
became futile and their foolish hearts were darkened. 22 Although they
claimed to be wise, they became fools 23 and exchanged the glory of the
immortal God for images made to look like mortal man and birds and
animals and reptiles [yesteryear, in temples, today,
often in museums, magazines, textbooks and on TV] . . . .
RO
1:28 . . . since they did not think it worthwhile to retain
the knowledge of God, he gave them over to a depraved mind, to do what
ought not to be done. 29 They have become filled with every kind of
wickedness, evil, greed and depravity. They are full of envy, murder,
strife, deceit and malice. They are gossips, 30 slanderers, God-haters,
insolent, arrogant and boastful; they invent ways of doing evil; they
disobey their parents; 31 they are senseless, faithless, heartless,
ruthless. 32 Although they know God's righteous decree that those who
do such things deserve death, they not only continue to do these very
things but also approve of those who practice them.
RO
2:6 God "will give to each person according to what he has done." 7 To
those who by persistence in doing good seek glory, honor and
immortality, he will give eternal life. 8 But for those who are
self-seeking and who reject the truth and follow evil, there will be
wrath and anger. 9 There will be trouble and distress for every human
being who does evil . . . 10 but glory, honor and peace for everyone
who does good . . . 11 For God does not show favoritism . . .
. 14 (Indeed, when [men without the Scriptures] . . . do by
nature things required by the [biblical] law, they . . . 15 . . . show
that the requirements of the law are written on their hearts, their
consciences also bearing witness, and their thoughts now accusing, now
even defending them.) . . . .
RO
13:8 Let no debt remain outstanding, except the continuing debt to love
one another, for he who loves his fellowman has fulfilled the law. 9
The commandments, "Do not commit adultery," "Do not murder," "Do not
steal," "Do not covet," and whatever other commandment there may be,
are summed up in this one rule: "Love your neighbor as yourself." 10
Love does no harm to its neighbor. Therefore love is the fulfillment of
the law.
Food for thought. Feel free to drop me a line, here.
APPENDIX
1:
On
Thermodynamics, Information and
Design
This
is the side of the issue that gets technical the fastest of all, hence
relegation to an appendix.
Let us reflect on a
few remarks on the link from thermodynamics to information:
1] TMLO:
In 1984, this well-received work provided the breakthrough critical
review on the origin of life that led to the modern design school of
thought in science. The three online chapters, as just linked, should
be carefully read to understand why design thinkers think that the
origin of FSCI in biology is
a significant and unmet challenge to neo-darwinian thought. (Cf also Klyce's
relatively serious and balanced assessment, from a panspermia
advocate. Sewell's remarks here
are also worth reading. So is Sarfati's discussion of Dawkins' Mt Improbable.)
2] But open systems can increase their
order: This is the "standard" dismissal argument on
thermodynamics, but it is both fallacious
and often resorted to by those who should know better. My own note on
why this argument should be abandoned is:
a] Clausius is the founder of the 2nd law, and the
first standard example of an isolated system -- one that allows neither
energy nor matter to flow in or out -- is instructive, given the
"closed" subsystems [i.e. allowing energy to pass in or out] in it.
Pardon the substitute for a real diagram, for now:
Isol System:
| | (A, at Thot) --> d'Q, heat
--> (B, at T cold) | |
b] Now, we introduce entropy change dS >/=
d'Q/T . . . "Eqn" A.1
c] So, dSa >/= -d'Q/Th, and dSb >/=
+d'Q/Tc, where Th > Tc
d] That is, for system, dStot >/= dSa + dSb
>/= 0, as Th > Tc . . . "Eqn" A.2
e] But, observe: the subsystems A
and B are open to energy inflows and outflows, and the entropy of B
RISES DUE TO THE IMPORTATION OF RAW ENERGY.
f] The key point is that when raw energy
enters a body, it tends to make its entropy rise. This can be envisioned on a simple model of a gas-filled box with piston-ends at the left and the right:
=================================
||::::::::::::::::::::::::::::::::::::::::::||
||::::::::::::::::::::::::::::::::::::::::::||===
||::::::::::::::::::::::::::::::::::::::::::||
=================================
1: Consider a box as above, filled with tiny perfectly hard marbles [so collisions will be elastic], scattered
similar to a raisin-filled Christmas pudding (pardon how the textual
elements give the impression of a regular grid, think of them as
scattered more or less hap-hazardly as would happen in a cake).
2: Now, let the marbles all be at rest to begin with.
3: Then, imagine that a layer of them up against the leftmost wall were
given a sudden, quite, quite hard push to the right [the left and right ends are
pistons].
4: Simply on Newtonian physics, the moving balls would begin to collide with the marbles to their
right, and in this model perfectly elastically. So, as they hit, the
other marbles would be set in motion in succession. A wave of motion would begin, rippling from left to right
5:As the glancing angles on collision will vary at random, the marbles hit and the original marbles
would soon begin to bounce in all sorts of directions. Then, they would also deflect
off the walls, bouncing back into the body of the box and other marbles, causing the motion to continue indefinitely.
6: Soon, the marbles will be continually moving in all sorts of directions, with
varying speeds, forming what is called the Maxwell-Boltzmann
distribution, a bell-shaped curve.
7: And, this pattern would emerge independent
of the specific initial arrantgement or how we impart motion to it, i.e.
this is an attractor in the phase space: once the marbles are set in motion
somehow, and move around and interact, they will soon enough settle into
the M-B pattern. E.g. the same would happen if a small charge of
explosive were set off in the middle of the box, pushing our the balls
there into the rest, and so on. And once the M-B pattern sets in, it
will strongly tend to continue. (That is, the process is ergodic.)
8: A pressure would be exerted on the walls of the box by the average force per unit area from collisions
of marbles bouncing off the walls, and this would be increased by
pushing in the left or right walls (which would do work to push in
against the pressure, naturally increasing the speed of the marbles just
like a ball has its speed increased when it is hit by a bat going the
other way, whether cricket or baseball). Pressure rises, if volume goes down due to compression. (Also, volume of a gas body is not fixed.)
9: Temperatureemerges
as a measure of the average random kinetic energy of the
marbles in any given direction, left, right, to us or away from us.
Compressing the model gas does work on it, so the internal energy
rises, as the average random kinetic energy per degree of freedom
rises. Compression will tend to raise temperature. (We could actually
deduce the classical — empirical — P, V, T gas laws [and variants] from
this sort of model.)
10: Thus, from the implications of classical, Newtonian physics, we soon
see the hard little marbles moving at random, and how that randomness gives
rise to gas-like behaviour. It also shows how there is a natural
tendency for systems to move from more orderly to more disorderly
states, i.e. we see the outlines of the second law of thermodynamics.
11: Is the motion really random? First, we define randomness in the relevant sense:
In probability and statistics, a random process is a repeating process whose outcomes follow no describable deterministic pattern, but follow a probability distribution,
such that the relative probability of the occurrence of each outcome
can be approximated or calculated. For example, the rolling of a fair
six-sided die in neutral conditions may be said to produce random
results, because one cannot know, before a roll, what number will show
up. However, the probability of rolling any one of the six rollable
numbers can be calculated.
12:
This can be seen by the extension of the thought experiment of
imagining a large collection of more or less identically set up boxes,
each given the same push at the same time, as closely as we can make
it. At first, the marbles in the boxes will behave very much alike, but
soon, they will begin to diverge as to path. The same overall pattern
of M-B statistics will happen, but each box will soon be going its own
way. That is, the distribution pattern is the same but the specific behaviour in
each case will be dramatically different.
13: Q: Why?
14: A:
This is because tiny, tiny differences between the boxes, and the
differences in the vibrating atoms in the walls and pistons, as well as
tiny irregularites too small to notice in the walls and pistons will
make small differences in initial and intervening states -- perfectly
smooth boxes and pistons are an unattainable ideal. Since the system is
extremely nonlinear, such small differences will be amplified, making
the behaviour diverge as time unfolds. A chaotic system is not
predictable in the long term. So, while we can deduce a probabilistic
distribution, we cannot predict the behaviour in detail, across time.
Laplace's demon who hoped to predict the future of the universe from
the covering laws and the initial conditions, is out of a job.
15: To see diffusion in action, imagine that at the beginning, the balls
in the right half were red, and those in the left half were black. After
a little while, as they bounce and move, the balls would naturally mix
up, and it would be very unlikely indeed — through logically possible —
for them to spontaneously un-mix, as the number of possible combinations
of position, speed and direction where the balls are mixed up is vastly
more than those where they are all red to the right, all alack to the
left or something similar.
(This can be calculated, by breaking the box up into tiny little cells
such that they would have at most one ball in them, and we can analyse
each cell on occupancy, colour, location, speed and direction of motion.
thus, we have defined a phase or state space, going beyond a mere
configuration space that just looks at locations.)
16: So, from the orderly arrangement of laws and patterns of initial
motion, we see how randomness emerges through the sensitive dependence
of the behaviour on initial and intervening conditions. There would be
no specific, traceable deterministic pattern that one could follow or predict for the
behaviour of the marbles, through we could work out an overall
statistical distribution, and could identify overall parameters such as
volume, pressure and temperature.
17: For Osmosis, let us imagine that the balls are of different size, and
that we have two neighbouring boxes with a porous wall between them; but
only the smaller marbles can pass through the holes. If the smaller
marbles were initially on say the left side, soon, they would begin to
pass through to the right, until they were evenly distributed, so that
on average as many small balls would pass left as were passing right,
i.e., we see dynamic equilibrium. [this extends to evaporation and the
vapour pressure of a liquid, once we add in that the balls have a
short-range attraction that at even shorter ranges turns into a sharp
repulsion, i.e they are hard.]
18:
For a solid, imagine that the balls in the original box are now
connected through springs in a cubical grid. The initial push will now
set the balls to vibrating back and forth, and the same pattern of
distributed vibrations will emerge, as one ball pulls on its neigbours
in the 3-D array. (For a liquid, allow about 3% of holes in the grid,
aned let the balls slide over one another, making nes connextions, some
of them distorted. The fixed volume but inability to keep a shape that
defines a liquid will emerge. The push on the liquid will have much the
same effect as for the solid, except that it will also lead to flows.)
19:
Randomness is thus credibly real, and naturally results from work on or
energy injected into a body composed of microparticles, even in a
classical Newtonian world; whether it is gas, solid or liquid. Raw
injection of energy into a body tends to increase its disorder, and
this is typically expressed in its temperature rising.
20: Quantum theory adds to the picture, but the
above is enough to model a lot of what we see as we look at bulk and
transport properties of collections of micro-particles.
21: Indeed, even
viscosity comes out naturally, as . . . if there are are boxes stacked top and
bottom that are sliding left or right relative to one another, and
suddenly the intervening walls are removed, the gas-balls would tend to
diffuse up and down from one stream tube to another, so their drift
verlocities will tend to even out, The slower moving stream tubes exert a
dragging effect on the faster moving ones.
22: And many other phenomena can be similarly explained and applied,
based on laws and processes that we can test and validate, and their
consequences in simplified but relevant models of the real world.
23:
When we see such a close match, especially when quantum principles are
added in, it gives us high confidence that we are looking at a map of
reality. Not the reality itself, but a useful map. And, that map tells
us that thanks to sensitive dependence on initial conditions,
randomness will be a natural part of the micro-world, and that when
energy is added to a body its randomness tends to increase, i.e we see
the principle of entropy, and why simply opening up a body to receive
energy is not going to answer to the emergence of funcitonal internal
organisation.
24:
For, organised states will be deeply isolated in the set of possible
configurations. Indeed, if we put a measure of possible configurations
in terms of say binary digits, bits, if we have 1,000 two-state
elements there are already 1.07*10^301 possible configs. The whole
observed universe searching at one state per Planck time, could not go
through enough states of its 10^80 or so atoms, across its
thermodynamically credible lifespan -- about 50 mn times the 13.7 BY
said to have elapsed form the big bang -- to go through more than
about 10^150 states. That is, the whole cosmos could not search more
than a negligible fraction of the space. The hay stack could be
positively riddled with needles, but at that rate we have not had any
serious search at all..
25: That is, there is
a dominant distribution, not a detailed plan a la Laplace’s (finite)
Demon who could predict the long term path of the world on its initial
conditions and sufficient calculating power and time.
26: But equally, since short term
interventions that are subtle can have significant effects, there is
room for the intelligent and sophisticated intervention; e.g. through a
Maxwell’s Demon who can spot faster moving and slower moving molecules
and open/shut a shutter to set one side hotter and the other colder in a
partitioned box. Providing he has to take active steps to learn which
molecules are moving faster/slower in the desired direction, Brillouin
showed that he will be within the second law of thermodynamics.
. . . So, plainly, for the
injection of energy to instead do predictably and consistently do something useful, it needs to be
coupled to an energy conversion device.
g] When such energy conversion devices, as in the cell, exhibit FSCI,
the question of their origin becomes material, and in that context,
their spontaneous origin is strictly logically possible but -- from the above -- negligibly
different from zero probability on the gamut of the observed cosmos.
(And, kindly note: the
cell is an energy importer with an internal energy converter.
That is, the appropriate entity in the model is B and onward B' below.
Presumably as well, the prebiotic soup would have been energy
importing, and so materialistic chemical evolutionary scenarios
therefore have the challenge to credibly account for the origin of the
FSCI-rich energy converting mechanisms in the cell relative to Monod's
"chance + necessity" [cf also Plato's
remarks] only.)
h] Now, as just mentioned, certain bodies have in
them energy conversion devices:
they COUPLE input
energy to subsystems that harvest some of the energy to do work,
exhausting sufficient waste energy to a heat sink that the overall
entropy of the system is increased. Illustratively, for heat engines --
and (in light of exchanges with email correspondents circa March 2008)
let us note: a
good slice of classical thermodynamics arose in the context of
studying, idealising and generalising from steam engines [which exhibit
organised, functional complexity,
i.e FSCI; they
are of course artifacts of intelligent design and also exhibit
step-by-step problem-solving processes (even including "do-always"
looping!)]:
| | (A, heat source: Th): d'Qi -->
(B', heat engine, Te): -->
d'W [work done on say D] +
d'Qo --> (C, sink at Tc) | |
i] A's entropy: dSa >/= - d'Qi/Th
j] C's entropy: dSc >/= + d'Qo/Tc
k] The rise in entropy in B, C and in the object on
which the work is done, D, say, compensates for that lost from A. The
second law -- unsurprisingly, given the studies on steam engines that
lie at its roots -- holds for heat engines.
l] However for B since it now couples energy into
work and exhausts waste heat, does not necessarily undergo a rise in
entropy having imported d'Qi. [The problem is to explain the origin
of the heat engine -- or more generally, energy converter --
that does this, if it exhibits FSCI.]
m] There is also a material difference between the
sort of heat engine [an instance of the energy conversion device
mentioned] that forms spontaneously as in a hurricane [directly driven
by boundary conditions in a convective system on the planetary scale,
i.e. an example of order], and the sort of complex,
organised, algorithm-implementing energy conversion device
found in living cells [the DNA-RNA-Ribosome-Enzyme system, which
exhibits massive FSCI].
n] In short, the
decisive problem is the [im]plausibility of the ORIGIN of such a
FSCI-based energy converter
through causal mechanisms traceable only to chance conditions and
undirected [non-purposive] natural forces. This problem
yields a conundrum for chem evo scenarios, such that inference to
agency as the probable cause of such FSCI -- on the direct import of
the
many cases where we do directly know the causal story of FSCI --
becomes the better
explanation. As TBO say, in bridging from a survey of the basic
thermodynamics of living systems in CH 7,
to that more focussed discussion in ch's 8 - 9:
While
the maintenance of living systems is easily rationalized in terms of
thermodynamics, the origin of such living systems
is quite another matter. Though the earth is open to energy flow from
the sun, the means of converting this energy into the necessary work to
build up living systems from simple precursors remains at present
unspecified (see equation 7-17). The "evolution" from biomonomers of to
fully functioning cells is the issue. Can one make the incredible jump
in energy and organization from raw material and raw energy, apart from
some means of directing the energy flow through the system?
In Chapters 8 and 9 we will consider this question, limiting our
discussion to two small but crucial steps in the proposed evolutionary
scheme namely, the formation of protein and DNA from their precursors.
It is widely agreed that both protein and DNA are essential for living
systems and indispensable components of every living cell today.11
Yet they are only produced by living cells. Both types of molecules are
much more energy and information rich than the biomonomers from which
they form. Can one reasonably predict their occurrence given the
necessary biomonomers and an energy source? Has this been verified
experimentally? These questions will be considered . . . [Bold emphasis
added. Cf summary in the peer-reviewed journal of the American
Scientific Affiliation, "Thermodynamics
and the Origin of Life," in Perspectives
on Science and Christian Faith 40 (June 1988): 72-83, pardon
the poor quality of the scan. NB:as the
journal's online issues will show, this is not necessarily a "friendly
audience."]
3] So
far we have worked out of a more or less classical view of the subject.
But, to explore such a question further, we need to look more deeply at
the microscopic level. Happily, there
is a link from macroscopic thermodynamic concepts to the
microscopic, molecular view of matter, as worked out by Boltzmann and
others, leading to the
key equation:
s = k
ln W . . . Eqn.A.3
That is, entropy
of a specified macrostate [in effect, macroscopic description
or specification] is a constant times a log measure of the number of
ways matter and energy can be distributed at the micro-level consistent
with that state [i.e. the number of associated microstates; aka "the
statistical weight of the macrostate," aka "thermodynamic probability"].
The point is, that there are as a rule a great many ways for energy and
matter to be arranged at micro level relative to a given observable
macro-state. That is,
there is a "loss of information" issue here on going from specific
microstate to a macro-level description, with which many microstates
may be equally compatible. Thence, we can see that if we
do not know the microstates specifically enough, we have to more or
less treat the micro-distributions of matter and energy as random,
leading to acting as though they are disordered. Or, as Leon Brillouin,
one of the foundational workers in modern information theory, put it in his 1962
Science and
Information Theory, Second Edition:
How
is it possible to formulate a scientific theory of information? The
first requirement is to start from a precise definition. . . .
. We consider a problem involving a certain number of possible
answers, if we have no special information on the actual situation.
When we happen to be in possession of some information on the problem,
the number of possible answers is reduced, and complete information may
even leave us with only one possible answer. Information is a
function of the ratio of the number of possible answers before and
after, and we choose a logarithmic law in order to insure additivity of
the information contained in independent situations [as seen above in the main body, section A] . . . .
Physics enters the picture when
we discover a remarkable likeness between information and entropy.
This similarity was noticed long ago by L. Szilard, in an old paper of
1929, which was the forerunner of the present theory. In this paper,
Szilard was really pioneering in the unknown territory which we are now
exploring in all directions. He investigated the problem of Maxwell's
demon, and this is one of the important subjects discussed in this
book. The connection between information and entropy was rediscovered
by C. Shannon in a different class of problems, and we devote many
chapters to this comparison. We
prove that information must be considered as a negative term in the
entropy of a system; in
short, information is negentropy. The entropy of a
physical system has often been described as a measure of randomness in
the structure of the system. We can now state this result
in a slightly different way:
Every
physical system is incompletely defined. We only know the values of some
macroscopic variables, and we
are unable to specify the exact positions and velocities of all the
molecules contained in a system. We have only scanty,
partial information on the system, and most of the information on the
detailed structure is missing. Entropy
measures the lack of information; it gives us the total amount of
missing information on the ultramicroscopic structure of the system.
This point of
view is defined as the
negentropy principle of information [added links: cf.
explanation here
and "onward" discussion here --
noting on the brief, dismissive critique of Brillouin there, that you
never get away from the need to provide information -- there is "no
free lunch," as Dembski has pointed out ; ->) ], and it
leads directly to a generalization of the second principle of
thermodynamics, since entropy and information must, be discussed
together and cannot be treated separately. This negentropy
principle of information will be justified by a variety of examples
ranging from theoretical physics to everyday life. The essential point
is to show that any observation or experiment made on a physical system
automatically results in an increase of the entropy of the laboratory. It is then possible to compare
the loss of negentropy (increase of entropy) with the amount of
information obtained. The efficiency of an experiment can be defined as
the ratio of information obtained to the associated increase in
entropy. This efficiency is always smaller than unity, according to the
generalized Carnot principle. Examples show that the
efficiency can be nearly unity in some special examples, but may also
be extremely low in other cases.
This
line of discussion is very useful in a comparison of fundamental
experiments used in science, more particularly in physics. It leads to
a new investigation of the efficiency of different methods of
observation, as well as their accuracy and reliability . . . . [From an
online excerpt of the Dover Reprint edition, here.
Emphases, links and bracketed comment added.]
4] Yavorski and Pinski, in the textbook Physics, Vol I [MIR,
USSR, 1974, pp. 279 ff.], summarise the key implication of the
macro-state and micro-state view well: as we consider a simple model of
diffusion, let us think of ten white and ten black balls in two rows in
a container. There is of course but one way in which there are ten
whites in the top row; the balls of any one colour being for our
purposes identical. But on shuffling, there are 63,504 ways to arrange
five each of black and white balls in the two rows, and 6-4
distributions may occur in two ways, each with 44,100 alternatives. So,
if we for the moment see the set of balls as circulating among the
various different possible arrangements at random, and spending about
the same time in each possible state on average, the time the system
spends in any given state will be proportionate to the relative number
of ways that state may be achieved. Immediately, we see that the system
will gravitate towards the cluster of more evenly distributed states.
In short, we have just seen that there
is a natural trend of change at
random, towards the more thermodynamically probable macrostates,
i.e
the ones with higher statistical weights. So "[b]y comparing the
[thermodynamic] probabilities of two states of a thermodynamic system,
we can establish at once the direction of the process that is
[spontaneously] feasible in the given system. It will correspond to a
transition from a less
probable to a more
probable state." [p. 284.] This is in effect the
statistical form of the 2nd law of thermodynamics. Thus,
too, the behaviour of the
Clausius isolated system above is readily understood: importing d'Q of
random molecular energy so far increases the number of ways energy can
be distributed at micro-scale in B, that the resulting rise in B's
entropy swamps the fall in A's entropy. Moreover,
given that FSCI-rich micro-arrangements are relatively rare in the set
of possible arrangements, we can also see why it is hard to account for
the origin of such states by spontaneous processes in the scope of the
observable universe. (Of
course, since it is as a rule very inconvenient to work in terms of
statistical weights of macrostates [i.e W], we instead move to entropy,
through s = k ln W. Part of how this is done can be seen by
imagining a system in which there are W ways accessible, and imagining
a partition into parts 1 and 2. W = W1*W2,
as for
each arrangement in 1 all accessible arrangements in 2 are possible and
vice versa, but it is far more convenient to have an additive measure,
i.e we need to go to logs. The constant of proportionality, k, is the
famous Boltzmann constant and is in effect the universal gas constant,
R, on a per molecule basis, i.e we divide R by the Avogadro Number, NA,
to get: k = R/NA.
The two approaches to entropy, by Clausius, and Boltzmann, of course,
correspond. In real-world systems of any significant scale, the
relative statistical weights are usually so disproportionate, that the
classical observation that entropy naturally tends to increase, is
readily apparent.)
5] The
above sort of thinking has also led to the rise of a school of thought
in Physics -- note, much spoken against in some quarters, but I think
they clearly have a point -- that ties information and thermodynamics
together. Robertson presents
their case; in summary:
.
. . It has long been recognized that the assignment of probabilities to
a set represents information, and that some probability sets represent
more information than others . . . if one of the probabilities say p2
is unity and therefore the others are zero, then we know that the
outcome of the experiment . . . will give [event] y2.
Thus we have complete information . . . if we have no basis . . . for
believing that event yi is more or less likely
than any other [we] have the least possible information about the
outcome of the experiment . . . . A remarkably simple and clear
analysis by Shannon [1948]
has provided us with a quantitative measure of the uncertainty, or
missing pertinent information, inherent in a set of probabilities [NB:
i.e. a probability should be seen as, in part, an index of ignorance]
. . . .
[deriving informational entropy, cf. discussions here,
here,
here,
here
and here;
also Sarfati's discussion of debates and open systems here;
the debate here
is eye-opening on rhetorical tactics used to cloud this and related
issues . . . ]
S({pi}) = - C [SUM over i] pi*ln pi, [. . . "my" Eqn
A.4]
[where [SUM over i] pi = 1,
and we can define also parameters alpha and beta such that: (1) pi
= e^-[alpha + beta*yi]; (2) exp [alpha] = [SUM
over i](exp - beta*yi) = Z [Z being in effect the
partition function across microstates, the "Holy Grail" of
statistical thermodynamics]. . . .[pp.3 - 6]
S, called the
information entropy, . . . correspond[s] to the thermodynamic entropy,
with C = k, the Boltzmann constant, and yi an energy level, usually ei,
while [BETA] becomes 1/kT, with T the thermodynamic temperature . . . A
thermodynamic system is characterized by a microscopic structure that
is not observed in detail . . . We attempt to develop a theoretical
description of the macroscopic properties in terms of its underlying
microscopic properties, which are not precisely known. We attempt to
assign probabilities to the various microscopic states . . . based on a
few . . . macroscopic observations that can be related to averages of
microscopic parameters. Evidently the problem that we attempt to solve
in statistical thermophysics is exactly the one just treated in terms
of information theory. It should not be surprising, then, that the
uncertainty of information theory becomes a thermodynamic variable when
used in proper context [p. 7] . . . .
Jayne's
[summary rebuttal to a typical objection] is ". . . The entropy of a
thermodynamic system is a measure of the degree of ignorance of a
person whose sole knowledge about its microstate consists of the values
of the macroscopic quantities . . . which define its thermodynamic
state. This is a perfectly 'objective' quantity . . . it is a function
of [those variables] and does not depend on anybody's personality.
There is no reason why it cannot be measured in the laboratory." . . .
. [p. 36.]
[Robertson, Statistical Thermophysics,
Prentice Hall, 1993. (NB: Sorry for the math and the use of text for
symbolism. However, it should be clear enough that Roberson first
summarises how Shannon derived his informational entropy [though
Robertson uses s rather than the usual H for that information theory
variable, average information per symbol], then ties it to entropy in
the thermodynamic sense using another relation that is tied to the
Boltzmann relationship above. This context gives us a basis for looking
at the issues that surface in prebiotic soup or similar models as we
try to move from relatively easy to form monomers to the more energy-
and information- rich, far more complex biofunctional molecules.)]
6] It is worth pausing to now introduce a
thought
(scenario) experiment that helps underscore the point, by
scaling down to
essentially molecular size the tornado-
in- a- junkyard- forms- a- jet example raised by Hoyle and
mentioned by Dawkins with respect in the just linked excerpt in Section
A above. Then, based on (a) the known behaviour of molecules and
quasi-molecules through Brownian-type
motion
(which, recall, was Einstein's Archimedian point for empirically
demonstrating the reality of atoms), and (b) the also known requirement
of quite precise configurations to get to a flyable micro-jet, we may
(c) find a deeper understanding of what is at stake in the origin of
life question:
NANOBOTS & MICRO-JETS
THOUGHT EXPT:
i] Consider the assembly of a Jumbo Jet, which
requires intelligently designed, physical work in all actual observed
cases. That is, orderly motions were impressed by forces on selected,
sorted parts, in accordance with a complex specification. (I have
already contrasted the case of a tornado in a junkyard that it is
logically and physically possible can do the
same, but the functional
configuration[s] are so rare relative to
non-functional ones that random search strategies are maximally
unlikely
to create a flyable jet, i.e. we see here the logic of the 2nd
Law of Thermodynamics, statistical thermodynamics form, at work.
[Intuitively, since functional configurations are rather isolated in
the space of possible configurations, we are maximally likely to
exhaust available probabilistic resources
long before arriving at such a functional configuration or "island" of
such configurations (which would be required before
hill-climbing through competitive functional selection, a la Darwinian
natural Selection could take over . . . ); if we start from an
arbitrary initial configuration and
proceed by a random walk.])
ii] Now, let us shrink the Hoylean example, to a
micro-jet
so small [~ 1 cm or even smaller] that the parts are susceptible to
Brownian motion, i.e they are of about micron scale [for convenience]
and act as "large molecules." (Cf.
"materialism-leaning 'prof' Wiki's" blowing-up of Brownian motion to
macro-scale by thought expt, here;
indeed, this sort of scaling-up thought experiment was just what the
late, great Sir Fred was doing in his original discussion of 747's.)
Let's say there are about a million of
them, some the same, some different etc. In principle, possible: a key
criterion for a successful thought experiment. Next, do the same for a
car, a boat and a submarine, etc.
iii] In several vats of "a convenient fluid," each
of
volume about a cubic metre, decant examples of the differing mixed sets
of nano-parts; so that the
particles can then move about at random,
diffusing through the liquids as they undergo random thermal
agitation.
iv] In the control vat, we simply leave nature to
its course.
Q: Will a car, a boat a sub or a
jet, etc, or some novel nanotech emerge at random? [Here,
we imagine the parts can cling to each other if they get close enough,
in some unspecified way, similar to molecular bonding; but that the
clinging force is not strong enough at appreciable distances [say 10
microns or more] for them to immediately clump and precipitate instead
of diffusing through the medium.]
ANS:
Logically and physically possible (i.e. this is subtler than having an
overt physical force or potential energy barrier blocking the way!) but
the
equilibrium state will on statistical thermodynamics grounds
overwhelmingly dominate — high disorder.
Q: Why?
A:
Because there are so many more accessible scattered
state microstates than there are clumped-at
-random state ones, or even moreso, functionally
configured flyable jet ones. (To explore this
concept in more details, cf the overviews here
[by Prof Bertrand of U of Missouri, Rolla], and here
-- a well done research term paper by a group of students at
Singapore's NUS. I have extensively discussed on this case with a
contributer to the ARN known as Pixie, here.
Pixie: Appreciation for the time & effort
expended, though of course you and I have reached very different
conclusions.)
v] Now, pour in a cooperative army of nanobots into
one vat, capable of recognising jet parts and clumping them together
haphazardly. [This is of course, work, and it replicates bonding at
random. "Work" is done
when forces move their points of application along
their lines of action. Thus in addition to the quantity of
energy
expended, there is also a specificity of resulting spatial
rearrangement depending on the cluster of forces that have done the
work. This of course reflects the link between "work" in
the physical
sense and "work" in the economic sense; thence, also the energy
intensity of
an economy with a given state of technology: energy
per unit GDP tends to cluster tightly while a given state of technology
and general level of economic activity prevail.
(Current estimate for Montserrat: 1.6 lbs CO2
emitted per EC$ 1 of GDP, reflecting an energy intensity of 6 MJ/EC$,
and the observation that burning one US Gallon of gasoline or diesel
emits about 20 lbs of that gas. Thereby, too, lies
suspended much of the debate over responses to feared climate trends
(and the ironies shown in the 1997, Clinton era Byrd-Hagel
95-0 Senate resolution that
unless certain key "developing" nations also made the sacrifice, the US
would not sign to the Kyoto protocol [they refused to amend the draft
to include non-Annex I countries, and the US has refused to sign;
signatories then have gone on to bust the required emissions cuts . .
.],
but that bit of internationalist
"folly-tricks" and spin-doctoring
is off topic, though illuminating on the concept of work and how it
brings the significance of intelligent direction to bear on energy
flows once we get to the level of building complicated things that
have to function . . .)]
Q: After a time, will we be likely
to get a flyable nano jet?
A:
Overwhelmingly, on probability, no. (For, the vat has ~ [10^6]^3 =
10^18 one-micron locational cells, and a million parts or so can be
distributed across them in vastly more ways than they could be across
say 1 cm or so for an assembled jet etc or even just a clumped together
cluster of micro-parts. [a 1 cm cube has in it [10^4]^3 = 10^12 cells,
and to confine the nano-parts to that volume obviously sharply reduces
the number of accessible cells consistent with the new clumped
macrostate.] But also, since the configuration is
constrained, i.e. the mass in the microjet parts is confined as to
accessible volume by clumping, the number of ways the parts may be
arranged has fallen sharply relative to the number of ways that the
parts could be distributed among the 10^18 cells in the scattered state.
(That is, we have here used the nanobots to essentially undo diffusion
of the micro-jet parts.) The resulting constraint on spatial
distribution of the parts has reduced their entropy of configuration.
For, where W is the number of ways that the components may be arranged
consistent with an observable macrostate, and since by Boltzmann,
entropy, s = k ln W, we see that W has fallen so S too falls on moving
from the scattered to the clumped state.
vi] For this vat, next remove the random cluster
nanobots, and send in the jet assembler nanobots. These recognise the
clumped parts, and rearrange them to form a jet, doing configuration
work. (What this means is that within the cluster of cells for a
clumped state, we now move and confine the parts to those sites
consistent with a flyable jet emerging. That is, we are constraining the volume
in which the relevant individual parts may be found, even
further.) A flyable jet results — a macrostate with a much smaller
statistical weight of microstates. We can see that of course there are
vastly fewer clumped configurations that are flyable than those that
are simply clumped at random, and thus we see that the number
of microstates accessible due to the change, [a] scattered -->
clumped and now [b] onward --> functionally configured
macrostates has fallen sharply, twice in succession.
Thus, by Boltzmann's result s = k ln W, we also have seen that the
entropy has fallen in succession as we moved from one state to the
next, involving a fall in s on clumping, and a further fall on
configuring to a functional state; dS tot = dSclump + dS config. [Of
course to do that work in any reasonable time or with any reasonable
reliability, the nanobots will have to search and exert directed forces
in accord with a program, i.e this is by no means a
spontaneous change, and it is credible that it is accompanied
by a compensating rise in the entropy of the vat as a whole and its
surroundings. This thought experiment is by no means a challenge to the
second law. But, it does illustrate the implications of the
probabilistic reasoning involved in the microscopic view of that law,
where we see sharply configured states emerging from much less
constrained ones.]
vii] In another vat we put in an army of clumping
and assembling nanobots, so we go straight to making a jet based on the
algorithms that control the nanobots. Since entropy is a
state function, we see here that direct assembly is equivalent to
clumping and then reassembling from a random “macromolecule” to a
configured functional one. That is: dS tot (direct) = dSclump
+ dS config.
viii] Now, let us go back to the vat. For a large
collection of vats, let us now use direct microjet assembly nanobots,
but in each case we let the control programs vary at random a few bits
at a time -– say hit them with noise bits generated by a process tied
to a zener noise source. We put the resulting products in competition
with the original ones, and if there is an improvement, we allow
replacement. Iterate, many, many times.
Q: Given the complexity of the
relevant software, will we be likely to for instance come up with a
hyperspace-capable spacecraft or some other sophisticated and
un-anticipated technology? (Justify your answer on
probabilistic grounds.)
My
prediction: we will have to wait longer than the universe
exists to get a change that requires information generation (as opposed
to information and/or functionality loss) on the scale of 500 – 1000 or
more bits. [See the info-generation issue over macroevolution
by RM + NS?]
ix] Try again, this time to get to even the initial
assembly program by chance, starting with random noise on the
storage medium. See the abiogenesis/
origin of life issue?
x] The micro-jet is of course an energy converting
device which exhibits FSCI, and we see from this thought expt why it is
that it is utterly improbable on the same grounds as we base the
statistical view of the 2nd law of thermodynamics, that it should
originate spontaneously by chance and necessity only, without agency.
xi] Extending to the case of origin of life, we
have cells that use sophisticated machinery to assemble the working
macromolecules, direct them to where they should go, and put them to
work in a self-replicating, self-maintaining automaton. Clumping work
[if you prefer that to TBO’s term chemical work,
fine], and configuring work can be identified and applied to the shift
in entropy through the same s = k ln W equation. For, first we move
from scattered at random in the proposed prebiotic soup, to chained in
a macromolecule, then onwards to having particular monomers in
specified locations along the chain -- constraining accessible volume
again and again, and that in order to access observably bio-functional
macrostates. Also, s = k ln W, through Brillouin, TBO link to
information, viewed as "negentropy," citing as well
Yockey-Wicken’s work and noting on their similar definition of
information; i.e this is a natural outcome of the OOL work in the early
1980's, not a "suspect innovation" of the design thinkers in
particular. BTW, the concept complex, specified information is also
similarly a product of the work in the OOL field at that time, it is
not at all a "suspect innovation" devised by Mr Dembski et al, though
of course he has provided a mathematical model for it. [ I have also
just above pointed to Robertson, on why this link from entropy to
information makes sense — and BTW, it also shows why energy converters
that use additional knowledge can couple energy in ways that go beyond
the Carnot efficiency limit for heat engines.]
7] We can therefore see the cogency of
Mathematician, Granville Sewell's observations, here.
Excerpting:
.
. . The second law is all about probability, it uses probability at the
microscopic level to predict macroscopic change: the reason carbon distributes
itself more and more uniformly in an insulated solid is, that is what
the laws of probability predict when diffusion alone is operative. The
reason natural forces may turn a spaceship, or a TV set, or a computer
into a pile of rubble but not vice-versa is also probability: of all
the possible arrangements atoms could take, only a very small
percentage could fly to the moon and back, or receive pictures and
sound from the other side of the Earth, or add, subtract, multiply and
divide real numbers with high accuracy. The second law of
thermodynamics is the reason that computers will degenerate into scrap
metal over time, and, in the absence of intelligence, the reverse
process will not occur; and it is also the reason that animals, when
they die, decay into simple organic and inorganic compounds, and, in
the absence of intelligence, the reverse process will not occur.
The discovery that life on Earth
developed through evolutionary "steps," coupled with the observation
that mutations and natural selection -- like other natural forces --
can cause (minor) change, is widely accepted in the scientific world as
proof that natural selection -- alone among all natural forces -- can
create order out of disorder, and even design human brains, with human
consciousness. Only the layman seems to see the problem with this
logic. In a recent
Mathematical Intelligencer article ["A Mathematician's View of
Evolution," The Mathematical Intelligencer 22, number 4, 5-7, 2000] I
asserted that the idea that the four fundamental forces of physics alone could
rearrange the fundamental particles of Nature into spaceships, nuclear
power plants, and computers, connected to laser printers, CRTs,
keyboards and the Internet, appears to violate the second law of
thermodynamics in a spectacular way.1 . . . .
What happens in a[n isolated]
system depends on the initial conditions; what happens in an open
system depends on the boundary conditions as well. As I wrote in "Can ANYTHING
Happen in an Open System?", "order can increase in an open system, not
because the laws of probability are suspended when the door is open,
but simply because order may walk in through the door....
If we found evidence that DNA, auto parts, computer chips, and books
entered through the Earth's atmosphere at some time in the past, then
perhaps the appearance of humans, cars, computers, and encyclopedias on
a previously barren planet could be explained without postulating a
violation of the second law here . . . But if all we see entering is
radiation and meteorite fragments, it seems clear that what is entering
through the boundary cannot explain the increase in order observed
here." Evolution is a movie running backward, that is what makes it
special.
THE EVOLUTIONIST, therefore, cannot
avoid the question of probability by saying that anything can happen in
an open system, he is finally forced to argue that it only
seems extremely improbable, but really isn't, that atoms would rearrange
themselves into spaceships and computers and TV sets
. . . [NB: Emphases added. I have also substituted in isolated system
terminology as GS uses a different terminology. Cf as well his other
remarks here
and here.]
8] What is the result of applying such
considerations on the link between entropy and information to the issue
of the suggested spontaneous origin of life? TBO in CH 8
set up a model prebiotic soup, on a planetary scale, with quite
generous unimolar concentrations of the required amino acids [L-form
only] to give rise to a hypothetical, relatively simple 100-link,
101-monomer biofunctional protein. Then, using the separability of the
components of entropy, a state function, they work out that there is a
configurational component, which can be estimated.
Taking a step back to their analysis in Ch 7,
which introduces the Gibbs Free Energy they will use:
By
energy conservation: change in internal energy, dE is heat flow into
the system, d'Q plus work done on the system, dW (a "simple" form of
the 1st law of thermodynamics-- never mind mass flows etc for now):
dE
= d'Q + dW . . . [Eqn A.5, cf. TBO 7.1 ]
using
also: dS >/= d'Q/T, and using pressure-volume work of expansion
against a pressure P, so dW = P*dV, we may blend the first and 2nd laws
of thermodynamics:
dS
>/= [dE + PdV]/T . . . ["Eqn" A.6 cf. TBO 7.5]
or,
multiplying through by T: TdS >/= dE + PdV . . .
["Eqn" A.6.1]
Thus:
dE + PdV - TdS </= 0 . . . ["Eqn" A.6.2]
Introducing
the "simplifying" quantities Enthalpy [H] and Gibbs Free energy
[G]:
dH
= dE + PdV . . . "Def'n" (with pressure, P, constant)
-->
NB: if PdV = 0, then increment in enthalpy is the change in the
internal energy of a system. [Thus, the common comment in Chemistry
circles that enthalpy is "heat content": dW = 0, so d'Q = dE + 0 = dH,
at constant pressure, and with no pressure-volume work involved.)
-->
Of course, strictly, H = E + PV, so dE = dH + PdV + VdP, but if P is
constant, VdP = 0. (I give this detail, as there is a common tendency
among Evo Mat
advocates, to suspect, assume, assert or even insist that
Design-friendly thinkers are all hopelessly ignorant on these matters.
An irrelevancy is then trotted out a a "proof" that the argument in the
main can be dismissed. A red herring, leading out to a strawman to be
pummelled.)
dG
= dH - TdS . . . "Def'n" (where T is also effectively constant)
So, dH
- TdS </= 0 . . . ["Eqn" A.6.3]
or,
dG </= 0 . . . ["Eqn" A.6.4, cf. TBO 7.6]
Bringing
in rates, through increment in time, dt, in a closed system:
dG/dt
</= 0 . . . ["Eqn" A.6.5, cf. TBO, 7.7]
Also,
as a system approaches thermodynamic equilibrium under the particular
circumstances obtaining:
dG/dt
--> 0 . . . ["Eqn" A.7, cf. TBO, 7.8]
-->
In other words, decrease in Gibbs free energy as a criterion of
spontaneous process, is in effect the same as saying that entropy
increases in a real world spontaneous process.
Then,
also, we can back-substitute and rearrange to get:
dS/dt
- [dE/dt + PdV/dt]/T >/= 0
i.e.
dS/dt - [dH/dt]/T >/= 0 . . . ["Eqn" A.8]
-->
That is, in spontaneous processes, rate of entropy change in the system
{dS/dt} added to entropy change due to exchange of mechanical or
thermal energy with surroundings {[dH/dt]/T} will be at least zero.
Going forward to the discussion in Ch 8,
in light of the definition dG = dH - Tds, we may then split up the TdS
term into contributing components, thusly:
First,
dG = dE + PdV - TdS . . . [Eqn A.9, cf def'ns for G, H above]
But,
[1] since pressure-volume work may be seen as negligible in the context
we have in mind, and [2] since we may look at dE as shifts in bonding
energy [which will be more or less the same in DNA or
polypeptide/protein chains of the same length regardless of the
sequence of the monomers], we may focus on the TdS term. This brings us
back to the clumping then configuring sequence of changes in entropy in
the Micro-Jets example
above:
dG
= dH - T[dS"clump" +dSconfig] . . . [Eqn A.10, cf. TBO 8.5]
Of
course, we have already addressed the reduction in entropy on clumping
and the further reduction in entropy on configuration, through the
thought expt. etc., above. In the DNA or protein formation case, more
or less the same thing happens. Using Brillouin's negentropy
formulation of information, we may see that the dSconfig is the
negative of the information content of the molecule.
A
bit of back-tracking will help:
S
= k ln W . . . Eqn A.3
Now,
W may be seen as a composite of the ways energy as well as mass may be
arranged at micro-level. That is, we are marking a distinction between
the entropy component due to ways energy [here usually, thermal energy]
may be arranged, and that due to the ways mass may be configured across
the relevant volume. The configurational component arises from in
effect the same considerations as lead us to see a rise in entropy on
having a body of gas at first confined to part of an apparatus, then
allowing it to freely expand into the full volume:
Free
expansion:
||
* * * * * * * * |
||
Then:
||
* * * * *
* * * ||
Or, as Prof Gary L. Bertrand of university of Missouri-Rollo summarises:
The freedom
within a part of the universe may take two major forms: the freedom of
the mass and the freedom of the energy. The amount of freedom is
related to the number of different ways the mass or the energy in that
part of the universe may be arranged while not gaining or losing any
mass or energy. We will
concentrate on a specific part of the universe, perhaps within a closed
container. If the mass within the container is distributed into a lot
of tiny little balls (atoms) flying blindly about, running into each
other and anything else (like walls) that may be in their way, there is
a huge number of different ways the atoms could be arranged at any one
time. Each atom could at different times occupy any place within the
container that was not already occupied by another atom, but on average
the atoms will be uniformly distributed throughout the container. If we
can mathematically estimate the number of different ways the atoms may
be arranged, we can quantify the freedom of the mass. If somehow we increase the size
of the container, each atom can move around in a greater amount of
space, and the number of ways the mass may be arranged will increase .
. . .
The thermodynamic term for quantifying freedom is entropy, and it is
given the symbol S. Like freedom, the entropy of a system increases
with the temperature and with volume . . . the entropy of a system
increases as the concentrations of the components decrease. The part of entropy which is
determined by energetic freedom is called thermal entropy, and the part
that is determined by concentration is called configurational
entropy."
In short, degree
of confinement in space constrains the degree of disorder/"freedom"
that masses may have. And, of course, confinement to particular
portions of a linear polymer is no less a case of volumetric
confinement (relative to being free to take up any location at random
along the chain of monomers) than is confinement of gas molecules to
one part of an apparatus. And, degree of such confinement
may appropriately be termed, degree of "concentration."
Diffusion is a similar case: infusing a drop of dye
into a glass of water -- the particles spread out across the volume and
we see an increase of entropy there. (The micro-jets case of course is
effectively diffusion in reverse, so we see the reduction in entropy on
clumping and then also the further reduction in entropy on configuring
to form a flyable microjet.)
So,
we are justified in reworking the Boltzmann expression to separate
clumping/thermal and configurational components:
S = k ln (Wclump*Wconfig) = k
lnWth*Wc . . . [Eqn A.11, cf. TBO 8.2a]
or, S = k ln Wth + k ln Wc
= Sth + Sc . . . [Eqn
A.11.1]
We
now focus on the configurational component, the clumping/thermal one
being in effect the same for at-random or specifically configured DNA
or polypeptide macromolecules of the same length and proportions of the
relevant monomers, as it is essentially energy of the bonds in the
chain, which are the same in number and type for the two cases. Also,
introducing Brillouin's
negentropy formulation of Information, with the configured
macromolecule [m] and the random molecule [r], we see the increment in
information on going from the random to the functionally specified
macromolecule:
IB = -[Scm
- Scr] . . . [Eqn A.12, cf. TBO 8.3a]
Or, IB = Scr - Scm = k ln Wcr - k ln Wcm = k ln (Wcr/Wcm) . . . [Eqn A12.1.]
Where
also, for N objects in a linear chain, n1 of one kind, n2 of another,
and so on to ni, we may see that the number of ways to arrange them (we
need not complicate the matter by talking of Fermi-Dirac statistics, as
TBO do!) is:
W
= N!/[n1!n2! . . . ni!] . . . [Eqn A13, cf TBO 8.7]
So, we may look at a 100-monomer protein, with as
an average 5 each of the 20 types of amino acid monomers
along the chain , with the aid of log manipulations -- take logs to
base 10, do the sums in log form, then take back out the logs
-- to handle numbers over 10^100 on a calculator:
Wcr =
100!/[(5!)^20] = 1.28*10^115
For the sake of initial
argument, we consider a unique polymer chain , so that each monomer is
confined to a specified location, i.e Wcm = 1, and
Scm = 0. This yields --
through basic equilibrium of chemical reaction thermodynamics (follow
the onward argument in TBO Ch 8)
and the Brillouin information measure which contributes to estimating
the relevant Gibbs free energies (and with some empirical results on
energies of formation etc) -- an expected protein concentration of
~10^-338 molar, i.e. far, far less than one molecule per planet. (There
may be about 10^80 atoms in the observed universe, with Carbon a rather
small fraction thereof; and 1 mole of atoms is ~ 6.02*10^23 atoms. )
Recall, known life forms routinely use dozens to hundreds of
such information-rich macromolecules, in close proximity in an
integrated self-replicating information system on the scale of about
10^-6 m.
9] Recently, Bradley has done further work on this,
using Cytochrome C, which is a 110-monomer protein. He
reports, for this case (noting along the way that Shannon
information is of course really a metric of information-carrying
capacity and using Brillouin information as a measure of complex
specified information, i.e IB = ICSI
below), that:
Cytochrome
c (protein) -- chain of 110 amino acids of 20 types
If
each amino acid has pi = .05, then average information “i” per amino
acid is given by log2 (20) = 4.32
The
total Shannon information is given by I = N * i = 110 * 4.32 = 475,
with total number of unique sequences “W0” that are possible is W0 =
2^I = 2^475 = 10^143
Amino
acids in cytochrome c are not equiprobable (pi ≠ 0.05) as assumed
above.
If
one takes the actual probabilities of occurrence of the amino acids in
cytochrome c, one may calculate the average information per residue (or
link in our 110 link polymer chain) to be 4.139 using i = - ∑ pi log2
pi [TKI NB: which is related of course to the Boltzmann expression for
S]
Total
Shannon information is given by I = N * i = 4.139 x 110 = 455.
The
total number of unique sequences “W0” that are possible for the set of
amino acids in cytochrome c is given by W0 = 2^455 = 1.85 x 10^137
.
. . . Some amino acid residues (sites along chain) allow several
different amino acids to be used interchangeably in cytochrome-c
without loss of function, reducing i from 4.19 to 2.82 and I (i x 110)
from 475 to 310 (Yockey)
M
= 2^310 = 2.1 x 10^93 = W1
Wo
/ W1 = 1.85 x 10^137 / 2.1 x 10^93 = 8.8 x 10^44
Recalculating for a 39 amino acid racemic prebiotic
soup [as Glycine is achiral] he then deduces (appar., following Yockey):
W1 is calculated to be 4.26 x 10^62
Wo/W1 = 1.85 x 10^137 / 4.26 x 10^62 = 4.35 x 10^74
ICSI = log2 (4.35 x 10^74) = 248
bits
He then compares results from two experimental
studies:
Two
recent experimental studies on other proteins have found the same
incredibly low probabilities for accidental formation of a functional
protein that Yockey found
1
in 10^75 (Strait and Dewey, 1996) and
1
in 10^65 (Bowie, Reidhaar-Olson, Lim and Sauer, 1990).
--> Of course, to make a functioning life
form we need dozens of proteins and other similar information-rich
molecules all in close proximity and forming an integrated system, in
turn requiring a protective enclosing membrane.
--> The probabilities of this
happening by the relevant chance conditions and natural regularities
alone, in aggregate are effectively negligibly different from zero in
the gamut of the observed cosmos.
--> But of course, we know that agents,
sometimes using chance and natural regularities as part of what they
do, routinely produce FSCI-rich systems. [Indeed, that is just what the
Nanobots and Micro-jets thought experiment shows by a conceivable
though not yet technically feasible example.]
10] Ch 9
extends the discussion by exploring different scenarios for getting the
required synthesis through spontaneous mechanisms, circa 1984: chance,
prebiotic "natural selection," self-ordering tendencies, mineral
catalysis, nonlinear non-equilibrium processes, experimental thermal
synthesis, solar energy, energy-rich condensing agents, and energy-rich
precursor molecules. The
results are uniformly fruitless as soon as degree of investigator
involvement is reduced to a credible one relative to the proposed
prebiotic type environment. In the twenty or so
years since, as we just saw in Bradley's updated work, the manner of
addressing the issue has generally shifted towards discussing
information and probabilities more directly: complex, specified
information, probability filters, etc., but as we also saw just above, the result is still more or less
the same. (Cf. the recent peer-reviewed,
scientific discussions here
and here,
by Abel and Trevors, in the context of the origin of the molecular
nanotechnology of life.)
11] In short summary: thermodynamics issues tied to
the second law are both relevant and strongly adverse for the proposed
spontaneous [chance + necessity only] origin of
life in prebiotic conditions; rhetoric to the contrary notwithstanding.
But, at he same time, we know that FSCI, the key
factor in driving that adverse thermodynamics, is routinely produced by
intelligent agents. Thus, based on what we do
directly know about the source of FSCI in every case where we observe
or experience its origin, the origin of the FSCI-rich nanotechnologies
of life in the cell is best explained as the product of agency. (The
further issue of identification of the agency/agencies directly or
indirectly involved, of course, is not currently within the ambit of
science, proper. A suggestive clue, however is to be found in the
similarly fine-tuned observed cosmos, which is "set" so that biological
life as we know it becomes possible. This is discussed supra.
Related philosophical issues are addressed here.)
APPENDIX 2:
On
Censorship and Manipulative Indoctrination in science
education
and in
the court-room: the Kitzmiller/Dover Case
The
following was posted to the KairosFocus blog,
on receipt of the breaking news that Judge Jones' decision was, insofar
as it addressed the scientific status of Intelligent design,
essentially a near-verbatim excerpt of an ACLU post-trial submission.
This not only underscores the case's status as a classic of improper
judicial activism, but given the fact explained below that the Judge
reproduced even the ACLU's many factual errors and misrepresentations
in this part of his decision, it utterly destroys its credibility.
_____________________
1
Chron 12:32 Report, no 9: the Dover ID case as a showcase example of
manipulative secularist radicalism in the courts and media
BREAKING
NEWS: A year after the Kitzmiller
Decision in Dover, Pennsylvania, the Discovery Institute [DI] has just
published a 34 p. article in which it shows, in devastating
parallel columns, that Judge Jones' discussion of the alleged
unscientific status of the empirically based inference to design, was
largely copied from an ACLU submission, factual errors,
misrepresentations and all.
DI
summarises its findings thusly:
In December of 2005, critics of the
theory of intelligent design (ID) hailed federal judge John E. Jones’
ruling in Kitzmiller v. Dover, which declared unconstitutional the
reading of a statement about intelligent design in public school
science classrooms in Dover, Pennsylvania. Since the decision was
issued, Jones’ 139-page judicial opinion has been lavished with praise
as a “masterful decision” based on careful and independent analysis of
the evidence. However, a new analysis of the text of the Kitzmiller
decision reveals that nearly all of Judge Jones’ lengthy examination of
“whether ID is science” came not from his own efforts or analysis but
from wording supplied by ACLU attorneys. In fact, 90.9% (or
5,458 words) of Judge Jones’ 6,004- word section on intelligent design
as science was taken virtually verbatim from the ACLU’s proposed
“Findings of Fact and Conclusions of Law” submitted to Judge Jones
nearly a month before his ruling. Judge Jones even copied several
clearly erroneous factual claims made by the ACLU. The
finding that most of Judge Jones’ analysis of intelligent design was
apparently not the product of his own original deliberative activity
seriously undercuts the credibility of Judge Jones’ examination of the
scientific validity of intelligent design.
Now, a year ago, Judge Jones of
Pennsylvania issued his "landmark" decision on the Dover School Board
case, which was indeed hailed in much of the major international media
as a death-blow to the Intelligent Design movement (which has of course
not gone away!). In effect, he
ruled unconstitutional the reading out to students in 9th
Grade [roughly, 3rd form] Biology the following statement:
The Pennsylvania Academic Standards
require students to learn about Darwin’s Theory of Evolution and
eventually to take a standardized test of which evolution is a part.
Because Darwin’s Theory is a theory, it continues to be tested as new
evidence is discovered. The Theory is not a fact. Gaps in the Theory
exist for which there is no evidence. A theory is defined as a
well-tested explanation that unifies a broad range of observations.
Intelligent Design is an explanation of the origin of life that differs
from Darwin’s view. The reference book, Of Pandas and People,
is available for students who might be interested in gaining an
understanding of what Intelligent Design actually involves.
With respect to any theory, students are encouraged to keep an open
mind. The school leaves the discussion of the Origins of Life to
individual students and their families. As a Standards-driven district,
class instruction focuses upon preparing students to achieve
proficiency on Standards-based assessments.
That such a statement
-- in a time in which Darwinian Biology and the broader ideas of
evolutionary materialism plainly continue to be scientifically,
philosophically
and culturally
controversial -- would be widely seen as an attempt to impose
"religion" in the name of "science," is itself a clue that something
has gone very wrong indeed.
For,
it is immediately obvious on examining basic, easily accessible facts,
that:
a]
The Neo-Darwinian Theory of Evolution [NDT] is just that: theory, not fact.
This means that insofar as it is science,
it is an open-ended explanatory exercise, one that is subject to
correction or replacement in light of further evidence and/or analysis,
and one that seeks to summarise and make sense of a vast body of
empirical data -- in which effort there are indeed key, persistent
explanatory gaps.
b]
Design
Theory, in that light, is a
re-emerging
challenger as a scientific
explanation, one that arguably better explains certain key
features of, say the fossil record. (And, let us observe here, that ID
should not be confused with, say Young Earth, specifically
Biblically-oriented Creationism [YEC], which seeks to scientifically
explain origins in a context that often -- but
not always -- makes explicit reference to the Bible, regarded
as an accurate record of origins. Nor, is it merely a critique of
darwinian thought, but rather a working out of addressing the full
range of root-explanations for phenomena: chance, necessity and agency,
in light of the only
actually known, empirically observed source of FSCI:
intelligent agency. For example, design thought, as a movement, does
not deny that significant macro-level
evolution may well have happened across geological time [NB:
YEC thinkers accept that micro-evolution
can and does occur], but it is raising and addressing the really
central, empirically based, scientific issue: how may we best explain where
the functionally specific, complex information in life and in the
biodiversity in the fossil record and current came from, given what
we know about the observed source of such FSCI?)
c]
For instance, as Loennig points out in a
recent peer-reviewed paper -- a paper submitted to Judge
Jones, BTW -- on the well-known problem for the NDT that the fossil
record is marked by sudden appearances and disappearances, starting
from the Cambrian life explosion, and a resulting multitude
of "missing links":
[On
the hypothesis that] there are indeed many systems and/or correlated
subsystems in biology, which have to be classified as irreducibly
complex and that such systems are essentially involved in the formation
of morphological characters of organisms, this would explain both, the
regular abrupt appearance of new forms in the fossil record as well as
their constancy over enormous periods of time . . . For, if "several
well-matched, interacting parts that contribute to the basic function"
are necessary for biochemical and/or anatomical systems to exist as
functioning systems at all (because "the removal of any one of the
parts causes the system to effectively cease functioning") such systems
have to (1) originate in a non-gradual manner and (2) must remain
constant as long as they are reproduced and exist [and also] (3) the
equally abrupt disappearance of so many life forms in earth history . .
. The reason why irreducibly complex systems would also behave in
accord with point (3) is also nearly self-evident: if environmental
conditions deteriorate so much for certain life forms (defined and
specified by systems and/or subsystems of irreducible complexity), so
that their very existence be in question, they could only adapt by
integrating further correspondingly specified and useful parts into
their overall organization, which prima facie could be an improbable
process -- or perish . . . .
d]
The call to an OPEN [but critically aware] mind in light of knowing the
dominant theory and its gaps and that alternatives exist [note that ID
was not to be expounded in the classroom!] is not a closing off of
options but an
opening of minds. (Notice how actual censorship
is being praised when it serves the agenda of the secularist elites
here.
e]
Given the persistent absence of a credible, robust account of the
origin of the functionally specific, complex information [FSCI] and
associated tightly integrated information systems at the heart of the
molecular technology of life, the origin of life is the first gap in
the broader -- and, BTW, arguably
self-refuting -- evolutionary materialist account of origins.
Further to this, we must observe the force of the issue Loennig raises
in his peer reviewed article on the challenge of viable macro-level
spontaneous ["chance"] changes in DNA that express themselves
embryologically early bring this gap issue not only to chemical
evolution, but to the macro-evolution that NDT is supposed to explain,
but does not. Ands such major explanatory gaps in the account of
macro-evolution start with the Cambrian life explosion as
Meyer noted in another peer-reviewed article. [Both of these
were of course brought to Judge Jones' attention, and both were
obviously ignored, even at he cost of putting out falsehoods and
misrepresentations authored by the ACLU in his opinion. No prizes for
guessing why.]
f]
So, while -- as
DI argues -- ID is too pioneering to be a part of the High
School level classroom exposition (as opposed to an issue that
legitimately arises incidentally in debates and discussions), the
cluster of persistent issues that NDT and wider evolutionary
materialism cannot account for, definitely should be; on pain of
turning the science classroom into an exercise in manipulative
indoctrination. The ongoing censorship of this scientific,
philosophical, and cultural controversy is therefore utterly telling.
A glance at major features of the
ruling itself amply confirms the problem. For instance, observe how the
Judge addresses a major concern in the case, revealing that he is
indulging in improper activism in his attempt to decide by judicial
fiat a matter that properly belongs to the philosophy of science:
. . . the Court is confident that no
other tribunal in the United States is in a better position than are we
to traipse into this controversial area. Finally, we will
offer our conclusion on whether ID is science not just because it is
essential to our holding that an Establishment Clause violation has
occurred in this case, but also in the hope that it may
prevent the obvious waste of judicial and other resources which would
be occasioned by a subsequent trial involving the precise question
which is before us. [p. 63] (emphasis added)
It is unsurprising to see that, in
the 139 page ruling, Judge Jones held -- among other things -- that the
inference to design was an inherently illegitimate attempt to impose
the supernatural on science, and so falls afoul of the US
Constitution's First Amendment's principle of separation of Church and
state. He also held, as a key plank in his decision -- even though an
actual list of such
papers was presented to him in a submission by the Discovery
Institute [cf Appendix A4, p. 17, here]
-- that there was no peer-reviewed ID supporting scientific literature.
Further to this, he refused to allow FTE, the publishers of the key
book referenced in the case, Of Pandas and People,
to intervene in the case to
defend itself by participating in the trial, even though
their work was being materially misrepresented -- which clearly
affected the ruling.
Misrepresented? Yes, this book, in
the actually published version [the one that is relevant to
determining what the authors and publishers intended and what the
impact of the book being in school libraries would likely be] explicitly
states:
This book has a single goal: to
present data from six areas of science that bear on the central
question of biological origins. We don't propose to give final answers,
nor to unveil The Truth. Our purpose, rather, is to help readers
understand origins better, and to see why the data may be viewed in
more than one way. (Of Pandas and People, 2nd ed. 1993, pg. viii) . . .
.
Today we recognize that appeals to intelligent design may be considered
in science, as illustrated by current NASA search for extraterrestrial
intelligence (SETI). Archaeology has pioneered the development of
methods for distinguishing the effects of natural and intelligent
causes. We should recognize, however, that if we go
further, and conclude that the intelligence responsible
for biological origins is outside the universe (supernatural) or within
it, we do so without the help of science. (pg.
126-127, emphasis added)
In short -- and exactly as the 1984
technical level book, The
Mystery of Life's Origins, the publication of which
(claims
to the contrary notwithstanding) is the actual historical
beginning of the modern design movement [apart from
in cosmology!] also argues -- we
may properly and scientifically infer to intelligence as a cause
from its empirically observable traces that are not credibly the
product of chance or natural regularities.
But, of course, such an inference -- just as its opposite, the philosophically
based premise that science "must" only infer to chance and
natural regularities on questions of origins -- soon raises worldview
issues. For, just as darwinian
evolution is often used as a support for evolutionary materialism,
a credible, empirically anchored scientific inference to design on the
cases of: the origin of the
molecular nanotechnology of life, that of the
macro-level diversity of life and the origin of a
finitely old, elegantly fine-tuned cosmos, plainly opens
the philosophical and cultural doors to taking seriously what
is "unacceptable" to many among the West's intensely secularised
intellectual elites: God as the likely/credible intelligent
designer, thence credibly the foundation of morality, law, and justice.
(So, let us pause: why is it that evolutionary
materialist worldviews
that go far beyond what is empirically and logically well-warranted are
allowed to pass themselves off as "science," thus can freely go into
the classroom, but empirically and logically/mathematically based
serious challenges and alternatives to the claims of these worldviews
that in fact appear in the peer-reviewed scientific and associated
literature are excluded as "religion" [even when this is not at all
objectively true]? Is
this not blatant secularist indoctrination and censorship? Is not secular
humanism, at minimum, a quasi-religion -- one that now is
effectively established by court fiat under the pretence that we are
"separating church and state"? Should we not instead teach
key
critical thinking skills and expose students to the range of
live options, allowing them to draw their own, objectively defensible
conclusions for themselves in the context of honest classroom dialogue
based on comparative
difficulties? [NB: Here are my thoughts
on science education, from a science teaching primer that I
was once asked to develop. Perhaps, this lays out a few ideas on a
positive way forward.])
Nor, is this worldview-level dispute a new point. Indeed, as far back
as Plato in his The Laws,
we may read:
Ath.
. . . we have . . . lighted on a strange doctrine.
Cle.
What doctrine do you mean?
Ath. The wisest of all doctrines, in the opinion
of many.
Cle. I wish that you would speak plainer.
Ath. The doctrine that all things do
become, have become, and will become, some by nature,
some by art, and some by chance.
Cle. Is not that true?
Ath. Well, philosophers are probably right; at
any rate we may as well follow in their track, and examine what is the
meaning of them and their disciples.
Cle. By all means.
Ath. They say that the greatest and
fairest things are the work of nature and of chance, the lesser of art,
which, receiving from nature the greater and primeval creations, moulds
and fashions all those lesser works which are generally termed
artificial . . . . . fire and water, and earth and air, all
exist by nature and chance . . . The elements are severally moved by
chance and some inherent force according to certain affinities among
them . . . After this fashion and in this manner the whole heaven has
been created, and all that is in the heaven, as well as animals and all
plants, and all the seasons come from these elements, not by the action
of mind, as they say, or of any God, or from art, but as I was saying,
by nature and chance only . . . . Nearly all of them, my
friends, seem to be ignorant of the nature and power of the soul [i.e.
mind], especially in what relates to her origin: they do not know that
she is among the first of things, and before all bodies, and is the
chief author of their changes and transpositions. And if this is true,
and if the soul is older than the body, must not the things which are
of the soul's kindred be of necessity prior to those which appertain to
the body? . . . . if the soul turn out to be the primeval
element, and not fire or air, then in the truest sense and beyond other
things the soul may be said to exist by nature; and this would be true
if you proved that the soul is older than the body, but not otherwise.
[Emphases added]
Plato, of course is here seeking to
ground the moral basis of law [cf the introduction to Book 10 in the
linked], and thus exposes what is at stake in the current debate over
the scientific status of the inference to design: the moral foundation
of civilisation itself - not just a matter of the nominal, vexed but
technical issue of demarking
science from non-science. Thus, the intensity of the debate
and the too-frequent resort to dubious rhetorical and legal tactics as
just outlined are all too understandable: a lot is at stake.
Dubious rhetorical and legal tactics?
Yes, sad to say:
1] First and tellingly, as a lower
court Federal Judge under the US Congress, Mr Jones, strictly, has no
proper jurisdiction on the matter. The
First Amendment to the US Constitution, in the relevant
clauses states: Congress shall make no law respecting an
establishment of religion, or prohibiting the free exercise thereof; or
abridging the freedom of speech. That is, there is to be no Church
of the United States [though at the time of passage in 1789,
nine of thirteen states had state churches]. In that context,
dissenters were to be free to hold and freely express and publish their
beliefs. So, the specific matter in question in the Dover case should
have been decided democratically by a well-informed local
community, (That this is manifestly not so, shows -- sadly, but
tellingly -- just how much the public has been ill-served by both the
media and the courts.)
2] That on the ground, this is not so, and the related commonplace idea
that the US Constitution establishes a separation of church and state
-- increasingly, a separation of Judaeo-Christian worldview and state
such that any tracing of any policy to such a worldview at once renders
the policy in question suspect and to be banned, is a mark of
longstanding successful manipulative misreadings of the US
Constitution, and of associated legislation from the bench by
unaccountable judges, also known as judicial
activism.
3] Indeed, the case in view is a showcase example of improper judicial
activism and where it leads: Judge Jones took the submittal from one
side, ignoring testimony and evidence in open court and in submittals
from relevant parties that would have exposed the errors and
misrepresentations. So, he took the ACLU's arguments,
misrepresentations, obvious factual errors and all, and by and large
reproduced it wholesale as his decision.
4] The root of these misrepresentations is the idea that inference to
design is inherently about the injection of the supernatural into
science, which is deemed improper. But in fact Judge Jones' idea that
for centuries, science has been defined as exclusively naturalistic is
simply false to the history of Science. For, as
Dan Peterson notes:
Far from being inimical to science,
then, the Judeo-Christian worldview is the only belief system that
actually produced it. Scientists who (in Boyle's words) viewed nature
as "the immutable workmanship of the omniscient Architect" were the
pathfinders who originated the scientific enterprise. The assertion
that intelligent design is automatically "not science" because it may
support the concept of a creator is a statement of materialist
philosophy, not of any intrinsic requirement of science itself.
5] Nor (as we saw above) is the
design inference -- ACLU et al notwithstanding, properly speaking, as a
scientific inference, an inference to the supernatural [as opposed to
the intelligent]. Indeed, when William Dembski (perhaps the leading
design theorist) sets
out to formally define, he writes:
. . . intelligent design begins
with a seemingly innocuous question: Can objects, even if nothing is
known about how they arose, exhibit features that reliably signal the
action of an intelligent cause? . . . Proponents of intelligent design,
known as design theorists, purport to study such signs formally,
rigorously, and scientifically. Intelligent design may
therefore be defined as the science that studies signs of intelligence.
6] In this context, the Judge's
[and the ACLU's] gross factual error of insisting in the teeth of
actual listed and accessible peer
reviewed scientific publications that are supportive of the
design inference, is utterly inexcusable -- and (since the judge may
simply naively have allowed himself to be misled) it is frankly
dishonest on the part of the likes of the ACLU and others who
insistently assert this falsehood.
So, what a difference a year makes!
Those who stood up a year ago and said -- with reasons -- from
day one that this case was wrongly ruled on and unjustly
decided, are now vindicated. However, given what is at stake, I will
not hold my breath waiting for an apology and retraction.
For, sadly, the discourse in education, the media, courts and
parliaments these days is too often more a
matter of spin than of fearless straight
thinking that seeks to discover and stand up for the truth,
the right, the wise and the sound. As the Greeks used to say, a
word to the wise . . . END
UPDATE: Minor
editing, addition of a few comments and of links. Also, Dec 16,
expanding on the Dover statement in light of a comment made at
EO.
APPENDIX 3:
On
the origin,
coherence and significance of the concept, "Complex, Specified Information."
It has
often been claimed that the concept, Complex Specified Information,
CSI, as has been championed by Dr William Dembski and other leading
Intelligent Design theorists, is vague, incoherent and
useless,
"not scientific," etc. This assertion is then often used to
dismiss without serious consideration the matters gone into above.
Even though the above note focuses on a more easily identified and
explained subset of the CSI concept, functionally
specified complex information, FSCI,
clarifying the general contentiousness over the wider term CSI is
relevant to those interested in making a considered judgement on the
issue of inference to design.
It is
therefore appropriate to first of all point out that the core
idea
in the CSI concept is in fact simple, coherent and a
result of the natural evolution of Origin of Life [OOL]
studies by the turn of the
1980's.
This, we
may do by citing the very first (and then quite well-received)
technical level Design Theory book, The Mystery of Life's Origin
[TMLO]. [This work was first published in 1984,
was authored by by Thaxton, Bradley and Olson [TBO] and bears a
foreword by noted OOL researcher, Dean Kenyon
(who, astonishingly, publicly
recanted his earlier biochemical
predestination thesis in the foreword; in part, based on
the arguments in TMLO). ]
Indeed,
based on TBO's report in TMLO, if any one person can be said to have
originated the term, it is noted OOL researcher Leslie Orgel,
as the following excerpts and notes from Chapter 8
indicate:
-->
In that chapter, we may first see how TBO build up to their discussion
on thermodynamics and the origin of life, by first highlighting that
the key issue is the origin of the cell's informational
macromolecule-based metabolic
motor.
--> Prigogine's
remark that his Nobel Prize-winning work on systems constrained to be
far from equilibrium has not solved the problem of "the mechanisms responsible for
the emergence and maintenance of coherent states" is also tellingly
important.
-->
The crucial distinction between order and complexity is thus introduced
by TBO: "a
periodic structure has order.
An aperiodic structure
has complexity."
Such
orderly periodic structures, as a rule, are in the main governed by
natural regularities tracing to mechanical necessity and also tend to
reflect boundary conditions at their time and place of origin.
CASE
STUDY -- of cyclones and snowflakes:
A tropical cyclone is by and large shaped by convective and Coriolis
forces acting on a planetary scale over a warm tropical ocean whose
surface waters are at or above about 80 degrees F. That is, it is a
matter of chance + necessity leading to order under appropriate
boundary conditions, rather than to complex, functionally specified
information.
Similarly,
the
hexagonal, crystalline symmetry of snowflakes
is driven by the implications of the electrical polarisation in the
H-O-H (water) molecule -- which is linked to its kinked geometry, and
resulting hexagonal close packing. Their many, varied shapes are
controlled
by the specific micro-conditions of the atmosphere along the
path travelled by the crystal as it forms in a cloud.
As
the just linked summarises [in a 1980's era, pre-design movement
Creationist context] and illustrates by apt photographic examples
[which is a big part of why it is linked]:
Hallet
and Mason2. . . found that water
molecules are preferentially incorporated into the lattice structure of
ice crystals as a function
of temperature. Molecules
from the surrounding vapor that land on a
growing crystal migrate over its surface and are fixed to either the
axial [tending to lead to plate- or star-shaped crystals] or basal
planes [tending to lead to columnar or needle-like crystals] depending
upon four temperature conditions. For
example, snow crystals will grow lengthwise to form long, thin needles
and columns . . . when the temperature is between about
-3°C and -8°C. When the temperature is between about -8°C and -25°C,
plate-like crystals
will form . . . Beautiful stellar
and dendritic crystals form at about -15°C. In
addition, the relative humidity
of the air and the presence of
supercooled liquid cloud droplets will cause secondary growth phenomena
known as riming and dendritic growth. [NB:
this is what leads to the most elaborate shapes.] The small, dark
spheres
attached to the edges of the plate[-type crystal] in Figure 5 are cloud
droplets that
were collected and attached to the snow crystal as rime as the crystal
fell through these droplets on its way to the earth's surface. The
dendritic and feathery edges . . . are produced by
the rapid growth of snow crystals in a high-humidity
environment . . . . The modern explanation of the
hexagonal symmetry of snow crystals is that a snow crystal is a
macroscopic, outward manifestation of the internal arrangement of the
molecules in ice. The molecules form an internal pattern of lowest free
energy, one that possesses high structural symmetry. For the water
molecule this is a type of symmetry called hexagonal close
pack.
["Microscopic
Masterpieces: Discovering Design in Snow Crystals," Larry Vardiman,
ICR, 1986. (Note,
too, from the context of the above excerpts, on how "design"
and
"creation" are rather hastily inferred to in this 1980's era
Creationist article; a jarringly different frame of thought from the
far more cautious, empirical, step by step explanatory filter process
and careful distinctions developed by TBO and other design
theorists. Subsequently, many Creationists have moved towards the
explanatory filter approach pioneered by the design thinkers. This
article -- from Answers
in Genesis'
Technical Journal -- on the peacock's tail is an excellent example, and
a telling complement to the debates on the bacterial flagellum. Notice,
in particular, how it integrates the aesthetic impact issue that is
ever so compelling intuitively with the underlying issue of organised
complexity to get to the aesthetics.) Cf also an
AMS
article here.]
A
snowflake may indeed be (a) complex
in external
shape [reflecting random conditions along its path of
formation] and
(b) orderly
in underlying
hexagonal symmetrical structure [reflecting the
close-packing molecular forces at
work], but it simply does not encode
functionally specific information. Its form simply results
from the point-by-point particular conditions in the
atmosphere along its
path as it takes shape under the impact of chance
[micro-atmospheric
conditions] + necessity
[molecular packing forces].
The tendency
to wish to use the snowflake as a claimed counter-example alleged to
undermine the coherence of the CSI concept thus
plainly reflects a
basic confusion between two associated but quite distinct features of
this phenomenon:
(a)
external shape
-- driven by random
forces and yielding complexity [BTW, this is in theory
possibly useful for encoding information, but it is probably
impractical!]; and,
(b)
underlying hexagonal
crystalline structure -- driven by mechanical forces and
yielding simple, repetitive, predictable order.
[This is not useful for encoding at all . . .] Of course, other kinds
of naturally formed crystals reflect the same balance of forces and
tend to have a simple basic structure with a potentially complex
external shape, especially if we have an agglomeration of in effect
"sub-crystals" in the overall observed structure.
In
short, a snowflake is fundamentally a crystal, not an aperiodic and functionally specified
information-bearing structure serving as an integral component of an
organised, complex information-processing system, such as
DNA or protein macromolecules manifestly are.
--> Such a careful distinction
between order, complexity and aperiodic, functionally specified
complexity is vital,
as: "Nucleic acids and protein are aperiodic polymers,
and this aperiodicity is what
makes them able to carry much more information."
-->
Thus, we see that "only certain sequences of amino
acids in polypeptides and bases along polynucleotide
chains correspond to useful biological functions."
-->
Moreover, as has been pointed out,
if one breaks a snowflake, one still has (smaller) ice
crystals. But, if one breaks a bio-functional protein, one does not have smaller, similarly
bio-functional proteins. That is, the complexity of
the protein molecule as a whole is an integral part of its
specific functionality.
-->
This leads us back to the crucial point of departure, in 1973, with Orgel's
observation that defines the concept of specified complexity on observation and comparison of:
(a) the complex, specific, functional organisation of living cell-based organisms, with
(b) the simple order of crystals and
(c) the complex disorder of random polymers or lumps of granite.
Citing:
. . . In brief, living organisms are distinguished by their specified complexity.
Crystals are usually taken as the prototypes of simple well-specified
structures, because they consist of a very large number of identical
molecules packed together in a uniform way. Lumps of granite or random
mixtures of polymers are examples of structures that are complex but
not specified. The crystals fail to qualify as living because they lack
complexity; the mixtures of polymers fail to qualify because they lack
specificity. [The Origins of Life (John Wiley, 1973), p. 189.]
-->
As well, in 1979, J S Wicken brought out the closely related concept of
functionally specific, complex information in the context of living
systems thusly:
‘Organized’
systems are to be carefully distinguished from ‘ordered’ systems.
Neither kind of system is ‘random,’ but whereas ordered systems are
generated according to simple algorithms [[i.e. “simple” force laws
acting on objects starting from arbitrary and common- place initial
conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [originally . . . ] external ‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’ [“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65. (Emphases and notes added. Nb: “originally” is added to highlight that for self-replicating systems, the blue print can be built-in.)]
--> The idea-roots of the term "functionally specific complex information" [FSCI] are thus plain: "Organization, then, is functional[[ly specific] complexity and carries information."
We
may therefore contrast three sets of letters that show the distinction
among three classes of linearly ordered digital sequences, by way of
illustrative example (one paralleled by Peterson as cited above):
1. [Class 1:] An ordered
(periodic) and therefore specified arrangement:
THE END THE END THE END THE END
Example: Nylon, or a crystal
. . . .
2. [Class 2:] A complex
(aperiodic) unspecified arrangement:
AGDCBFE GBCAFED ACEDFBG
Example: Random polymers (polypeptides).
3. [Class 3:] A complex
(aperiodic) specified arrangement:
THIS SEQUENCE OF LETTERS
CONTAINS A MESSAGE!
Example: DNA, protein.
Such
a linear spatial pattern makes the case in a very simple, effective and
relevant way, as DNA and proteins as initially formed are precisely
such linear discrete-state chains of information-bearing elements,
typically 300 monomers long -- requiring 900 DNA base pairs, which can
store 1,800 bits of information.
And,
we observe that sufficiently long class-three strings of letters are
invariably the product of intelligent agents. (Thus, we see again the
point that the inference to design on observing such a pattern is based
on a great deal of empirically based knowledge about the sources of
such phenomena.)
But
also, proteins are folded into three-dimensional, key- and- lock
fitting frameworks that are precisely functional and strongly dependent
on that spatial ordering. Obviously, and in light of the pattern of
hydrophilic and hydrophobic elements and other bonding forces, the
three-dimensional state is largely a result of the linear one. That is,
the linear sequence in part encodes information that determines the
functionality of the folded protein.
It is worth pausing to jump several
decades ahead in time, and introduce and briefly comment on an
illustrative figure by Trevors
and Abel, Fig 4 from their
recent [peer-reviewed] 2005 paper on
"Three subsets of sequence complexity and
their relevance to biopolymeric information":
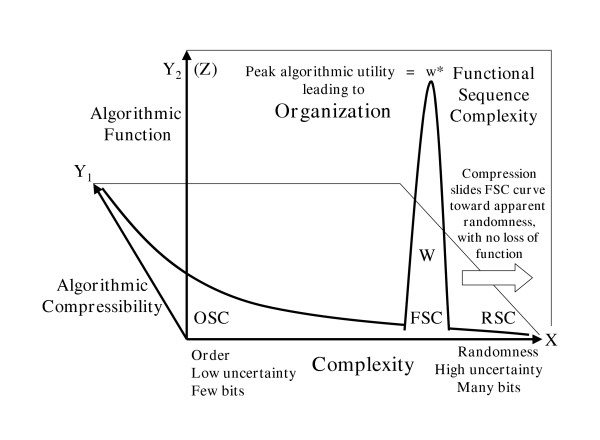 |
Fig A3.1: Contrasting different types of
sequences and their characteristics [used under the US NIH's Open
Access permission]
TA's description of their Fig
4: Superimposition of Functional Sequence
Complexity onto Figure 2 [i.e. from their paper]. The Y1 axis
plane plots the decreasing degree of algorithmic compressibility as
complexity increases from order towards randomness. The Y2 (Z)
axis plane shows where along the same complexity (more ...
|
Here
we may observe that sequences that exhibit order
are quite distinct from those that exhibit either random
sequence complexity or complex
functional organisation. We may observe that complexity is
maximised and algorithmic compressibility [ability to be simply and
briefly described, in effect] is minimised in a long random sequence
[cf TBO's Class 2 supra]. By contrast, a long but orderly sequence
[Class 1] is of high compressibility but low complexity. A long,
functionally specified, organised, complex sequence [Class 3]
is as a rule not quite as "complex" -- per metrics of complexity -- as
a long random sequence; as it would have in it the redundancies and
periodicities that are part and parcel of effective communication.
However, by contrast
with both order and randomness, it exhibits high
functionality; which is of course observable
(and so can in principle be associated with a count of the number of
ways that components may be configured compatible with that
functionality, as opposed to the usually far higher number of possible
arrangements in total; cf the
microjets case supra). [NB: while of course these
ideas are developed relative to linear sequences, they extend to higher
dimensionalities as well, and can be generalised in thinking about
order, randomness and organised, functional complexity.]
Further to this, let us observe that crystals, a paradigmatic instance
of order, form due to the mechanical necessity imposed by inter-atomic
[or ionic or molecular] forces, once the random energy always present
at micro level has been brought sufficiently low under the prevailing
local circumstances that the order may manifest itself through
crystallisation; that is, natural regularities tracing to mechanical
necessity prevail and there is a low contingency that results; thence,
low information-storing capacity. In the case of the sort of random
arrangements of say particles diffused or dissolved in a fluid, there
are typically a great many -- as a rule aperiodic -- arrangements that
are compatible with the conditions prevailing: high contingency, but
low periodicity and low useful information, but (per that high
contingency) a high potential for information storing capacity. In the
case of a functionally organised, information-bearing entity, there is
relatively high contingency and relatively high aperiodicity but that
is associated with also, a highly specific functionality requirement
such that the number of compatible configurations, as a fraction of all
possible configurations, is relatively low: information is actually
stored, and is in large part manifest in the specificity of the actual
-- as opposed to potential -- arrangement. Functional, information-rich
organisation is specific, aperiodic and complex, depending for
its
existence on high contingency.
From their
examination of different types of linear sequences, TBO then
proceed to Yockey and Wickens' powerful summary of the key issue:
Yockey7 and Wickens5 develop
the same distinction,
that "order"
is a statistical concept referring to regularity
such as could might characterize a series of digits in a number, or the
ions of an inorganic crystal. On the other hand, "organization"
refers to physical systems and the specific set of spatio-temporal and functional
relationships among their parts. Yockey and Wickens note that informational
macromolecules have a low degree of order but a high
degree of specified
complexity. In short, the redundant
order of crystals cannot give rise to
specified complexity of the kind or magnitude found in biological
organization;
attempts to relate the two have little future.
[NB:
Emphases and colours added for clarity. The green highlighted portions
just above, of course, indicate one of the key idea-sources for my own
terminology, FSCI.
Observe as well the long-since given answer to the commonly encountered
confusion between the order
of crystals and the like, the complexity
found in random polymers and the like, and the specified complexity
found in the key informational macromolecules of life: "the redundant order
of crystals cannot give rise to
specified complexity of the kind or magnitude found in biological
organization;
attempts to relate the two have little future."
]
So,
by 1984, the concept of complex specified information had
emerged
from the natural progression of OOL studies, and its
implications for the source of such organised complexity had
been
recognised by the pioneer workers in design theory, Thaxton, Bradley and
Olsen, [TBO].
However,
perhaps due to their context of OOL studies (which has to deal
with extraordinary degrees of complexity on a routine basis), and
also due to their focus on thermodynamics issues, this cluster of
original design theory authors did not explicitly identify
the degree
of complexity that would
be required to mark an upper limit of what was feasibly reachable by
random, stochastic processes. However, in the thermodynamics
calculations TBO made in
Ch 8 of TMLO, they were able to show from fundamental classical and
statistical thermodynamics principles
calculations, that the likely concentrations of even relatively simple
proteins and DNA strands in even generous pre-biotic soups would be
negligibly different from zero. (Compare, Appendix
1 above, and also the updated information theory-oriented
calculations presented by Bradley, here.)
Thus, Dembski
plainly did not not
introduce a dubious novelty. Instead,
starting in the 1990's, he refined, elaborated and
mathematically modelled an existing and well-accepted concept --
quantifying in particular what we may descriptively term "the
edge of chance."
Namely:
1]
By focusing on the classic
causal factors, (a)
chance, (b) necessity and (c) agency, he was able to
highlight that a highly
contingent situation is not dominated by necessity. [NB:
This is discussed in the just linked.]
2]
By developing the concept of the
universal probability bound,
UPB, he was able to stipulate a yardstick for sufficient complexity to
be of interest, namely odds of 1 in 10^150. Thus, we can
see that for a
uniquely specified configuration, if it has in it significantly more
than 500 bits of information storage capacity, it is maximally unlikely
that it is a product of chance processes. (To make this an even more
generous yardstick: since we can have islands or archipelagos of
function in a configuration space, we can stipulate that once the
information storage capacity of an entity exceeds 500 - 1,000 bits, it
is maximally unlikely to have been formed by chance, on the gamut of
the observed cosmos. 1,000 bits of course corresponds to about 10^301
possible states.)
3]
He then used the concept of specification
as an independent,
detachable pattern that characterises the relevant cluster
of states, to create the third element of his now famous explanatory
filter. (Cf. also here,
on coming back from the cut and thrust of [too often dubious] debate
tactics to the core scientific
questions on this.)
4]
In effect, if we can have [a] an
independent, precise, "detachable" description of
the state, and/or [b] it
is functionally observable and distinct [such as
biofunction as is noted on above or "flyability" as is discussed in Appendix 1 section 6],
and/or [c] the precise
description is compressible
through a process identified by Kolmogorov [as opposed to you in effect
have to list out the details of the state to precisely describe it,
taking up more or less as much information storage capacity as the
original state does (cf. here how we have to describe the winning
number in a lottery by citing it)],
we can objectively identify specification. The concept can be
mathematically elaborated in great detail as a model, but this is
enough for our purposes. [Cf here,
here,
here
and especially here
for a start on such elaboration.]
5]
Dembski et al then tellingly and correctly observed that in all cases where we do
directly know the causal story of an instance of CSI, the
explanatory filter aptly rules that agents are
responsible.
(Given the willingness to cheerfully accept a potentially enormous
number of false negatives in the interests of not having false
positives, through the use of the UPB, that is no surprise.)
6]
In effect, through the explanatory filter,
we have now identified
what we may descriptively term, "the
edge of
chance." For, on
the gamut of the "observed" universe, if a contingent event
includes over 500 - 1,000 bits of information storage capacity, and is
specified (especially functionally so) then it is maximally unlikely to
have formed by chance dominated processes. At the same
time, it is a member of a class of phenomena known to be routinely
caused by intelligent agents. Thus, the action of such intelligent
agency becomes its best, empirically anchored explanation.
Enormous
consequences stem from that.
For,
as we discuss in the main body of this note, the origin of life, the
body-plan level biodiversity we observe and the organised complexity of
the fine-tuned, life facilitating cosmos we inhabit all are well
beyond the UPB and are manifestations of functionally specified complex
information [FSCI], a subset of CSI.
So,
on inference to empirically anchored best explanation, OOL, body-plan
level biodiversity and the physics of a life-facilitating cosmos all
are credibly sourced in agent action. This of course cuts clean
across the
evolutionary materialist worldview and linked research
programmes in science, so it is enormously controversial.
Thus,
also, the
worldviews-tinged controversies surrounding Dr Dembski's
work. END
APPENDIX 4:
MORE ON CHANCE, NECESSITY AND AGENCY:
This often confusing issue is best initially approached/understood through a concrete example . . .
A CASE STUDY ON CAUSAL
FORCES/FACTORS -- A Tumbling Die: Heavy objects tend to fall under
the law-like natural
regularity we
call gravity. If the object is a die, the face that ends up on the top
from the set {1, 2, 3, 4, 5, 6} is for practical purposes a matter of chance.
But, if the die is cast
as part of a game, the results are as much a product of agency as of natural
regularity and chance. Indeed, the agents in question are
taking advantage of natural regularities and chance to achieve their purposes!
This
concrete, familiar illustration should suffice to show that the three causal factors
approach is not at all arbitrary or dubious -- as some are
tempted to imagine or assert.
[NB: This
example is simple, concrete and familiar enough to get away with saying that chance
processes are significantly "like that," but the underlying concept is hard to pin down and/or highly technical once we move beyond such "family resemblance to key
exemplary cases." Summarising from such simple cases: a
chance process or causal factor gives or potentially gives outcomes
that vary across a range of possibilities; beyond our actual control or
ability to specifically and consistently accurately predict; and, often in accord with a random variable- based mathematical
probability/statistical distribution such as the flat, Gaussian, Binomial or
Weibull, etc. In short, it is contingent, but not evidently directed; that is why it is the default ruling for the explanatory filter when we see significant contingency but cannot unambiguously identify FSCI, which is associated with active intelligent direction. (Cf. discussions of chance, randomness and
probability here, here (or here, simpler), here, and here [v. interesting book] for somewhat more technical expositions.) ]
However,
despite the familiarity of playing a game and tossing a die or two as an illustration of chance, necessity and
purpose in action, some argue that in the key cases in mind for ID,
there is
an unjustified worldview level basic assumption at work; i.e. we are
accused of improperly assuming that a designer (especially -- shudder -- a supernatural one!) exists, then inferring
to such question-beggingly. This objection is apparently ultimately
rooted in Kant's
idea that in effect we can never know things as such
[the noumenal world] but only as our senses and thought-world shapes
them [the phenomenal world]:
1 --> First,
a basic corrective: we must beg to remind those who are misled by the
now all-too-pervasive (and at best irresponsible and prejudicial)
anti-design dismissive rhetoric about natural/supernatural causes, that
intelligent design quite explicitly studies SIGNS of intelligence, not intelligence itself. That is, it is premised on the well-known or easily accessible facts that:
[a]
we routinely experience and observe the reality of intelligence in action
and so can identify/recognise intelligent agents [at minimum; on a "family-resemblance" case-by-case basis],
[b]
from that base of experience we know beyond reasonable doubt that the
actions by intelligent agents often issue in characteristic and
empirically recognisable traces (such as functionally specified, complex information, FSCI), so
[c] we therefore may and do routinely and often reliably distinguish the natural and the artificial as causal factors; which -- as Plato pointed out, 2300+ years ago -- is a distinction long since made by serious thinkers, one that was immemorial in his day.
[d] The "natural" category, as we view it today, includes: material or mechanical factors tracing to (1) chance and (2) necessity. (NB: Plato used phusis
in a way that seems closely related to the lawlike mechanical necessity
we focus so much on in scientific work, separating out chance as a
separate category.) The latter category, "artificial" factors tracing
to (3) intelligence.
[e]
Where the natural/supernatural issue is concerned, first, ever since
the first technical level design theory book, by Thaxton et al, The Mystery of Life's Origin,
1984 [Epilogue, pp. 188 - 214], it has been repeatedly noted that (for
instance) (i) life on earth may arguably be traced to an intelligent
cause, per signs of intelligence, but (ii) locating the provenance of
such a cause as being within/beyond the cosmos is a step beyond
what science proper is capable of. Indeed, the first major
popular-level design theory book, Of Pandas and People explicitly notes:
This book has a single goal: to
present data from six areas of science that bear on the central
question of biological origins. We don't propose to give final answers,
nor to unveil The Truth. Our purpose, rather, is to help readers
understand origins better, and to see why the data may be viewed in
more than one way. (2nd ed. 1993, pg. viii) . . .
.
Today we recognize that appeals to intelligent design may be considered
in science, as illustrated by current NASA search for extraterrestrial
intelligence (SETI). Archaeology has pioneered the development of
methods for distinguishing the effects of natural and intelligent
causes. We should recognize, however, that if we go
further, and conclude that the intelligence responsible
for biological origins is outside the universe (supernatural) or within
it, we do so without the help of science. (pg.
126-127, emphasis added)
[f] However, once we see credible signs of intelligence and infer to intelligent causes (e.g. on the best explanation for the origin of an evidently multiply fine-tuned, life facilitating cosmos),
circumstantial details and wider philosophical questions,
investigations and experiences may lead some to infer to an
extra-cosmic intelligent and even supernatural cause (e.g. of the
observed cosmos). For instance, many Christian thinkers are impressed
by the Logos Theology in John 1:1 - 5 (cf. Gen 1:1 ff. & Isa. 45:18 - 24 with Phil 2:5 - 11); and, by closely related texts such as Acts 17:22
- 28, Rom. 1:20 ff.,
Col 1:15 - 20, and Heb 1:1 - 3, which jointly put Reason/ Intelligence/ Communication
Himself at the centre of our origin and sustained existence. [NB: In reading Rom 1:20 ff., compare vv 1 - 4 in light of 1 Cor 15:1 - 11; also 2 Peter
3:3 - 13 & 1:2 - 4 (cf. Rom 8:9 - 11) and Prov. 20:27, along with Locke's remarks
in the introduction to his essay on human understanding section 5, which crucially cites 2 Peter 1:2 - 4 and Prov 20:27.] Such an extension of the scientific considerations above
is plainly a worldview-level right and also a philosophical/ theological case that
arguably may reasonably be made; but, strictly speaking, it is not in itself a scientific inference. (Just as, properly, the now commonly met with inference to an unobserved infinitely large multiverse
which has thrown up our observed sub-cosmos at random is strictly a
worldview level philosophical, not a scientific, inference. [Cf. Leslie's "fly on the
wall" response to it, excerpted above.])
2 --> Now also, Kant's
underlying concept is self refuting; for, as F.
H. Bradley aptly showed in his gentle but stinging opening salvo in his
Appearance and Reality, 2nd Edn: “The man who is ready to prove
that metaphysical knowledge is impossible has . . . himself . . .
perhaps unknowingly, entered the arena [of metaphysics] . . . . To say
that reality is such that our knowledge cannot reach it, is to claim to
know reality.”
[(Clarendon Press, 1930), p.1.]
3 -->
The
philosophers
Kreeft and Tacelli provide a bit of clarifying expansion on
F. H. Bradley's key but rather compressed point:
[Kant’s] “Copernican Revolution in philosophy” was
the claim that our knowledge does not conform to a real object but vice
versa . . . All the form, determination, specificity or
knowable content comes from the mind and is projected out onto the
world rather than coming from the world and being impressed upon the
mind . . . .
Kant’s “Copernican Revolution” is
self-contradictory, just as simple [radical or selective] skepticism
is. After all, if Kant
was right, how could he possibly have known he was right in terms of
his system? He couldn’t. He
could never know that there are “things- in- themselves,” onto which
the knowing self projects all knowable content. That would
be knowing the unknowable, thinking both sides of thought’s limit.
There is a half truth in Kantianism. Some
knowledge is conditioned by our forms of consciousness(e.g. Colors by
the eye, measurements by artificial scales and ideological positions by
personal preferences). But even here there must be some objective
content first that is received and known, before it can be classified
or interpreted by the knowing subject. [Handbook of Christian
Apologetics, (Crowborough, England: Monarch, 1995) pp. 372 –
373. (The
reader may also wish to peruse Mortimer Adler's essay on "Little Errors
at the Beginning," here,
on the underlying pervasive problem of such errors in modern
philosophising.)]
4 --> So, we ARE discussing what may
objectively be in the external world not just in our perceptions
considered as pre-filtered mental data, and a preconceived
infrastructure of ideas. Hence also, the Kantianism-derived notion that
in effect to infer to
agent cause is “necessarily” to impose within our minds the
unwarranted, before the fact category of agents -- and
thus (in the minds of such objectors to the design inference) to invite
all sorts of rhetorical assertions on how such an assumption
is a priori, ill-founded, unnecessarily limiting, etc, etc, etc -- is
plainly hopelessly fallacious.
5 --> By sharpest corrective contrast, let us
consider the point raised by Josiah Royce: “error exists” implies
that there is knowable truth. (To see that just try to deny that little
claim –- it is undeniably
and self-evidently
true, as, the attempted denial will only
manage to exemplify its truth. Thus, once
(a) we understand what the terms speak of and (b) we see how they are
connected in light of our experience of
reality [applying a modicum of common sense], we will see that (c) it must be
true. [NB: This last is in effect a simple "description/definition" of "self-evident truth," following Adler.])
6 -->
Consequently, we
can
credibly objectively experience and observe intelligent agency in
action, and can identify recognisable and even reliable empirical signs of it, at least
on the provisional basis that is the inevitable constraint on
scientific reasoning. Then, we can note that such agents routinely
leave recognisable traces of their actions: functionally specified,
complex information [FSCI] in cases ranging from the digital text of
Internet messages all the way to the pyramids, cave-paintings, burials
in beds of flowers and flint-knappings of ancient men. This, William Dembski aptly illustrates by citing Abraham de Moivre:
The
same Arguments which explode the Notion of Luck, may, on the other
side, be useful in some Cases to establish a due comparison between
Chance and Design: We may
imagine Chance and Design to be, as it were, in Competition with each
other, for the production of some sorts of Events, and may calculate
what Probability there is, that those Events should be rather owing to
one than to the other. To give a familiar Instance of
this, Let us suppose that two Packs of Piquet-Cards being sent for, it
should be perceived that there is, from Top to Bottom, the same
Disposition of the Cards in both packs; let us likewise suppose that,
some doubt arising about this Disposition of the Cards, it should be
questioned whether it ought to be attributed to Chance, or to the
Maker’s Design: In this Case the Doctrine of Combinations decides
the Question; since it may be proved by its Rules, that there are the
odds of above 263130830000 Millions of Millions of Millions of Millions
to One, that the Cards were designedly set in the Order in which they
were found. [34: Abraham de Moivre,The Doctrine of Chances (1718; reprinted New York: Chelsea, 1967), page v. Cited, Wm A Dembski, Specification: the pattern that Signifies Intelligence, 2005, p. 25. Emphasis added.]
7 -->
Nor is it reasonable to then beg the worldviews level question ahead of
examining the evidence; by trying to insist that since the
generally accepted highly intelligent code-using agents we see in
action around us are embodied and human, we
may only "properly" consider embodied
human entities as candidates to be intelligent agents.
First, we have no good reason to infer that humans exhaust the possible
or actual set of such agents. Also, we have no good grounds for
rejecting the possibility
of agents based on pure mind -- indeed, we have no sound
materialistic account of the origin of mind, or of how mind acts on our
own brains and bodies. But, we know that we do act and that we act in
ways that cannot be reasonably accounted for on mechanical necessity showing itself through
natural
regularities, or mere random chance showing itself in random walks from
arbitrary initial configurations of contingent entities. So, we should let the evidence speak
for itself rather than insisting on thinking in a self-refuting
materialist circle. (Cf further discussion in Appendix 8 below.)
8 -->
Moreover, creative, innovative information -- a characteristic property
of mind at work (as we have seen above), is not restricted to any one
embodiment or code, and can be in multiple places at the same time; it
works into intelligible, complex and functional configurations,
which (as Cicero pointed out long ago) are neither the product of
mechanical necessity nor of chance, but of the understanding,
purposeful mind.
9 --> More directly, the creative
mind (the characteristic manifestation of agency as we experience and
observe it), has radically different properties from those observed for
either chance or necessity. Indeed, insightful
innovative, complex, active, purposeful, self-directing yet orderly and
intelligible creativity is the hallmark of mind as it shows itself in
language [thus also
codes],
imagination and action. (Cf discussion of cybernetics by
Derek Smith here.)
10 --> FSCI is a reliable hallmark
of such creative action, from experience and observation. We have a
right to trust it until and unless on fair (empirically well-supported,
non-question-begging and non self-refuting) evidence that reliability
can be overthrown.
11 -->
Further to all of this, we see that the idea
that the design inference unwarrantedly "assumes" the existence of a
designer at the outset is simply wrong-headed. For,
in fact, as our investigatory start point, we simply observe that
cause-effect patterns in general trace to one or more of chance,
necessity, agency; i.e. the only
"assumption" is that agents (including, where relevant, purely mental
ones) are POSSIBLE, not excluded before we look at the empirical data
-- we merely refuse to beg the question ahead of looking at the
objective facts.
12 --> Then, as outlined above, we also see that a highly
contingent situation (such as: which face of a die is uppermost) is
either chance or agency, not necessity. For, the outcome can take on a
range of values, and we can observe the frequency distribution in that
range. After that, as Fig A.2 above illustrates, we
test for whether the observed outcome is (1) sufficiently improbable --
i.e complex -- and also (2) functionally specified, to
warrant inference that it is caused by agency not chance.
(For instance if the die in our game keeps on coming up sixes, to the
benefit of one player, that strongly suggests sleight of hand and
loading.)
13 --> Next, on the
technical issues of Fisherian vs Bayesian inference testing
and Hume vs Reid on inference to design, Dr Dembski has
presented significant, albeit controversial, arguments here and here
respectively. In desperately compressed summary: when Bayesian approaches are
applied to relevant
"practical" situations [such as the
Caputo case], we as a rule go looking for alternative hypotheses only
when we already have seen that there is reason to be "suspicious" [i.e
the Bayesian approach to testing in such cases, in effect implicitly
uses Fisherian (or at least "law of averages") expectations that things
too far from the typical result are "unlikely" to happen by chance, as
its context. [Cf Appendix 6 for mathematical
details.
One of those details is that while a likelihood approach may allow us
to infer to the most probable shift away from an "unbiased" 50:50
probability, a functionally
specified and purpose-serving bias that shows itself significant at
a credibly relevant confidence level is a strong sign of deisgn. Just ask anyone who has been rooked by the use of artfully loaded dice.]
14 --> Thus, we can see that the traditional “elimination" approach to inference testing rests on the well known, easily
observed principle
of the valid
form of the layman's "law of averages." Namely, that in a "sufficiently"
and "realistically" large [i.e. not so large that it is
unable or very unlikely to be instantiated] sample, wide fluctuations
from
"typical" values characteristic of predominant clusters, are very
rarely observed.
[For instance, if one tosses a
"fair" coin 500 times, it is most unlikely that one would by chance go
far from a
50-50 split that would be in no apparent order. So if the observed
pattern turns out to be ASCII code for a message or to be nearly
all-heads or alternating heads and tails, or the like, then it is most
likely
NOT to have been by chance. The Caputo case, after all the back and forth debate on Dr Dembski's mathematics, remains as a striking and apt case in point. (Not least, we should observe that after the court case, the long-running "streak" vanished.)]
15 -->
So the material consequence follows: when we can “simply" specify a
cluster of outcomes of interest in a configuration space, and such a
space is sufficiently large that a reasonable random search will be
maximally unlikely within available probabilistic/ search resources, to
reach the targetted cluster, we have good reason to believe that if the actual
outcome is in that cluster, it was by agency.
[Thus, we see the telling force of Sir Fred Hoyle’s celebrated illustration of
the utter
improbability of a tornado passing through a junkyard and
assembling a 747 by chance. By far and away, most of the accessible
configurations of the relevant parts will most emphatically be
unflyable. So, if we are in a flyable configuration, that is most likely (indeed, beyond REASONABLE -- as oposed to "all" -- doubt) by intent and
intelligently directed action, not chance. ]
16 -->
We therefore see why the traditional, Fisherian, eliminationist approach to hypothesis testing makes good
sense even though it does not so neatly line up with the algebra and
calculus of probability as would a likelihood or full Bayesian type
approach. Thence, we see why the Dembski-style explanatory filter 9which builds on Fisher's approach) can
be so effective, too.
Thus, to extend the idea of Bayesian comparisons of likelihoods of
alternative hypotheses relative to evidence and insist that one may not
properly walk away from a hyp unless there is an "acceptable" alt hyp,
is dubious; especially if one hinges the assertion on things like:
to infer to agency relative to an explanatory filter argument across
chance-necessity-agency plus probabilistic filtering is to imply a
before-the-fact question-begging assumption that the probability of the
existence of a relevant Agent was (nearly) unity.
17 --> For, all
that is actually
required is to refuse to beg the real question by ruling out agency
ahead of time; then to examine the evidence. Further, as this
section points out, we already routinely accept, on vast experience,
that functionally specified complex information is a
reliable objective marker of agency; so we may infer from evidence of
FSCI to agency. Third, it is better to acknowledge that one
has not got a credible hyp, than to stick with what has failed after
reasonable tests on the insistence that one has not got a better
alternative. (Which is too often the underlying rhetorical
point being made by adverting to Bayesian style likelihood testing.)
18 --> Also, the inference to design is not
simply "a weak analogy." Instead, it is an inference to
best explanation relative to what we know agents routinely do: generate
FSCI, which in every
observed case where we know the causal story directly is not
the product of chance
but of agency.
(Natural
regularities,
almost by definition, do not produce highly contingent outcomes.
E.g., by mechanical necessity, when we put oxidiser, fuel and enough
heat together, we reliably have a fire.)
19 -->
Moreover,
significant information storage, as Appendix 3
discusses, requires high contingency, and code-bearing functionally
specified particular states of the contingent elements to hold the
information. This can be shown by doing a brief thought-experiment on
using six-sided dice to encode and store information:
Sub-case study: a hypothetical, dice-based
information system: If one were so inclined,
s/he could define a six-state code
and use a digital string
of dice
to store or communicate a message by setting each die in turn to the
required functional value for communicating the message. In principle,
we could then develop information-processing and communication systems
that use dice as the data-storage and transmission elements [say, using
registers made from plastic troughs loaded with strings of dice set to
particular values and "read" by scanning the pips]; rather like the underlying
two-state [binary] digital code-strings used for this web page. So also,
since 6^193 ~ 10^150, if a functional code-string
using dice requires significantly more than 193 to 386 six-state
elements [we can conveniently round this up to 200 - 400], it would be
beyond the edge of chance
as can be specified by the Dembski
universal probability bound, UPB. [That is, the probabilistic
resources of the observed universe would be most likely fruitlessly
exhausted if a random-walk search starting from an arbitrary initial
point in the configuration space were to be tasked to find an "island"
of functionality: not all "lotteries" are winnable (and those that are,
are designed
to be winnable but profitable for their owners). So, if we were to then see a
code-bearing, functionally meaningful string of say 500 dice, it would
be most reasonable to infer that this string was arranged by an agent,
rather than to assume it came about because someone tossed a box of
dice and got really
lucky! (Actually, this count is rather conservative,
because the specification of the code, algorithms and required
executing machinery are further -- rather large -- increments of
organised, purposeful complexity.)]
20 --> For more relevant
instance, DNA is a complex, highly contingent and functionally
specified digital data-string using four-state chemical bases (the
famous nucleic acids: A, G, C, T) as information storing elements. For
DNA, then, the UPB comes after
some 250 - 500 elements, as 4^250 ~ 10^150. Now, too, as Meyer reports,
the simplest reasonable living cells credibly require 300,000 - 500,000
4-state bases, so the odds of getting to a functioning DNA string by chance [the
alternative to agency for obtaining highly contingent outcomes!], on
the gamut of our observed universe, are negligibly different from zero.
It is therefore reasonable to infer -- absent imposition of arbitrary selective
hyperskepticism or philosophically
question-begging, historically unwarranted rules such as
so-called methodological naturalism -- that observed, bio-functional
DNA as we see in living cells is designed.
Newton's thoughts on
the designer of "[t]his
most beautiful system
of the sun, planets, and comets . . . " in his General
Scholium to the Principia
Newton's
Principia is perhaps the most important scientific work of all
time.
It
contains a General
Scholium that begins
with a global inference to design and onward to the Designer, in part
from the nature of the cosmos and its physics, and in part based on
Newton's adherence to the biblical, Judaeo-Christian tradition:
. . . This most beautiful
system of the sun, planets,
and comets, could only
proceed from the counsel and dominion of an
intelligent and powerful Being. And if the
fixed stars are the centres
of other like systems, these, being formed by the like wise counsel,
must be all subject to the dominion of One; especially since the light
of the fixed stars is of the same nature with the light of the sun, and
from every system light passes into all the other systems: and lest the
systems of the fixed stars should, by their gravity, fall on each other
mutually, he hath placed those systems at immense distances one from
another.
This Being governs all things, not
as the soul of the world, but
as Lord over all; and on account of his dominion he is wont to be
called Lord God pantokrator
, or Universal Ruler; for God is a
relative word, and has a respect to servants; and Deity is the dominion
of God not over his own body, as those imagine who fancy God to be the
soul of the world, but over servants. The Supreme God is a Being
eternal, infinite, absolutely perfect; but a being, however perfect,
without dominion, cannot be said to be Lord God; for we say, my God,
your God, the God of Israel, the God of Gods, and Lord of Lords; but we
do not say, my Eternal, your Eternal, the Eternal of Israel, the
Eternal of Gods; we do not say, my Infinite, or my Perfect: these are
titles which have no respect to servants. The word God usually
signifies Lord; but every lord is not a God. It is the dominion of a
spiritual being which constitutes a God: a true, supreme, or imaginary
dominion makes a true, supreme, or imaginary God. And from
his true dominion it follows that the true God is a living, intelligent,
and powerful
Being; and, from his other perfections, that he is supreme, or most
perfect. He is eternal and infinite, omnipotent and omniscient; that
is, his duration reaches from eternity to eternity; his presence from
infinity to infinity; he governs all things, and knows all things that
are or can be done. He is not eternity or infinity, but
eternal and
infinite; he is not duration or space, but he endures and is present.
He endures for ever, and is every where present; and by existing always
and every where, he constitutes duration and space. Since every
particle of space is always, and every indivisible moment of duration
is every where, certainly the Maker and Lord of all things cannot be
never and no where. Every soul that has perception is, though in
different times and in different organs of sense and motion, still the
same indivisible person. There are given successive parts in duration,
co-existent puts in space, but neither the one nor the other in the
person of a man, or his thinking principle; and much less can they be
found in the thinking substance of God. Every man, so far as he is a
thing that has perception, is one and the same man during his whole
life, in all and each of his organs of sense. God is the same God,
always and every where. He is omnipresent not virtually only, but also
substantially; for virtue cannot subsist without substance. In
him are all things contained and moved
[i.e. cites Ac 17, where Paul evidently cites Cleanthes]; yet neither
affects the other: God suffers nothing from
the motion of bodies; bodies find no resistance from the omnipresence
of God. It is allowed by all that the Supreme God
exists necessarily; and by the same necessity he exists
always, and every where.
[i.e accepts the cosmological argument to God.] Whence also he is all
similar, all eye, all ear, all brain, all arm,
all power to perceive, to understand, and to act; but in a manner not
at all human, in a manner not at all corporeal, in a manner utterly
unknown to us. As a blind man has no idea of colours, so have we no
idea of the manner by which the all-wise God perceives and understands
all things. He is utterly void of all body and bodily figure, and can
therefore neither be seen, nor heard, or touched; nor ought he to be
worshipped under the representation of any corporeal thing. [Cites Exod
20.] We have ideas of his attributes, but what the real substance of
any thing is we know not. In bodies, we see only their figures and
colours, we hear only the sounds, we touch only their outward surfaces,
we smell only the smells, and taste the savours; but their inward
substances are not to be known either by our senses, or by any reflex
act of our minds: much less, then, have we any idea of the substance of
God. We know him only by his most wise and excellent
contrivances of things, and final cause
[i.e from his designs]: we admire him for his perfections; but we
reverence and adore him on account of his dominion: for we adore him as
his servants; and a god without dominion, providence, and final causes,
is nothing else but Fate and Nature. Blind metaphysical necessity,
which is certainly the same always and every where, could produce no
variety of things.
[i.e necessity does not produce contingency] All that diversity of
natural things which we find suited to different times and places could
arise from nothing but the
ideas and will of a Being necessarily
existing.
[That is, implicitly rejects chance, Plato's third alternative and
explicitly infers to the Designer of the Cosmos.] But, by way of
allegory, God is said to see, to speak, to
laugh, to love, to hate, to desire, to give, to receive, to rejoice, to
be angry, to fight, to frame, to work, to build; for all our notions of
God are taken from. the ways of mankind by a certain similitude, which,
though not perfect, has some likeness, however. And thus much
concerning God; to discourse of whom from the appearances of things,
does certainly belong to Natural Philosophy. [Cf also his Rules of Reasoning.]
The design-oriented context of
Newton's thought could hardly be more explicit. END
Fisher,
Bayes, Caputo and Dembski
On the
technical issues of Fisherian vs Bayesian inference testing
and Hume vs Reid on inference to design, Dr Dembski has
presented significant arguments here and here
respectively.
In desperately compressed
summary: when Bayesian
approaches are applied to relevant
situations [such as the
Caputo case], we go looking for alternative hypotheses only
when we already have seen that there is reason to be "suspicious" [i.e
the Bayesian approach to testing in such cases, in effect implicitly
uses Fisherian (or at least "law of averages") expectations that things
too far from the typical result are "unlikely" to happen by chance, as
its context; e.g. in the now notorious Caputo
case], and the
explanatory filter approach provides a tool for objectively
deciding that "suspicious enough":
In
short, we need to ask, for instance, why the Caputo case was in court
at all, as, in principle, any given specific pattern of
outcomes from
41 R:0 D to 0 R:41 D -- i.e which party would come first on the ballot
list (which apparently gives a small but significant advantage to that
party) -- was mathematically speaking equiprobable.
The answer is, from one
perspective, "obvious."
For,
when we look at the relative number of ways we may end up with a near
50-50 outcome vs the number of ways we get at least so extreme an
outcome as was observed [40 D:1 R], we soon see that outcomes very
close
to 50-50 form a strongly predominant group, and so we have good reason
to suspect that an agenda-serving pattern [Caputo was a Democrat!] that
is far indeed from the overwhelmingly expected low-fluctuation outcome
was most unlikely to be by
chance. (In short we
see contingency, a functionally specified outcome, and one that would
most likely exhaust available probabilistic resources, on a chance
hypothesis. So, "design"
is the most likely explanation.)
But,
that sort of "obviousness" in this context is quite unwelcome in some
quarters; thus, we see the rise of the Bayes vs Fisher objection that
Dembski addressed.
A
short mathematical excursus is now therefore in order, with thanks to
prof PO for the exchanges that have shown that this is necessary:
We often wish to find evidence to support a theory,
where it is usually easier to show that the theory [if it were for the
moment assumed true] would make the observed evidence “likely" to be so
[on whatever scale of weighting subjective/epistemological
"probabilities" we may wish etc . . .].
So in effect we have to move: from p[E|T] to p[T|E],
i.e from "probability of evidence given
theory" to "probability of
theory given evidence," which last is what we can see.
(Notice also how easily the former expression p[E|T]
"invites" the common objection that design thinkers are "improperly"
assuming an agent at work ahead of looking at the evidence, to infer to
design. Not so, but why
takes a little explanation.)
Let us therefore take a quick look at the algebra
of Bayesian probability revision and its inference to a measure of relative support of
competing hypotheses provided by evidence:
a] First, look at p[A|B] as the ratio, (fraction of the time we would
expect/observe A AND B to jointly occur)/(fraction of the the time B
occurs in the POPULATION).
-->
That is, for ease of understanding in this discussion, I am simply
using the easiest interpretation of probabilities
to follow, the frequentist view.
b] Thus, per definition given at a] above:
p[A|B] = p[A AND B]/p[B],
or, p[A AND B] = p[A|B] * p[B]
c] By “symmetry," we see that also:
p[B AND A] = p[B|A] * p[A],
where the two joint probabilities (in
green) are plainly the same, so:
p[A|B] * p[B] = p[B|A] * p[A],
which rearranges to . . .
d]
Bayes’ Theorem, classic form:
p[A|B] = (p[B|A] * p[A]) / p[B]
e] Substituting, E = A, T = B, E being evidence and
T theory:
p[E|T]
= (p[T|E] * p[E])/ p[T],
p[T|E]
-- probability of theory (i.e. hypothesis or model) given evidence seen
-- being here by initial simple
"definition," turned into L[E|T]:
L[E|T] is (by
definition) the likelihood of theory T being
"responsible" for what we observe, given observed evidence E
[NB: note the "reversal" of how the "|" is being read]; at least, up to
some constant. (Cf. here,
here,
here,
here
and here
for a helpfully clear and relatively simple intro. A key point is that likelihoods allow
us to estimate the most likely value of variable parameters
that create a spectrum of alternative probability distributions that
could account for the evidence: i.e. to estimate the maximum likelihood
values of the parameters; in effect by using the calculus to find the
turning point of the resulting curve. But, that in turn implies that we
have an "agreed" model and underlying context for such variable
probabilities.)
Thus, we come to a deeper challenge: where do we get agreed
models/values of p[E] and p[T] from?
This is a hard problem with no objective consensus
answers, in too many cases. (In short, if there is no handy commonly
accepted underlying model, we may be looking at a political dust-up in
the relevant institutions.)
f] This leads to the relevance of the point that
we may define a certain ratio,
LAMBDA
= L[E|h2]/L[E|h1],
This
ratio is a measure of the degree to which the evidence supports one or
the other of competing hyps h2 and h1. (That is, it is a
measure of relative
rather than absolute
support. Onward, as just noted, under certain circumstances we may look
for hyps that make the data observed "most likely" through estimating
the maximum of the likelihood function -- or more likely its
logarithm -- across relevant variable parameters in the
relevant sets of hypotheses. But we don't need all that for this case.)
g] Now, by substitution A --> E, B
--> T1 or T2 as relevant:
p[E|T1]
= p[T1|E]*
p[E]/p[T1],
and
p[E|T2]
= p[T2|E]*
p[E]/p[T2];
so
also, the ratio:
p[E|T2]/ p[E|T1]
= {p[T2|E] * p[E]/p[T2]}/ {p[T1|E] * p[E]/p[T1]}
= {p[T2|E] /p[T2]}/ {p[T1|E] /p[T1]}
h]
Thus, rearranging:
p[T2|E]/p[T1|E]
=
{p[E|T2]/ p[E|T1]} * {P(T1)/P(T2)}
i]
So, substituting:
L[E|T2]/
L[E|T1]
= LAMBDA
= {p[E|T2]/
p[E|T1]} * {P(T2)/P(T1)}
Thus, the lambda measure of the degree to which the evidence
supports one or the other of competing hyps T2 and T1,
is a ratio of the conditional probabilities of the evidence given the
theories (which of course invites the "assuming the theory" objection,
as already noted), times the ratio of the
probabilities of the theories being so. [In short if we have
relevant information we can move from probabilities of evidence given
theories to in effect relative
probabilities of theories given evidence, and in light of an
agreed underlying model.]
All of this is fine as a matter of algebra (and
onward, calculus) applied to probability, but it confronts us with the issue
that we have to find the outright credible
real world probabilities of T1, and T2 (or onward, of the
underlying model that generates a range of possible parameter values).
In some cases we can get that, in others, we cannot;
but at least, we have eliminated p[E].
Then, too, what is
credible to one may not at all be so to another. This
brings us back to the problem of selective
hyperskepticism, and possible endless spinning out of -- too
often specious or irrelevant but distracting -- objections [i.e closed minded
objectionism].
Now, by contrast the “elimination" approach rests
on the well known, easily observed principle of the valid form of the
layman's "law of averages." Namely, that in a "sufficiently"
and "realistically" large [i.e. not so large that it is
unable or very unlikely to be instantiated] sample, wide fluctuations
from "typical" values characteristic of predominant clusters, are very
rarely observed. [For instance, if one tosses a "fair"
coin 500 times, it is most unlikely that one would by chance go far
from a 50-50 split that would be in no apparent order. So if the
observed pattern turns out to be ASCII code for a message or to be
nearly all-heads or alternating heads and tails, or the like, then it
is most likely NOT to have been by chance. (See, also, Joe Czapski's
"Law of Chance" tables, here.)]
Elimination therefore looks at a credible
chance hyp and the reasonable distribution across possible outcomes it
would give [or more broadly the "space" of possible configurations and
the relative frequencies of relevant "clusters" of individual outcomes
in it]; something we are often comfortable in doing. Then, we look
at the actual observed evidence in hand, and in certain cases
-- e.g. Caputo -- we see it is simply too extreme relative to such a
chance hyp, per probabilistic resource exhaustion.
So the material consequence follows: when we can “simply" specify a
cluster of outcomes of interest in a configuration space, and such a
space is sufficiently large that a reasonable random search will be
maximally unlikely within available probabilistic/ search resources, to
reach the cluster, we have good reason to believe that if the actual
outcome is in that cluster, it was by agency. [Thus the
telling force of Sir Fred Hoyle’s celebrated illustration of the utter
improbability of a tornado passing through a junkyard and
assembling a 747 by chance. By far and away, most of the accessible
configurations of the relevant parts will most emphatically be
unflyable. So, if we are in a flyable configuration, that is most likely
by intent and intelligently directed action, not chance. ]
We therefore see why the Fisherian, eliminationist
approach makes good sense even though it does not so neatly line up
with the algebra and calculus of probability as would a likelihood or
full Bayesian type approach. Thence, we see why the Dembski-style
explanatory filter can be so effective, too.
DRAFT APPENDIX 7:
Of the Weasel "cumulative selection" program and begging the question of FSCI, c. 1986
In
December 2008, the issue of the 1986 Weasel "cumulative selection"
program came up in a discussion thread at the UD blog, and I commented on it
thusly:
[UD December 2008 Unpredictability thread, excerpt from comment 107:] . . . the problem with the
fitness landscape [model] is that it is flooded by a vast sea of
non-function, and the islands of function are far separated one from
the other. So far in fact . . . that searches on the order of
the quantum state capacity of our observed universe are hopelessly
inadequate. Once you get to the shores of an island, you can climb
away all you want using RV + NS as a hill climber or whatever model
suits your fancy.
But you have to get TO the shores first. THAT is the real, and too often utterly unaddressed or brushed aside, challenge.
[NB: And, in fact, that was the challenge Sir Fred Hoyle had posed. A
challenge that Weasel, from its outset, has unfortunately ducked and distracted
attention from. Weasel is -- and has always been -- a question-begging
strawman fallacy.]
And . . . that [unmet challenge] starts with both the
metabolism first and the D/RNA first schools of thought on OOL. As
indeed Shapiro and Orgel recently showed . . . .
As for Weasel . . . it is . . . trivially irrelevant as a plainly DIRECTED, foresighted targetted search.
It instantiates intelligent design, not the power of RV + NS.
Even going up to Avida and the like, similar issues come up, as is
highlighted under the issue of active information by Dembski and Marks.
[ slice from comment no 111: this was the excerpt that was used to inject the latching issue in a distractive fashion:]
Weasel [i.e. c. 1986] sets a target sentence then once a letter is guessed it
preserves it for future iterations of trials until the full target is
met. [That is, I inferred that Weasel latches the o/p as is likely from the below.] That means it rewards partial but non-functional success, and is
foresighted. Targetted search, not a proper RV + NS model. [Emphases and notes added.]
Thus, it should be clear what was the central issue,
and what was a secondary note on an observed fact of evident o/p
behaviour that pointed to the underlying root issue.
However,
in 2009, the secondary observation was picked up by an evolutionary
materialist
commenter at UD, leading to a fairly lengthy exchange over several UD
threads. Apart from the significant civility problems that emerged --
contemptuous and insistent privacy violations, the slanderous
conflation of design thought and creationism, gleeful citation of
dismissive remarks by a journalist that in fact turned out to be based
on the moral equating of Christians with IslamIST terrorists in the
cause of creating a confused moral climate that in effect enables
public lewdness etc. (all unapologised for and plainly unregretted) --
it became very clear that (a) Weasel's fundamental flaw is
just as has already been described, and (b) the issue of disputes
over "latching" was in the end a distraction from the main
problem. Namely, that: far from being an example of a claimed BLIND
watchmaker's capacity to create functional information from chance
variations and a crude analogue to natural selection, Weasel is
targetted, intelligently designed search that uses degree of proximity
-- without reference to degree of reasonable functionality -- to select
the "champion" of the current generation, which is then varied and used
to select the champion for the next, until the target is hit.
Notwithstanding, the issue of whether or not the o/p's in the two cases published in Mr Dawkins' The Blind Watchmaker,
in 1986 "latched" the o/ps became a debate in itself, which -- despite
its now venerable age -- interestingly illustrates some of the key
pitfalls of such proposed computer simulations of evolution.
Analysing
the case, where a random 28-letter string is changed by degrees
towards the target, "Methinks if is like a weasel":
1
--> We may conveniently begin by inspecting the published o/p
patterns circa 1986, thusly [being derived from Dawkins, R, The Blind
Watchmaker , pp 48 ff, and New Scientist, 34, Sept. 25, 1986; p. 34 HT: Dembski, Truman]: 1 WDL*MNLT*DTJBKWIRZREZLMQCO*P
2? WDLTMNLT*DTJBSWIRZREZLMQCO*P
10 MDLDMNLS*ITJISWHRZREZ*MECS*P
20 MELDINLS*IT*ISWPRKE*Z*WECSEL
30 METHINGS*IT*ISWLIKE*B*WECSEL
40 METHINKS*IT*IS*LIKE*I*WEASEL
43 METHINKS*IT*IS*LIKE*A*WEASEL
1 Y*YVMQKZPFJXWVHGLAWFVCHQXYPY
10 Y*YVMQKSPFTXWSHLIKEFV*HQYSPY
20 YETHINKSPITXISHLIKEFA*WQYSEY
30 METHINKS*IT*ISSLIKE*A*WEFSEY
40 METHINKS*IT*ISBLIKE*A*WEASES
50 METHINKS*IT*ISJLIKE*A*WEASEO
60 METHINKS*IT*IS*LIKE*A*WEASEP
64 METHINKS*IT*IS*LIKE*A*WEASEL
2
--> What is happening here may best be summarised in the words of
the author himself, prof Richard Dawkins, suitably highlighted:
I don't know who it was first pointed out that, given
enough time, a monkey
bashing away at random
on a typewriter
could produce all the works of Shakespeare.
[NB: cf above] and this discussion on chance, necessity and intelligence.] The operative phrase is, of course, given enough time. Let us limit
the task facing our monkey somewhat. Suppose that he has to produce,
not the complete works of Shakespeare but just the short sentence
'Methinks it is like a weasel',
and we shall make it relatively easy by giving him a typewriter with
a restricted keyboard, one with just the 26 (capital) letters, and a
space bar. How long will he take to write this one little sentence? . . . .
It . . . begins by choosing a random
sequence of 28 letters ... it duplicates it
repeatedly, but with a certain chance of random error
– 'mutation' – in the copying. The
computer examines the mutant
nonsense phrases, the 'progeny' of the original phrase, and chooses
the one which, however
slightly, most resembles
the target phrase, METHINKS IT IS LIKE A WEASEL . . . . What
matters is the difference between the time taken by cumulative
selection, and the time which the same computer, working flat out at
the same rate, would take to reach the target phrase if it were
forced to use the other procedure of single-step selection:
about a million million million million million years. This is more
than a million million million times as long as the universe has so
far existed . . . .
Although the monkey/Shakespeare model is useful for
explaining the distinction between single-step selection and
cumulative selection, it is misleading in important ways. One of
these is that, in each generation of selective 'breeding', the mutant
'progeny' phrases were judged according to the criterion of
resemblance to a distant ideal target, the phrase METHINKS IT
IS LIKE A WEASEL. Life isn't like that. Evolution has no long-term
goal. There is no long-distance target, no final perfection to serve
as a criterion for selection, although human vanity cherishes the
absurd notion that our species is the final goal of evolution. In
real life, the criterion for selection is always short-term, either
simple survival or, more generally, reproductive success. [TBW, Ch 3, as cited by Wikipedia, various emphases and colours added.]
3
--> In short, Weasel is picking a line of descent of "champions" by
cumulative selection from generational populations created by random variation of a
previous champion (or, of course, the initial "nonsense phrase"). It is
intended to illustrate the power of "cumulative selection" vs what is
dismissed as "single step" selection. It is also acknowledged that the
selection process used is not at all parallel to what is expected in
the real world: natural selection and the like which respond to present functionality or want thereof, rather than foresighted
targetted selection. But, it is held that Weasel aptly illustrates the advantages of "cumulative selection."4 --> However, it is credibly the case
that the DNA for the simplest realistic life form will be about
600,000 bits of infomation storage capacity, which specifies a
configuration space of rather roughly 1 in 10^180,000. Also, innovative
major body plans relative to that will require some 10's - 100's of
millions of additional bits, as is discussed in the main text of this
note. By contrast the space of 28, 27-state elements has 27^28 ~ 1.2 *
10^40 states. That is, the
"single step" that Mr Dawkins would dismiss and avoid by resort to
hill-climbing is itself vastly too small to be relevant to the
complexity of first life.
So, from the outset, the Weasel program fails to address the real issue
posed by the need to credibly get to the functionally specific complex
information required to implement a viable life form, before hill-climbing can be properly applied. 5
--> Summed up, Weasel begs the
key question at stake, for (i) it substitutes an intelligently
designed,
cumulative, foresighted selection process for the ones that would be
relevant to what is needed if natural selection and the like are to
account for body plans. Worse, (ii) it does not impose a realistic
degree of initial or comparative function as a criterion of
initial selection, so that (iii) "nonsense phrases" are
allowed to progress to the target whereas (iv) in the biological world
non-functional forms would not work as living entities or would fail
to reproduce adequately; in fact, would be culled out by failure to function and/or reproduce as well as their competitors.
Thus, Weasel is indeed "misleading."6 --> Next, the
excerpted runs of champions for Weasel 1986 above show how, of over 300
possible cases where a correct letter may change in principle, the o/p
goes correct in some 200+ of them, and never once reverts
in the
published sample. (The highlighted N, * and T in the first case show
this with particular force. Notice, also, how the fact that by
happenstance three initial letters were correct seems to have cut off 20
generations in the run, by comparison with the second case.) Relevant
to all of this, on the law of large numbers [the valid form of the
layman's law of averages], we may see that if a population
has a segment x of probability p [where this is really relative
statistical weight in the distribution as a whole) and we take a sample
of size N, the expected occurrence of x in the sample is N*p.
And, as N*p --> ~ 1, from the low side, we can reasonably deem
x an observable event.7 --> The law of large numbers -- that as
sample size N frrom a large population rises, the likely number of
observations of a phenomenon x of probability p will tend to N*p -- can be visualised and experimented with. So, to help us to see why it makes
sense, let's imagine a typical bell-shaped statistical
distribution chart or a Reverse-J distribution chart, and draw
it on say bristol board, backing it on perhaps a sheet of particle board. DARTS AND CHARTS EXERCISE: If we divide the chart into even-width stripes, say 5 - 9 bands or so, and then drop darts on it from a sufficient
height that the darts more or less will hit the chart in an evenly
scattered way, we can easily observe how a sample builds up a picture of a
population. How: simply count the relative number per strip and compare to
the relative area per strip; which is of course a good measure of
probability. One hit will be more or less anywhere. A few will be quite
scattered, but by the time we get to
2 - 3 dozens, we will usually have a fair view of the bulk of the
distribution, i.e. relative number of hits per strip is beginning to correspond
to the fractional area the strip represents. (Indeed,
that is
why 20 - 30 is a useful rule of thumb cutoff for doing small
statistical samples;
for if 30* p = 1, p = 0.03.) Also, as we mount up into the low
hundreds, the far tails of the distribution will as a rule begin to
show up in the sample: if 300 * p = 1, p = 0.003. [As a
consequence, key statistical parameters such as averages of large
enough and reasonably random samples will tend to the average of
the actual population.]
8 -->
So, we have reasonably good reason to infer that the samples above are
more or less representative of the published "good" runs of what have
for convenience been called generational champions,
circa 1986. And indeed, since Mr Dawkins was trying to illustrate the
power of "cumulative selection" to achieve an otherwise utterly
improbable target, we can very reasonably conclude that the observed
no-reversions excerpts of runs were reflective of and showcased what
was happening at large with "good" runs. That is, beyond reasonable
dispute, the good runs circa 1986 latched the o/p's in the sense that
once a letter went correct it stayed that way; as the sequence of
generational champions ratcheted their way ever closer to the target,
hitting it in the published cases in 40+ and 60+ generations.
(And BTW: the New Scientist case is a
reproduction of one of the two in TBW. Also, during the UD exchanges, a 1987
BBC Horizon video of a Weasel run was linked. The rather long and fast
run showed quite frequent reversions and a strange "winking" effect
where repeatedly the reverting letter often very rapidly seemed to come
back to correct . . . an incorrect letter should revert to the dynamics
of a fairly slow search. The 1987 plainly unlatched
runs seem to exhibit considerably different behaviour than the
showcased steady, cumulative progress presented and described in 1986. This is suggestive -- on preponderance of the lines of evidence -- of
a material difference in the program; probably its parameters (e.g.
population size, mutation rate and/or filter characteristics).)9 -->
In principle all of the described events could happen by random
chance, as a chance sequence
can mimic any pattern whatsoever (one of the challenges of empirically
based inductive reasoning, which reveals the relevance and practical
value of the explanatory filter).
However, on general principles, this is so improbable that we may
discount it as a serious explanation; and indeed, Mr Dawkins deprecated
such as being "single step selection," which he was trying to show was
not a serious challenge to the power of the BLIND watchmaker of the
book's title. 10 --> Back story: Mr Hoyle had
raised the issue that the origin of a first life form -- such as,
roughly, a bacterium -- is a matter of such complexity that the odds of
that happening in a prebiotic soup by chance was negligible.
In a more up to date form, this is the challenge that is still raised
by the design theory movement: life shows a threshold of function at
about 600,000 bits of DNA storage capacity, so before one may properly
apply hill climbing algorithms to scale Mt Improbable, one needs first
to have a credible BLIND watchmaker mechanism to land one on the shores
of Isle Improbable; e.g. drifting by reasonable random configurations of molecules in
empirically justified pre biotic soups and empirically credible pre-life selection forces. (But, as we can see
from Section B above, this OOL challenge is still unmet. And
similarly, Section C shows how the origin of body plan level
biodiversity requiring 10's - 100's or millions of bits of functional
genetic information, dozens of times over, is equally unmet.) 11 --> So, it
looks uncommonly like Weasel distracts attention from and begs the
question. That sums up the balance on the main issue. However, the latching question is clearly in need of a responsible answer. 12 --> To explain the latching more realistically, we may have an explicit latching
algorithm based on letterwise search, i.e. the 28 letter Weasel
sentence is split up (partitioned) into 28 targets, with each taking up
states from
the set {A, B, C . . . Z and * (for space)}. A random search proceeds
in 28 parallel columns, and as each letter hits its target, it is
preserved. (The easy way to
do that is to set up a mask register. Such a register also suggests a
simple measure of proximity: if a letter is correct [ C], we assign a
distance value 0. If it is incorrect [I], we assign a distance value 1.
So, 28 incorrect letters gives distance 28, and 28 correct ones give
distance 0. Once a letter in a champion for a generation goes to 0, we
mask it off from further random change -- i.e. EXPLICIT latching. Of
course, the odds of a given letter going correct are of order 1 of 27.
A two letter word, e.g. "it" is one of 27^2 = 729 random possibilities.
A 4-letter unique word such as "like" is one of 27^4 = 531,441
configurations, an 8-letter one like "methinks" is one of 2.8 * 10^11
eight-letter clusters, and a specific 28-letter sentence is one of 1.2
* 10^40 configurations. That is, we see that even so crude an analogy
to bio-function as forming a word or phrase makes for an exponentially
growing search challenge as the required digital string's length
increases. So, threshold of initial effective functionality is a serious constraint on the credibility of Weasel and similar exercises.)13
--> Letterwise partitioned search is also a very natural way to understand the Weasel o/p in light
of Mr Dawkins' cited remarks about cumulative selection and rewarding
the slightest increment to target of mutant nonsense phrases. As such, it has long been and remains a
legitimate interpretation of Weasel. However, on recently and
indirectly received reports from Mr Dawkins, we are led to
understand that he did not in fact explicitly latch the o/p of Weasel,
but used a phrasewise search. 14 --> Q: Can that be consistent with an evidently latched o/p? ANS: yes, for IMPLICIT latching is possible as well.
15
--> Namely, (i) the mutation rate per letter acts with (ii) the size of
population per generation and (iii) the proximity to target filter to
(iv) strongly select for champions that will preserve currently correct
letters and/or add new ones, with sufficient probability that we will
see a latched o/p. (This effect has in fact been demonstrated through runs of the EIL's recreation of Weasel.) 16
--> in a slightly weaker manifestation, the implicit mechanism
will have more or less infrequent cases of letters that will revert to incorrect status;
which has been termed implicit quasi-latching.
This too has been demonstrated, and it occurs because an implicit latching
mechanism is a probabilistic barrier not an absolute one. So, as the
parameters are sufficiently detuned to make reversions occur, we will
see quasi-latched cases. Sometimes, under the same set of
parameters, we will see some runs that latch and some that quasi-latch.17
--> In a litle more detail, we will see reversions in a case where
the odds of mutation per letter are sufficientluy low that in a
reasonable generation of size N, there will be a significant fraction
of no-change members, and so the proximity filter will select no-change to be next champion, or a single step
increment in proximity; or, in some cases a substitution where one
correct letter reverts and one incorrect letter advances. 18 --> First, the odds of no-change in a population: A
letter in the string of length L [= 28] has probability of being
selected to mutate, s. Once so selected, it can equally take up any of
the g [= 27] available states at random. Of these, one is
identical to the original state and 26 are changed outcomes. So, we can
see that, for a given letter:
chance to be NOT selected = 1 - s
chance to be selecd but not change value = s * 1/g
overall chance to remain the same = (1 - s) + s/g
chance of no-change for a string of L letters = [(1 - s) + s/g]^L
Set s = 4%, Pno change = [0.96 + 0.04/27]^28 = 0.9615^28 = 0.333
(That is, about 1/3 of strings on average in a generation of mutants, will be unchanged.)
For a generation of N = 50, the chance that it will have no unchanged strings, then, is:
(1 - Pno change)^N = (1 - 0.333)^50 = 1.61*10^-9
19
--> In short, there is almost no chance that such a mutant
generation population will have no unchanged members. In that context,
with the proximity filter at work, no-change cases or substitutions or
single step advances will dominate the run of champions. Indeed,
the Weasel 1986 o/p samples show that runs to target took 40+ and
60+ generations, i.e. no-change won about half the time and single
step changes dominated the rest. No substitutions were observed in the
samples, suggesting strongly that there were none in the showcased
runs. (Double step advances etc or substitutions plus advances will be
much less probable. But in principle, per sheer "luck," we could see the very first
random variant going right to the target. Just, the odds are
astronomically against it. As, probabilistic barriers may be stiff, but are not absolute roadblocks.)
20 --> Let us now broaden the analysis in light of these patterns of behaviour:
chance of selection per letter = s.
[NB: We are working with s = 4% for illustrations, as that is the default setting at the EIL's Weasel page.]
raw per letter chance of reversion, PC-->I = s* (g -1)/g [= 0.04 (27 - 1)/27 = 0.0385, for s = 4%]
similarly, per letter chance of advance, PI-->C = s*(1/g) = s/g [ = 0.04/27 = 0.00148, for s = 4%]
21 --> CASE A: (L - c) incorrect letters in a string, one or more becoming correct:
chance of selecting none = (1 - s)^[L-c]
so, chance to select at least one changing letter = {1 - (1 - s)^[L-c]}
Now also, single change will dominate, so for the string:
PI-->C ~ (1/g)*{1 - (1 - s)^[L-c]}
E.g. 1: c = 1, PI-->C ~ 1/27 * {1 - 0.96^27} = 0.0247
E.g. 2: c = 14, PI-->C ~ 1/27 * {1 - 0.96^14} = 0.0161
E.g. 3: c = 27, PI-->C ~ 1/27 * {1 - 0.96} = 0.00148
In a population of N such strings, the expected number of such advancing letters is N*PI-->C , and where N = 50:
E.g. 1: c = 1, 0.0247 * 50 = 1.24
E.g. 2: c = 14, 0.0161 * 50 = 0.81
E.g. 3: c = 27, 0.00148 * 50 = 0.074
22 --> CASE B: c correct letters in a string, one or more becoming incorrect:
chance of selecting none = (1 - s)^c
chance to select at least one = [1 - (1 - s)^c]
Since, again single change instances will dominate the string:
PC-->I ~ [(g - 1)/g]*[1 - (1 - s)^c]
E.g. 1: c = 1, PC-->I ~ 26/27 * [1 - 0.96] = 0.0385
E.g. 2: c = 14, PC-->I ~ 26/27 * [1 - 0.96^14] = 0.419
E.g. 3: c = 27, PC-->I ~ 26/27 * [1 - 0.96^27] = 0.643
23 --> CASE C: a substitution, i.e. a joint occurence of one letter advancing to correct while one retreats to incorrect:
Ps = PI-->C*PC-->I
so, Ps ~ (1/g)*{1 - (1 - s)^[L-c]} * [(g - 1)/g]*[1 - (1 - s)^c]
E.g. 1: c = 1, Ps ~ 0.0247 * 0.0385 = 0.00951
E.g. 2: c = 14, Ps ~ 0.0161 * 0.419 = 0.00675
E.g. 3: c = 27, Ps ~ 0.00148 * 0.643 = 0.000952
Thus
also, for a population of such strings, of size N [= 50 in the default
example], the expected number of such occurences is N* Ps:
E.g. 1: c = 1, N* Ps ~ 50 * 0.00951 = 0.48
E.g. 2: c = 14, N* Ps ~ 50 * 0.00675 = 0.34
E.g. 3: c = 27, N* Ps ~ 50* 0.000952 = 0.0048
(Such numbers suggest that substitutions are reasonably observable within the population per generation.)
24
--> In turn that means that a further key issue on champion
selection per generation is the specific action of the proximity filter, in a
context where -- continuing the concerete example -- the expected
number of zero change cases in a generation is about 17, that for
single step advances is about
1, and that for substitutions ranges from 1/2 down to 5/1000, depending
on degree of proximity already acheived. That turns out to be a fairly
complex issue:
a] It would be
possible to measure proximity letter by letter for a string, e.g. by
assigning 1 for a miss, 0 for a hit (as mentioned above); so that the
proximity scale ranges from 28 to 0, the latter being the target
sentence. In that case, substitutions have the same proximity as
no-change cases.
b] If the proximity filtering tie-breaker rule is established that on no
letter being closer than the previous champion used to generate the N
mutants in a given generation, we skip the generation, re-use the
champion and go on to the next generation, no substitution cases would
appear in the run of champions.
c] if the rule instead is that
on every such case, a string different from the previous champion is
chosen, we will probably see relatively frequent substitutions. (There would be no apparent latching.)
d] If
instead, the rule is to have a lottery of the closest strings,
no-change cases will dominate but occasional substitutions will break
through; creating a more or less quasi-latched outcome.
e] It is also
possible to measure proximity in various ways based on the bit values of the underlying ASCII codes for
letters, which count up in the range [A, B, C, D . . . Z}. In that
case, very complex outcomes will be possible, depending on how close
the run is to target, and the specific letters that have been
substituted or have reverted to what values, relative to the codes for
the target.
25 --> Case [e] just above is the most
likely case, and its further complexity easily explains why Weasel type
programs can show considerably diverse behaviour, including implicit
latching, quasi-latching and non-latching.
26
--> Even more interesting, it is possible to program an explicitly
latched algorithm to show reversions, substitutions and the like. This
means that only credible code can prove what is what for sure. But, in
the case in view, the testimony as reported can be taken as indicating
that explicit latching was not used in 1986. In that case, we have good
reason to infer to implicit latching as just discussed, or at least
quasi-latching.
We can now close the circle, by again citing the remarks in the December thread again as a well-substantiated conclusion:
[UD December 2008 Unpredictability thread, excerpt from comment 107:] . . . the problem with the
fitness landscape [model] is that it is flooded by a vast sea of
non-function, and the islands of function are far separated one from
the other. So far in fact . . . that searches on the order of
the quantum state capacity of our observed universe are hopelessly
inadequate. Once you get to the shores of an island, you can climb
away all you want using RV + NS as a hill climber or whatever model
suits your fancy.
But you have to get TO the shores first. THAT is the real, and too often utterly unaddressed or brushed aside, challenge.
[NB: And, in fact, that was the challenge Sir Fred Hoyle had posed. A
challenge that Weasel, from its outset, has ducked and distracted
attention from. Weasel is -- and has always been -- a question-begging
strawman fallacy.]
And . . . that [unmet challenge] starts with both the
metabolism first and the D/RNA first schools of thought on OOL. As
indeed Shapiro and Orgel recently showed . . . .
[ slice from comment no 111: ]
Weasel [i.e. c. 1986] sets a target sentence then once a letter is guessed it
preserves it for future iterations of trials until the full target is
met. [that is, I inferred that Weasel latches the o/p as is likely from the below.] That means it rewards partial but non-functional success, and is
foresighted. Targetted search, not a proper RV + NS model. [Emphases and notes added.]
APPENDIX 8:
Of the inference to design and
the origin and nature of mind [and thence, of morals]
by GEM of TKI [responsible for
content],
with significant stimulating suggestions, critiques and other
inputs from FROSTY at UD
As at
April 2008, a
thread at UD has drawn out an interesting link between the
inference to design and the origin and nature of mind [and thence, of
morality]. The heart of that connexion may be seen from an adapted form
of an example by Richard Taylor:
. . . suppose you were in a
train and saw [outside the window] rocks you believe were pushed there
by chance + necessity only, spelling out: WELCOME TO WALES.
Would you believe the apparent message, why?
Now,
it is obviously highly improbable [per the
principles of statistical thermodynamics applied to, say, a
pile of rocks falling down a hill and scattering to form randomly
distributed patterns]. But, it is plainly logically and physically possible
for this to happen.
So,
what would follow from -- per thought experiment -- actually having
"good reason" to believe that this is so?
1
--> We know, immediately, that chance + necessity, acting on a
pile of rocks on a hillside, can make them roll down the hillside and
take up an arbitrary conformation. There
thus is no in-principle reason to reject them taking up the shape:
"WELCOME TO WALES" any more than any other configuration. Especially if, say, by extremely
good luck we have seen
the rocks fall and take up this shape for ourselves. [If that ever
happens to you, though, change your travel plans and head straight for
Las Vegas before your "hot streak" runs out! (But also, first check
that the rocks are not made of magnetite, and that there is not a
magnetic apparatus buried under the hill's apparently innocent turf!
"Trust, but verify.")]
2
--> Now, while you are packing for Vegas [having verified that the
event is not a parlour trick writ large . . . ], let's think a bit: [a]
the result of the for- the- sake- of- argument stroke of good luck is an apparent
message, which was [b] formed by chance + necessity only
acting on matter and energy across space and time. That is, [c] it
would be lucky noise
at work. Let
us
observe, also: [d] the shape taken on by the cluster of rocks as they
fall
and settle is arbitrary, but [e] the meaning assigned to the apparent
message is
as a result of the imposition of symbolic meaning on certain glyphs
that take up particular alphanumerical shapes under certain
conventions. That is, it is a mental
(and even social) act. One pregnant with the points that [f] language
at its best refers accurately to reality, so that [g] we often trust
its deliverances once we hold the source credible. [Indeed, in the
original form of the example, if one believes that s/he is entering
Wales on the strength of seeing such a rock arrangement, s/he would be grossly irrational to also believe the intelligible and aptly functional arrangement of rocks to have been
accidental.]
3
--> But, this brings up the key issue of credibility:
should we
believe the substantial contents of such an apparent message sourced in
lucky noise rather than a purposeful arrangement? That is, would it be
well-warranted to accept it as -- here, echoing Aristotle in Metaphysics, 1011b --
"saying of what is,
that it is, and of what is not, that it is not"? (That is, (i) is such an apparent message credibly a true
message? Or (ii) is any observed truth in it merest coincidence?)
4
--> The answers are obvious: (i) no, and (ii) yes.
For, the adjusted example aptly illustrates how cause-effect chains tracing to
mechanical necessity and chance circumstances acting on matter and
energy are utterly unconnected to the issue of making logically and
empirically well-warranted assertions about states of affairs in the
world. For a crude but illuminating further
instance, neuronal impulses are in volts and are in specific locations
in the body; but the peculiarly mental aspects -- meaningfulness, codes, algorithms, truth and
falsehood, propositions and their entailments, etc -- simply are not like that.
That is, mental
concepts and constructs are radically
different from physical entities, interactions and signals.
5 --> So, it is highly questionable (thus needs to be shown not merely
assumed or asserted) that such radical differences could or do credibly
arise from mere interaction of physical components under only the
forces of chance and blind mechanical necessity. For this demonstration, however, we seek in
vain: the matter is routinely assumed or asserted away, often by claiming (contrary to the relevant history and philosophical considerations)
that science can only properly explain by reference in the end to such
ultimately physical-material forces. Anything less is
"science-stopping."
6 --> But in fact, in say a
typical real-world cybernetic system, the physical
cause-effect chains around a control loop are set up by intelligent,
highly skilled designers who take advantage of and manipulate a wide
range of natural regularities. As a result, the sensors, feedback,
comparator, and forward path signals, codes and linkages between
elements in the system are intelligently organised to cause the desired interactions
and outcomes of moving observed plant behaviour closer to the targetted
path in the teeth of disturbances, drift in component parameters, and
noise. And, that intelligent input is not simply reducible to the happenstance of accidental collocations and interactions of physical forces, bodies and materials.
7 --> Further, as UD commenter Frosty pointed out in the linked UD thread,
Leibnitz long ago highlighted one of the key challenges to an
emergentist, property- and/or emanation- of- matter view of perception
[and thence consciousness etc.], in The Monadology,
16 - 17. So, giving a little context to see what Leibnitz means by
monads etc, and without endorsing, let us simply reflect on what is now
probably a very unfamiliar way to look at things; noting his
astonishing remarks on the analogy of the mill in no 17:
1. The monad, of which we will speak here, is
nothing else than a simple substance, which goes to make up compounds;
by simple, we mean without parts.
2. There must be simple substances because there are compound
substances; for the compound is nothing else than a collection or
aggregatum of simple substances.
3. Now, where there are no constituent parts there is possible neither
extension, nor form, nor divisibility. These monads are the true atoms
[i.e. "indivisibles," the original meaning of a-tomos] of nature,
and, in a word, the elements of things . . . .
6. We may say then, that the
existence of monads can begin or end only all at once,
that is to say, the monad can begin only through creation and end only
through annihilation. Compounds,
however, begin or end by parts . . . .
14. The passing condition which involves and represents a multiplicity
in the unity, or in the simple substance, is nothing else than what is
called perception. This should be carefully distinguished from
apperception or consciousness . . . .
16. We, ourselves, experience a multiplicity in a simple substance,
when we find that the most trifling thought of which we are conscious
involves a variety in the object. Therefore all those who acknowledge
that the soul is a simple substance ought to grant this multiplicity in
the monad . . . .
17. It must be confessed, however, that perception, and that which
depends upon it, are inexplicable by mechanical causes, that is to say,
by figures and motions. Supposing that there were a machine
whose structure produced thought, sensation, and perception, we could
conceive of it as increased in size with the same proportions until one
was able to enter into its interior, as he would into a mill. Now, on going into it he would
find only pieces working upon one another, but never would he find
anything to explain perception. It is accordingly in the
simple substance, and not in the compound nor in a machine that the
perception is to be sought. Furthermore, there is nothing
besides perceptions and their changes to be found in the simple
substance. And it is in these alone that all the internal activities of
the simple substance can consist.
8 -->
We may bring this up to date by making reference to more modern views
of elements and atoms, through an example from chemistry. For instance,
once we understand that ions may form and can pack themselves into a
crystal, we can see how salts with their distinct physical and chemical
properties emerge from atoms like Na and Cl, etc. per natural
regularities (and, of course, how the compounds so formed may be
destroyed by breaking apart their constituents!). However, the real
issue evolutionary materialists face is how to get to mental
properties that accurately and intelligibly address and bridge the
external world and the inner world of ideas. This, relative to a worldview
that accepts only physical components and must therefore arrive at other
things by composition of elementary material components and their
interactions per the natural regularities and chance processes of our
observed cosmos. Now, obviously, if the view is true, it will be
possible; but if it is
false, then it may overlook other possible elementary constituents of
reality and their inner properties. Which is precisely
what Liebnitz was getting at.
9 --> Indeed, Richard Taylor speaks to this too:
Just
as it is possible for a collection of stones to present a novel and
interesting arrangement on the side of a hill . . . so it is possible
for our such things as our own organs of sense [and faculties of
cognition etc.] to be
the accidental and unintended results, over ages of time, of perfectly
impersonal, non-purposeful forces. In fact, ever so many biologists
believe that this is precisely what has happened . . . . [But] [w]e
suppose, without even thinking about it, that they [our sense organs
etc] reveal to us things that have nothing to do with themselves, their
structures or their origins . . . . [However] [i]t would be irrational
for one to say both
that his sensory and cognitive faculties had a natural, non-purposeful
origin and also
that they reveal some truth with respect to something other than
themselves . . . [For, if] we do assume that they are guides to some
truths having nothing to do with themselves, then it is difficult to
see how we can, consistently with that supposition [and, e.g. by
comparison
with the case of the stones on a hillside], believe them to have
arisen by accident, or by the ordinary workings of purposeless forces,
even over ages of time. [Metaphysics,
2nd Edn, (Prentice-Hall, 1974), pp 115 - 119.]
10 -->
A more elaborate example, from cybernetics, will help
reinforce the point. For, we can understand -- perhaps after a
bit of study (cf. the biomedical applications-oriented
discussion here
too) -- how feedback control loop elements interact. But as already mentioned, the
intelligence of the system that gives rise to its performance lies in
the design and the resulting built-in active information,
not mere physicality, accidental proximity and chance
co-adaptation of physical components and their parts. Moreover, it is
evident that the probability of
spontaneous assembly of such a system by undirected chance +
necessity, on the gamut of our observed cosmos, is
vanishingly different from zero. This extends to case after case, once
we see functionally specified, complex information at work and directly
know the origin of the system.
11 -->
Moreover, as C S Lewis aptly put it (cf. Reppert's discussion here),
we can see that the
physical relationship between cause and effect is utterly distinct from
the conceptual and logical one between ground and consequent,
and thus we have no
good reason to trust the deliverances of the first to have anything
credible to say about the second. Or, as Reppert aptly brings
out:
.
. . let us suppose that brain state A, which is token identical to the
thought that all men are mortal, and brain state B, which is token
identical to the thought that Socrates is a man, together cause the belief
that Socrates is mortal. It
isn’t enough for rational inference that these events be those beliefs,
it is also necessary that the causal transaction be in virtue of the content of
those thoughts . . . [But]
if naturalism is true, then the
propositional content is irrelevant to the causal transaction
that produces the conclusion, and [so] we do not have a
case of
rational inference. In rational inference, as Lewis puts it, one thought causes another
thought not
by being, but by being seen
to be, the ground for it. But causal
transactions in the brain occur in virtue of the brain’s being in a
particular type of state that is relevant to physical causal
transactions. [Emphases added. Also cf. Reppert's summary of Barefoot's
argument here.]
12
--> Indeed, so obvious and strong are the implications
of the Wales example, that in the relevant UD discussion thread, objectors
repeatedly insisted on trying to turn the discussed case of lucky noise "credibly" making an
apparent message into the very different one of creation
of an intentional message by presumably human agents. The next step was
to triumphantly announce that there is "no evidence" of other
intelligent, verbalising, writing agents out there. One even went on to
suggest that a pure mind could not interact with matter to form such
messages; indeed, that an immaterial mind could not interact
with the material realm, and so could
not have "experiences." [Shades
of Kant!] Later on, another objector tried to turn
this into a discussion on origin of life (while pointedly not reckoning
with the force of Sections A,
B and C
above). S/he also suggested that natural selection was a naturally
occurring filter that would tip the odds substantially towards chance +
necessity producing intelligent information and systems capable of
handling it with reliability and accuracy. In short, sadly, we
saw
the insistent substitution of a convenient strawman
or two for the actual case to be considered on the merits.
13
--> However, as it is further revealing, it is worth pausing a
moment, to deal with such objections:
a] The resort to the
above strawman arguments first inadvertently shows that many objectors to the inference
to design are fully aware that the basic structure of the design
inference is an empirically and epistemologically well-warranted induction.
For, [a] when we see natural
regularities, we see low contingency and explain in terms of mechanical
necessity (e.g. how a die falls to, tumbles across and
then eventually sits on a table); [b] when we see high contingency, it
is by chance
or design
(e.g. which face of the die is uppermost); [c] when an outcome is
sufficiently improbable/complex and functionally specific that
available probabilistic/search resources could not credibly have arrived at
the relevant configurations by chance, it is much more likely to be agency than
chance (e.g. a sufficiently
long string of dice that, together, spell out a message in a
recognisable code).
b] So, per
inference to best causal explanation across necessity, chance and
agency, when we see functionally
specified complex information [FSCI], intelligent action
is generally to be preferred, at least on that provisional basis
that attends to all scientific inferences.
c] What is
done next is to try to use the
Elliot Sober argument: restricting
such inference to cases of "independently" observed agents only.
But, the first problem is that we have no good grounds for assuming or
asserting that humans exhaust either (i) the set of actual or (ii) that of
possible intelligent agents. Secondly, the immediate implication of our
own existence is that intelligent agents are possible in our cosmos.
Thirdly, once we see --
per repeated empirical observation -- that signs such as FSCI
reliably point to intelligent action, then when we see such signs, that
is in itself empirical evidence pointing to such an agent at work.
Fourthly, and as just highlighted, the reasoning used is not specific
to human-ness, but instead to intelligent agency: as the Wales example shows,
chance and necessity -- per the vast
improbabilities involved -- simply cannot credibly
do what intelligent agents reliably and routinely can; on the gamut of
our observed cosmos.
d] So, the
Sober-style objection is question-begging. For, in fact, even among ourselves, we recognise
agency from the works of such agents -- the signs of intelligence they
leave behind; of which FSCI is a most obvious and routine example. (Q: How do you know to moral certainty that this web page is not lucky noise mimicking a signal? A: By inference to agency from FSCI as a reliable sign thereof. So:
As long as agency is logically possible in a situation, we should
be open to recognising it from its signs and associated circumstances.)
e] Next, we have reason to note that the
observed cosmos' underlying physics reflects multi-dimensional,
convergent, fine-tuned, highly complex, functional order that
facilitates cell-based life, and similar reason to note that the said
observed cosmos credibly began at a specific time in the past. Thus, we
have good reason to infer (per inference to best, empirically anchored
explanation) that the origin of the cosmos itself is marked by the signs
of purposeful intelligent design. And, pace the remarks of
objectors, as the just linked section discusses, that IS evidence of
non-human intelligent agent(s). [For, "mere objection
on your part does not constitute "absence of evidence" on my part"!]
f]
Moreover, since we are speaking of the beginnings of our observed
matter-energy and space-time domain, said inferred intelligence was
credibly able to create -- thus, interact with -- matter
while not being material; this last referring to the "stuff" of the
physical cosmos. For, matter is here an effect, not a cause, and -- per
self-evident proposition -- an entity cannot cause its own origin.
(Classically: "that which begins has a cause, but that which has no
beginning needs have no cause"; i.e we are here
raising the issue of the difference between contingent and necessary
beings; duly modified by the observation that we credibly live
in an observed, contingent cosmos. And, the most credible
"alternative," in effect a quasi-infinite array of sub cosmi, is just
as much a metaphysical proposition -- and one that runs into much more
serious difficulties on a
comparative basis. )
g]
Consequently, it is not at all an obvious given that a "pure mind"
entity would be unable to observe, interact with, speak into and act
upon -- thus, experience
-- the physical world.
h] Indeed,
considering our own minds and brains, the brain is a bodily, material
entity; subject therefore to chance and necessity under the
electrochemical etc. forces and interactions acting on and in it. Thus
(given the Wales example) it is not credible as the ultimate
source of messages and actions that point -- beyond the credible reach
of such forces -- to intelligent, purposeful, creative [as opposed to
mere random], functionally successful action. (NB: The Derek
Smith cybernetic model of a two-tier controller for
a biologically relevant system, with the upper level strategic,
imaginative and creative controller guiding and overseeing a lower
level one acting as a supervised input-output controller, may be a
fruitful discussion model for a mind-brain system. For instance, one -- for
the sake of argument -- may look at a mind as using
quantum gaps to "feed" signals into the brain-body system.)
i] When we
come to the natural selection argument, we first need to address the
problem of origin of life models that was aptly posed by Robert Shapiro
in challenging the popular RNA world model. Adverting to the gap
between what presumably purposeful and intelligent chemists can do by
design in labs and what was credible in plausible prebiotic
environments, he
noted -- in words that inadvertently are equally applicable
to his own preferred metabolism first model:
The analogy that comes to mind
is that of a golfer, who having played a golf ball through an 18-hole
course, then assumed that the ball could also play itself around the
course in his absence. He had demonstrated the possibility of the
event; it was only necessary to presume that some combination of
natural forces (earthquakes, winds, tornadoes and floods, for example)
could produce the same result, given enough time. No physical law need
be broken for spontaneous RNA formation to happen, but the chances
against it are so immense, that the suggestion implies that the
non-living world had an innate desire to generate RNA. The majority of
origin-of-life scientists who still support the RNA-first theory either
accept this concept (implicitly, if not explicitly) or feel that the
immensely unfavorable odds were simply overcome by good luck. [Emphasis added.]
j]
When it comes to the proposal that "natural selection" credibly accounts
for the mind, Plantinga highlights
that [a] natural selection is said to reward successful adaptations, but
also that [b] the inner thought world is not directly connected
to the success of survival-enhancing
behaviour. Consequently [c] such mind-blind, behaviour-oriented
selection cannot ground
the reliability or accuracy of perceptions, inferences or motivations
for action. In Plantinga's words:
.
. . evolution is interested (so to speak) only in adaptive behavior,
not in true belief. Natural
selection doesn’t care what you believe; it is interested only in how
you behave. It selects for certain kinds of
behavior, those that enhance fitness, which is a measure of the chances
that one’s genes are widely represented in the next and subsequent
generations . . . But then the fact that we have evolved
guarantees at most that we behave in certain ways–ways that contribute
to our (or our ancestors’) surviving and reproducing in the environment
in which we have developed . . . . there are many belief-desire
combinations that will lead to the adaptive action; in many of these
combinations, the beliefs are false.
(Link.
Emphases added. [Note: even
major and well-supported scientific beliefs/models -- such as Newton's
laws of motion, circa 1680 - 1880 -- were/are not necessarily true
to actual reality but rather were/are empirically reliable under the
tested circumstances.] Cf. blog exchange contributions here,
here,
here,
and here.)
k] That
is why something is very wrong with Sir Francis Crick's remark in his
1994 The Astonishing
Hypothesis, to the effect that:
"You,"
your joys and your sorrows, your memories and your ambitions, your
sense of personal identity and free will, are in fact no more than the
behaviour of a vast assembly of nerve cells and their associated
molecules . . .
l]
Philip Johnson duly corrected him by asking whether he would be willing
to preface his own writings thusly:
"I,
Francis Crick, my opinions and my science, and even the thoughts
expressed in this book, consist of nothing more than the behavior of a
vast assembly of nerve cells and their associated molecules." [Reason in the Balance,
1995.]
m] In short, as Prof Johnson
then went on to say:
“[t]he
plausibility of materialistic determinism requires that an implicit
exception be made for the theorist.”
n] Thus, unless evident "fact no 1" -- that we are conscious, mental creatures who at least some of the time have freedom to think, intend, decide, speak, act and even write based on the logic and evidence of the situation -- is true, the project of rationality itself is at an end. That is, self-referential
absurdity is the dagger pointing to the heart of any such evolutionary materialistic
determinism as seeks to explain "all" -- including mind -- by "nothing
but" natural forces acting on matter and energy, in light of chance
boundary conditions. (This is as opposed to restricted, truly
scientific, explanations that explain [i] natural regularities
by reference to [a] underlying mechanical necessity,
and explain [ii]
highly contingent situations by reference to [b] chance
and/or [c] intelligent action. We then distinguish the two by
identifying and applying reliable signs of intelligence; similar to
what obtains in statistical hypothesis testing and in control-treatment
experiment designs and related factor analysis.)
14
--> So, as the Wales example and the debates it sparked
at UD have
brought out, the inference to design highlights the radical
difference between [1] what chance + necessity acting on matter +
energy
on the gamut of our observed
universe can credibly do (up to an apparent
message by lucky noise) and [2] what mind routinely does (i.e.
routinely creating real
messages). But [3] it thus also has in it an aspect that points to the
nature and origin of mind (and, thence, of morals as a particularly
important function of mind). Indeed, [4] in the cosmological form, the
inference to design also points to the serious possibility that mind is the source of matter,
not the converse. Inter alia, this would make it utterly
unsurprising that -- as we experience it every time we decide to speak
or type on a keyboard, or click a mouse button or the like --
mind can interact causally with matter, even though we may not
currently
know how
to explain just how
that happens. We know that mind, even though as yet we do
not really know how mind.
Howbeit,
it is also worth pausing to briefly speak to some possibilities,
plausibilities and constraints on that "how":
15
--> Classically, the
exact, mechanistic form of Newtonian physics
[e.g. F = m.a, Fgrav = G. m1.m2/r2]
as discovered in the C17 and associated differential
equations suggested to many C18 - 19 scientists and mathematicians
(often the same people) that once the universe's initial conditions
were specified, everything thereafter would have unfolded according to
precise trajectories set by the laws in light of those conditions.
(In praxis of course, even so simple a case as a
three-body gravitational system has proved astonishingly and
humblingly resistant to general solution.) But, never mind such
embarrassing little quibbles: the
Newtonian vision
lent great plausibility to the idea that the universe forms a closed,
mechanistic, naturalistic system, and to associated
determinism. (Of
course -- equally embarrassingly -- we now also know that in many systems
that exhibit sensitive dependence to initial conditions
and so have nonlinear amplification of minute differences in initial
conditions, the long-run behaviour is, practically speaking,
unpredictable.) In the end, though, even
when solution difficulty, chance conditions, random elements,
unpredictability
and random, stochastic processes have had to be recognised, there has
still been
a trend to evolutionary materialistic determinism. On such a view,
there is little or no room for immaterial entities or influences,
whether mental or spiritual. And, of course, miracles were then also
often viewed as literally incredible; i.e. they were dismissed by many
speaking in the name of "science" as credulous, superstitious nonsense.
16
--> Immediately, though, something is wrong. Very, very wrong.
17
--> For, first, Newtonian dynamics is arrived at by a process of
incremental scientific induction
and testing of explanatory hypotheses, which may be very persuasive but
which simply is not a demonstrative
proof. Indeed, strictly,
the inference IF
theory, THEN observations and predictions; observations and
predictions, so theory,
is the fallacy known as affirming
the consequent. In short, scientific knowledge is
inherently provisional and we should be critically aware,
humble and open-minded in approaching matters and claims of science.
Indeed, in the
period from the 1880's to 1930's, the then unexpected
limitations of Newtonian
physics were starkly revealed, as various quantum, statistical and
relativistic
phenomena came to the fore. (Oddly, the much derided and even despised
pope Urban VIII had warned
Galileo about precisely those sorts of limitations. [Cf also here.])
The early C20 jump from classical to modern physics
through a scientific
revolution therefore underscored that observed
patterns and even highly reliable well-tested explanations of such
patterns are not to be confused with a globally accurate view of
reality; i.e. the
truth. Further, as statistics warns us,
an observed, described, explained/modelled and tested pattern may be a
part of a wider more complex -- and not yet fully observed -- pattern.
So, it is plainly also wise for us to be open to the
possibility of
"exceptions"; including such that are so unusual and contextually
significant that we would not be amiss to call them "miracles."
18
--> Moreover, scientific induction is a process of thinking.
But, if
all that is, is "nothing but" matter and energy acted upon by purposeless
mechanical necessity and chance conditions, then allegedly reasoned
thought is in the end caused and controlled by circumstances and forces
that are utterly irrelevant to purpose, truth, validity, cogency or
soundness. There would thus be no room for truly logical
inference, which -- as the Wales example above shows -- fatally
undermines our confidence in the perceptions, consciousness, thoughts
and reasoning that we need. Even, to set up a deterministic,
materialistic system of thought.
19
--> Further to this, we must reflect on implications and
applications of Kurt Gödel's
justly famous incompleteness
theorems. For, KG showed in the early 1930's that [a] no axiomatic mathematical
system sufficiently rich to cover say ordinary arithmetic, can be both
internally consistent and complete, and [b] there is no constructive
process for devising a system of axioms for such a system that will be
known to be self-consistent. In effect,
Mathematico-logical reasoning [including computing and computation] are
irreducibly complex, non-mechanical ventures in which we may and often
do confidently know or believe more -- often, far more -- than we can
individually or even collectively deductively prove relative to any
sufficiently rich sets of axiomatic premises we may decide to use and
trust.
20 --> More generally, mind and knowing cannot be reduced to input ->
mechanical processing -> output
based algorithms
that deterministically grind out complete sets of "known truths"
premised on sufficiently rich, but elegantly sparse sets of axioms
acceptable to all sufficiently informed rational agents. (Often, the
relevant processing is not based on meanings, but on mechanical
manipulation of well-chosen symbols; based on
axioms, theorems and physical realisations of mathematical operations
and variables.)
21 --> Thus, deductive proof and associated mechanical
computing algorithms are now no longer credible as escape-hatches from the inextricable
intertwining of reasoning and believing in the core of our
worldviews, mathematics, science, real-world thinking and real-world
information technology. This, in short, is the end of mechanical
necessity as an engine to generate the field of knowledge and
associated effective, algorithm-based function. Creativity, imagination,
intuition and provisionality -- do I daresay, "faith" -- have won the
day, even in mathematics. (Indeed, in recent days, Hawking
is inclining to the view that this is also the end of the decades-long
project in physics to construct a global "theory of everything.")
22 --> So, we see Douglas Hofstadter
-- a critic, BTW, of such extensions of Gödel
--conceding in his Gödel, Escher,
Bach: an Eternal Golden Braid:
.
. . Godel's proof suggests -- though by no means does it prove! -- that
there could be some high-level way of viewing the mind/brain, involving
concepts which do not appear on lower levels, and that this level might
have explanatory power that does not exist -- not even in principle --
on lower levels. It would mean that some facts could be explained on
the high level quite easily, but not on lower levels at all. No matter
how long and cumbersome a low-level statement were made, it would not
explain the phenomena in question. It is analogous to the fact that, if
you make derivation after derivation in [Peano arithmetic], no matter
how long and cumbersome you make them, you will never come up with one
for G -- despite the fact that on a higher level, you can see that [the
Godel sentence] is true. What might such high-level concepts be? It has
been proposed for eons, by various holistically or "soulistically"
inclined scientists and humanists that consciousness is a phenomenon
that escapes explanation in terms of brain components; so here is a
candidate at least. There is also the ever-puzzling notion of free
will. So perhaps these qualities could be "emergent" in the sense of
requiring explanations which cannot be furnished by the physiology
alone [p. 708; emphases added.]
23 --> Pulling the various threads together, we may now find a
way for conscious reason to be credible [even if provisional], thus for
the
conscious reasoning mind that is sufficiently independent of -- though
obviously strongly interacting with -- the brain-body system, that we
can be confident in our thought. Otherwise, science itself falls into
self-referential incoherence, absurdity and confusion. A first step to
that, would be to examine some implications of quantum
uncertainty and related phenomena for the brain and the mind. For
instance, Harald Atmanspacher,
writing in the Stanford
Encyclopedia of Philosophy observes:
It
is widely accepted that consciousness or, more generally, mental
activity is in some way correlated to the behavior of the material
brain. Since quantum theory is the most fundamental theory of matter
that is currently available, it is a legitimate question to ask
whether quantum theory can help us to understand consciousness . . .
.
The
original motivation in the early 20th century for relating quantum
theory to consciousness was essentially philosophical. It is fairly
plausible that conscious free decisions (“free will”) are
problematic in a perfectly deterministic world,[1]
so quantum randomness might indeed open up novel possibilities for
free will. (On the other hand, randomness is problematic for
volition!)
Quantum
theory
introduced an element of randomness standing out against the previous
deterministic worldview, in which randomness, if it occurred at all,
simply indicated our ignorance of a more detailed description (as in
statistical physics). In sharp contrast to such epistemic randomness,
quantum randomness in processes such as spontaneous emission of
light, radioactive decay, or other examples of state reduction was
considered a fundamental feature of nature, independent of our
ignorance or knowledge. To be precise, this feature refers to
individual quantum events, whereas the behavior
of ensembles
of such events is statistically determined. The
indeterminism of individual quantum events is constrained by
statistical laws.
24 --> This brings in a new level of considerations, but is itself
not
unproblematic. For, mere randomness is not enough; we need a
viable mechanism of orderly, intelligent interaction.
25
--> To get to that, we may not only use the above noted
indeterminacy of particle behaviour as is found in Quantum theory; but
also, we apply Einstein's energy-time form of
the
Heisenberg uncertainty principle. For, at microscopic level force-based
interactions between bodies can be
viewed in terms of exchanges of so-called "virtual particles." That is, once the product of the energy
and time involved in a particle being exchanged between two interacting
bodies falls below the value of Planck's constant h (suitably
multiplied or divided by a small constant), bodies may interact through
exchanging undetected -- so, "virtual" -- particles. We
can in effect have a situation crudely similar to two people tugging or
pushing on opposite ends of a stick: they interact through the means
of the intervening stick; which we then see as attractions or
repulsions between the bodies. Thus, as the just linked
explains in more details, the quantum theory of forces and interactions
between bodies is now strongly based on Heisenberg's principle of
uncertainty; yet another case where the deterministic view has been
undermined, and one that opens the doorway to a model of the workings
of the brain-mind interface.
26 --> As Scott
Calef therefore observes:
Keith
Campbell writes, “The
indeterminacy of quantum laws means that any one of a range of
outcomes of atomic events in the brain is equally compatible with
known physical laws. And differences on the quantum scale can
accumulate into very great differences in overall brain condition. So
there is some room for spiritual activity even within the limits set
by physical law. There could be, without
violation of physical
law, a general spiritual constraint upon what occurs inside the
head.” (p.54). Mind
could act upon physical processes by
“affecting their course but not breaking in upon them.”
(p.54). If this is true, the dualist could maintain the conservation
principle but deny a fluctuation in energy because the mind serves to
“guide” or control neural events by choosing one set of quantum
outcomes rather than another. Further, it should be remembered that
the conservation of energy is designed around material interaction;
it is mute on how mind might interact with matter. After all, a
Cartesian rationalist might insist, if God exists we surely wouldn’t
say that He couldn’t do miracles just because that would violate
the first law of thermodynamics, would we? [Article, "Dualism and
Mind," Internet
Encyclopedia of Philosophy.]
27
--> Within this broad framework, there have been several
interesting suggestions. Of these, the
Penrose- Hameroff proposal is quite original:
It
is argued that elementary acts of consciousness are non-algorithmic,
i.e., non-computable, and they are neurophysiologically realized as
gravitation-induced reductions of coherent superposition states in
microtubuli . . . . Penrose's rationale for
invoking state reduction is not that the corresponding randomness
offers room for mental causation to become efficacious (although this
is not excluded). His conceptual starting point, at length developed in
two books (Penrose 1989, 1994), is that elementary conscious acts must
be non-algorithmic. Phrased
differently, the emergence of a conscious act is a process which cannot
be described algorithmically, hence cannot be computed. His background
in this respect has a lot to do with the nature of creativity,
mathematical insight, Gödel's incompleteness theorem, and the idea of a
Platonic reality beyond mind and matter . . . . With his background
as an anaesthesiologist, Hameroff suggested to consider microtubules as
an option for where reductions of quantum states can take place in an
effective way, see e.g., Hameroff and Penrose (1996). The respective
quantum states are assumed to be coherent superpositions of tubulin
states, ultimately extending over many neurons. Their simultaneous
gravitation-induced collapse is interpreted as an individual elementary
act of consciousness. The proposed mechanism by which such
superpositions are established includes a number of involved details
that remain to be confirmed or disproven.
28
--> In short, there is much room for both potentially fruitful
speculation and future empirical research to test the ideas. (Yet
another instance where the design-oriented view is anything but a
science-stopper.)
29 --> The
Derek Smith model for cybernetics
offers a further fruitful line of thought for understanding the
mind-brain
interface and also for developing an architecture for artificially
intelligent robotic systems. Take a multiple input-multiple output
control
loop, with many effectors, sensors and feedback loops. A lower order
controller acts to co-ordinate the processes, based on a projected path
and a moment by moment comparison between actual and projected.
Corrective action is taken to adjust performance to desired. A higher
order controller provides a supervisory level, with the creative,
imaginative insight and projections that lay out the path for action for the lower order motion etc. controller.
Thus, the brain here can be viewed as the mind's front-end input-output
controller, with informational interfaces going both ways:
brain-body and mind-brain:
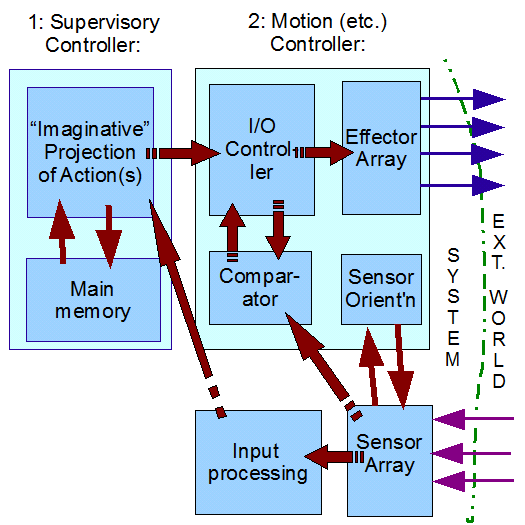
Fig. A8.1: A simplified view of Derek Smith's two-tier controller cybernetic system model,
illustrating how mind and brain could interact
informationally without "locking" mind down to brain wiring. Memory can
be of course [in part?] provided through the brain. (Cf Smith's
detailed discussion here.)
In sum, we have no shortage of more or less plausible
(or at least interesting!) models of how a mind-brain
interface may work, in a context where the concept that our minds are
in effect produced and controlled by forces based on chance and
mechanical necessity cannot credibly ground the reliability of our minds. This
brings up an excerpt from another
page in this site, which helps us further elaborate on and
apply Taylor's point on the implications of the evolutionary
materialist worldview, on what happens so soon as it tries to
completely account for the origin of reliable mind and senses within
the cosmos through the impacts of chance + necessity on matter and
energy configured as biological entities:
. . . [evolutionary]
materialism [a worldview that often likes to wear the mantle of
"science"] . . . argues that the cosmos is the product of chance
interactions of matter and energy, within the constraint of the laws of
nature. Therefore, all
phenomena in the universe, without residue, are determined by the
working of purposeless laws acting on material objects, under the
direct or indirect control of chance.
But human thought, clearly a
phenomenon in the universe, must now fit into this picture.
Thus, what we
subjectively experience as "thoughts" and "conclusions" can only be
understood materialistically as unintended by-products of the natural
forces which cause and control the electro-chemical events going on in
neural networks in our brains. (These forces are
viewed as ultimately physical, but are taken to be partly mediated
through a complex pattern of genetic inheritance ["nature"] and
psycho-social conditioning ["nurture"], within the framework of human
culture [i.e. socio-cultural conditioning and resulting/associated
relativism].)
Therefore, if
materialism is true, the "thoughts" we have and the "conclusions" we
reach, without
residue, are
produced and controlled by forces that are irrelevant to purpose,
truth, or validity. Of course, the conclusions
of such arguments may still happen to be true, by lucky coincidence —
but we have no rational grounds for relying on the “reasoning” that has
led us to feel that we have “proved” them. And, if
our materialist friends then say: “But, we can always apply scientific
tests, through observation, experiment and measurement,” then we must
note that to demonstrate that such tests provide empirical support to
their theories requires the use of the very process of reasoning which
they have discredited!
Thus,
evolutionary
materialism reduces reason itself to the status of illusion.
But, immediately, that includes “Materialism.” For instance,
Marxists commonly deride opponents for their “bourgeois class
conditioning” — but what of the effect of their own class origins?
Freudians frequently dismiss qualms about their loosening of moral
restraints by alluding to the impact of strict potty training on their
“up-tight” critics — but doesn’t this cut both ways? And,
should we not simply ask a Behaviourist whether s/he is simply another
operantly conditioned rat trapped in the cosmic maze?
In
the end, materialism
is based on self-defeating logic . . . .
In
Law, Government, and Public Policy, the same bitter seed has shot up
the idea that "Right" and "Wrong" are simply arbitrary social
conventions. This has often led to the adoption of
hypocritical, inconsistent, futile and self-destructive public
policies.
"Truth is dead," so
Education has become a power struggle; the victors have the right to
propagandise the next generation as they please. Media power games
simply extend this cynical manipulation from the school and the campus
to the street, the office, the factory, the church and the home.
Further,
since family structures and rules of sexual morality are "simply
accidents of history," one is free to force society to redefine family values and principles
of sexual morality to suit one's preferences.
Finally,
life itself is meaningless and valueless, so the weak, sick,
defenceless and undesirable — for whatever reason — can simply be
slaughtered, whether in the womb, in the hospital, or in the death camp.
In
short, ideas sprout roots, shoot up into all aspects of life, and have
consequences in the real world . . .
In sum, we again see a pattern
of self-referential inconsistencies on the origin and credibility of
the mind, and a reduction of morality to "might
makes 'right.' " Neither of these can stand on their own feet. But, to
clench over the nails in the coffin of evolutionary materialism, it is
also worth excerpting a
well expressed point from Will Hawthorne at the blog, Atheism is Dead, on
the [a-]moral implications of evolutionary materialism:
Assume (per impossibile)
that atheistic naturalism [= evolutionary materialism] is true. Assume,
furthermore, that one can't
infer an 'ought' from an 'is' [the 'is' being in this context
physicalist: matter-energy, space- time, chance and mechanical
forces]. (Richard Dawkins and many other atheists
should grant both of these assumptions.) Given our second assumption,
there is no description of anything in the natural world from which we
can infer an 'ought'. And given our first assumption, there is nothing
that exists over and above the natural world; the natural world is all
that there is. It
follows logically that, for any action you care to
pick, there's no description of anything in the natural world from
which we can infer that one ought to refrain from performing that
action. Add a further uncontroversial
assumption: an action is
permissible if and only if it's not the case that one ought to refrain
from performing that action. (This is just the standard inferential
scheme for formal deontic logic.) We've conformed to standard
principles and inference rules of logic and we've started out with
assumptions that atheists have conceded in print. And yet we reach the
absurd conclusion: therefore, for any action you care to pick, it's
permissible to perform that action. If you'd like, you can take this
as
the meat behind the slogan 'if atheism is true, all things are
permitted'. For example if atheism is true, every action
Hitler
performed was permissible. Many atheists don't like this consequence of
their worldview. But they cannot escape it and insist that they are
being logical at the same time.
Now, we all know
that at least
some actions are really not permissible (for example, racist actions).
Since the conclusion of the argument denies this, there must be a
problem somewhere in the argument. Could the argument be invalid? No.
The argument has not violated a single rule of logic and all inferences
were made explicit. Thus we are forced to deny the truth of one of the
assumptions we started out with. That means we either deny atheistic
naturalism or (the more intuitively appealing) principle that one can't
infer 'ought' from 'is'. [Emphases added.]
Of course, if an evolutionary
materialist wishes to now assert instead that s/he can in fact infer
the ought
from the mere PHYSICAL is,
that has to be shown,
not merely assumed. Good
luck.
(On the other hand, if the "is" of our observed contingent cosmos is
premised on the necessary reality of the beginningless and
endless Creator-Sustainer God, then that most relevant "is" of
all -- I AM THAT I AM -- grounds at once the soundness of
morality in the holy, just and loving nature of the very source of
creation. [And the claimed Eutryphro dilemma also at once evaporates: reality
itself is grounded in the nature of him who is inescapably moral so
that which is commanded is grounded inescapably in the root nature
of reality itself, without that reality being independent of God the
Law-giver.])
If one now wishes to bring
forth the hot button (thus, often highly
distracting) issue of the problem of evil, please cf. some
discussions on Plantinga's
Free Will defense, and Koukl's
summary of the argument FROM
evil. This last raises some very interesting and highly
relevant observations for our current purposes:
Evil
is real . . . That's why people object to it.
Therefore,
objective moral standards must exist as well [i.e. as that which evil
offends and violates] . . . . The first thing we observe
about [such] moral rules is
that, though they exist, they are not physical because they don't seem
to have physical properties. We
won't bump into them in the dark. They don't extend into
space. They have no weight. They have no chemical
characteristics. Instead,
they are immaterial
things we discover through the process of thought,
introspection, and reflection without the aid of our five
senses . . . .
We
have, with a high degree of certainty, stumbled upon something real. Yet it's something that
can't be proven empirically or described in terms of natural laws. This teaches us there's
more to the world than just the physical universe.
If non-physical things--like moral rules--truly exist,
then materialism as a world view is false.
There seem to be many other
things that populate the world, things like propositions,
numbers, and the laws of
logic. Values like happiness,
friendship, and faithfulness are there, too, along with meanings and
language. There
may even be persons--souls, angels, and other divine beings.
Our discovery also tells us
some things really exist that science has no access to, even in
principle. Some
things are not governed by natural laws.
Science, therefore, is not the only discipline giving us
true information about the world.
It follows, then, that naturalism as a world view is
also false.
Our
discovery of moral
rules forces us to expand our understanding of the nature of reality
and open our minds to the possibility of a host of new things that
populate the world in the invisible realm.
Going back to the more direct
implications of the Wales example, the detection of functionally
specified, complex information is a profound indicator that there is
more to the world of our experiences than merely chance + necessity
blindly acting on matter and energy. In short, signs of intelligence in
the world around us -- in light of our own experience as (at least
sometimes rational) intelligent agents -- point strongly to the reality
of active mind that transcends the credible reach of chance + necessity
acting on matter + energy. Bringing in the organised complexity of the
observed cosmos and its credible origin at a specific point in the
past, we see good reason to infer to
-- i.e. this is a destination arrived at after
examining and seeking to explain observed evidence, not a
question-begging assumption -- the origin of the cosmos itself at the
hands of Mind beyond the reach of matter. Indeed, it
is fair comment to note that: the
evidence of signs of intelligence strongly speaks to matter being the
product of mind, and not the reverse.
In turn, that means that the
so-called "hard problem of consciousness" is very often ill-conceived,
and typically worse stated. For, as Ned Block observes in an
article for The
Encyclopedia of Cognitive Science:
The
Hard Problem of consciousness is how
to explain a state of consciousness in terms of its neurological basis .
. . . There are many perspectives on the Hard Problem but I will
mention only the four that comport with a naturalistic framework . . .
. Eliminativism . . . . Philosophical Reductionism or
Deflationism . . . . Phenomenal Realism, or Inflationism . . . .
Dualistic Naturalism.
[NB:
In fairness, we must now contrast the better balanced summary here,
at the -- often, for very good reason -- much lambasted Wikipedia: "The term hard problem of consciousness, coined by David Chalmers[1], refers to the "hard problem"
of explaining why we have qualitative phenomenal experiences." (But note how in
the onward linked discussion of experiences, we see the reversion to
naturalism: "Phenomenal consciousness
(P-consciousness) is simply experience; it is moving, coloured forms,
sounds, sensations, emotions and feelings with our bodies and responses
at the center. These experiences, considered independently of any
impact on behavior, are called qualia.
The hard problem of
consciousness was formulated by Chalmers
in 1996, dealing with
the issue of "how to explain a state of phenomenal consciousness in
terms of its neurological basis" (Block 2004).")
]
Let
us therefore note how, in Block's -- clearly influential --
formulation, the materialistic-naturalistic perspective is imposed,
right from the outset, via the presented definition
of the problem (and the underlying assumed definition
of "Science"): explain[ing] a state of
consciousness in terms of its neurological basis. So,
any explanation that does not set out to in effect account for
consciousness on the basis of neurons and their
electrochemistry or the like is excluded from the outset. AKA, begging the question.
Block
then sets out to look at four “naturalistic” alternatives: [1] the view
that “consciousness as understood above simply does not exist,” [2]
allowing that “consciousness exists, but they ‘deflate’ this
commitment—again on philosophical grounds—taking it to amount to less
than meets the eye,” [3] the view that in effect consciousness emerges
from but is not reducible to neurological activity [a comparison is
made to how heat as a concept may be explained as tracing physically to
thermal agitation of molecules, but is conceptually different], [4]
views that “standard materialism is false but that there are
naturalistic alternatives to Cartesian dualism such as pan-psychism."
[This last is explained here.]
But,
what is never seriously on the table is the key issue that the design
inference points to: we know, immemorial, that there are
three major causal factors, chance, necessity, intelligence. Necessity
is associated with mechanical regularities [e.g. how heavy objects fall
and come to rest on a table], so is not associated with highly
contingent outcomes. Contingency [e.g. which face of a die, having
fallen to and settled on a table is uppermost] traces to chance
or agency. When we have functionally specified,
complex information, we have a situation that in observation and on
grounds of inadequacy of required search resources, reliably
traces to intelligence, not chance.
It
is thus -- vast erudition of many discussions by scholars of the
highest calibre notwithstanding -- utterly unsurprising to see that the
whole evolutionary materialistic project to "explain" consciousness grinds to a halt in the face of self
referential incoherence and failure to adequately reckon with the
radical differences between the properties of mind and matter. So, options 1 and 2 fall apart
directly, and 3 and 4 boil down to defiantly flying the materialistic
flag and passing out promissory notes in the teeth of consistent
explanatory failure. But persistent explanatory failure is
not just a matter to be fobbed off with a promissory note or two on
future deliverances of “Science” and/or alternative materialistic
explanations, it is inherent in the materialistic imposed -- historically
and philosophically suspect -- redefinition of what science
is and tries to do. For, the exclusion of intelligence from
explanation when it is inconvenient to the evolutionary materialist
view, ends up in question-begging, and is in violation of
basic facts on the history of science. It is also philosophically
ill-founded, and is self referentially incoherent; as has been shown
above.
That
is -- as the case of Sir Francis Crick vividly illustrates -- such
evolutionary materialist "explanations" cannot even coherently
explain the intellectual works of the researchers themselves. For,
we know that complex, functionally organised information such as
apparent messages, reliably trace to mind, and that mind has
capabilities that do not credibly trace to chance + necessity acting on
matter + energy. In short, we have strong, empirically based reason to
see that once mind is viewed through the characteristics of its traces,
we are dealing with something that strongly points beyond the world of matter +
energy acted on by forces tracing to chance + necessity only.
So,
pardon a bit of an altar call: let us now call on the denizens of the
evolutionary materialist cave of manipulative shadow shows --
“step into the
sunshine, and step out of the shade . . .”
NOTICES: This
briefing note was originally created by GEM of TKI, in March 2006, for
use in briefing Christian leaders and others interested in the ongoing
controversy on Intelligent Design and related concerns. [NB: Because of
abuse of my given name in blog commentary threads, I have deleted my
given name from this page, and invite serious and responsible
interlocutors to use my email contact below to communicate with me.]
This page has been subsequently revised and developed, to date; so far,
to clean up the clarity and flow of the argument, which is admittedly a
difficult one, and add to the substance especially as key references
are discovered one by one such as the recent Shapiro article in Sci Am.
Thanks are due to the ad hoc group of regular commenters at The
Evangelical Outpost Blog over the period since April 2005, for many
useful comments, on both sides of the question. (DISCLAIMER:
While reasonable attempts have been made to provide accurate, fair and
informative materials for use in training, no claim is made for
absolute truth, and corrections
based on factual errors and/or gaps or inconsistencies in reasoning,
etc., or typos, are welcome.) FAIR USE: The
contents of this note are in part intended for use as a support for
learning about responding to the typical intellectual challenges to the
Christian Faith and gospel
that are commonly encountered in the Caribbean, especially in tertiary
education, or on the Internet, or in commentary in the regional and
international media: here, (i) as the evolutionary materialists have
abused science over the past century and more in promotion of
materialistic philosophies -- requiring a serious response
on the merits; presented (ii) at a semi-popular, introductory technical
level suitable to College level students and graduates with some
background in the sciences and mathematics used. In turn, that is
intended to support the ongoing work of reformation of Western and
global cultures through the positive, corrective impacts of the Gospel
- observe here, how Plato grounds his Laws in the implications of the
inference to design, as cited, in
context. In this case, as just noted, the contents
are also intended to provide an accurate briefing on the actual merits
of the case on the inference to design, as a basis for restoring
balance to science, science education and linked public perceptions and
policy. (It is also hoped that the presentation will stimulate
students to dig deeper into the relevant sciences, as well, thus
enriching their educational experience through developing their own
perspectives and building deeper familiarity with key technical points,
techniques and issues.) Permission is therefore granted to link to this
page for fair use under intellectual property law, and for reasonable
fair use citation of the linked content on this
site for church- or parachurch- group related training and/or
for personal or specifically institutional academic use. [But kindly
have mercy on the available bandwidth at a freebie site . . . ask me to
use the page whole or make significant excerpts on your own site as
appropriate . . .] This permission specifically excludes
reproduction, linking or citation for commercial, controversial or
media purposes without the Author's
written permission -- especially where matters relating to
the validity and value of Faith/Religious/Atheological Commitments and
Truth-Claims are being debated or disputed. COPYRIGHT: GEM
2006. All rights are reserved, save as specifically noted just above.
{kind=link}