


|
I am a professional computer engineer, I have known the microprocessor from its start. I have had the curiosity of having a look at the Apollo guidance computer which has been made public. I have read the operator's manual documentation, and it's really the weirdest I have ever seen, so weird that it makes my hair raise on my head when I read it (and I have read many technical documentations). The program of the CM is very weird too; I strongly doubt it piloted anything; it could not even be compiled, that is transformed into machine code to be executed. If I summarize some of the main problems if the Apollo computer, before I discuss them more in detail, I can cite the following points: - The Apollo computer uses a technique of switchable memory which is absurd since it doesn't use the full capability of the addressing system, and leads to wasting time and memory which are very limited in the Apollo computer; and switching executable program memory makes no sense, because it means that the instructions which follow the switching instruction will never be executed. - The Apollo computer doesn't have the mininal basic set of instructions that any processor usually has, and has instead instructions which are weird and impractical to use. - The Apollo computer does useless things which waste processor time (like saving the contents of the instruction following the call to an interrupt moreover saving its address which is the only thing which should be saved). - The Apollo computer provides instructions which compute something so weird in the accumulator (main register of a processor) that it's equivalent to destroying its contents, and thus makes these instructions unusable. - The Apollo computer has instructions which don't require a parameter which should yet be necessary for these instructions to work properly, or conversely which require a parameter which is useless for the way they work. - The Apollo computer has instructions which are unclear; they don't really specify what they do. - The Apollo computer is said to be able to do real time (real time allows several tasks to run simultaneously) and yet it doesn't even have the minimum environment which would be necessary for the real time to work (no stack, and no instruction to manage real time). - The Apollo computer has instructions which uselessly waste processor time (like the "unprogrammed instructions" which count hardware pulses; such instructions have never existed on any processor for the good reason that they make no sense). - Anything which runs on the processor comes from programmed instructions, so the fact that something would steal time from the computer, like they say, is hilarious...unless a programmer would have programmed something and wouldn't have told the others, LOL! - The Apollo computer uses the one's complement system (which makes a distinction between +0 and -0, and is less performant than the two's complement system), although this system was already obsolete in the time of Apollo. The chapter III specifically deals about this subject. |
|
1) Even if in what follows you have some difficulty understanding my technical explanations, there is something everybody should be able to understand: In the documentation there are lines which have been crossed out; does it make sense? On a typed documentation, you never cross text out, you just remove it. 2) Page 3: AGC memory "words" are 15 bits in size plus a parity bit. But the internal registers are 16 bits long; their 16th bit was used as an "overflow". The parity bit is electronically maintained and not visible to the user. Why restrict the words to 15 bits instead of 16 bits which would have been more logical (especially since the internal registers are 16 bits). The memory data words should have been 16 bits long, and the parity bit would have been a 17th bit invisible to the user. And the "overflow" bit has nothing to do in the accumulator and other registers; it should have been a bit in a special register called "Status register" along with other status bits, like the carry bit which is missing. 3) Page 3: the one's complement is used instead of the two's complement system, although this system of representation was already obsolete in the time of Apollo (see Chapter III). 4) Page 5: they say the following things: a) counter/timer registers are incremented by hardware pulses. b) Incrementing a counter/timer takes CPU time. This is contradictory: If incrementing a counter takes CPU time, that means it is incremented by software, and thence it is not incremented by hardware pulses. If it is incremented by hardware pulses, the incrementation has no reason to take CPU time. There's no such thing as an "unprogrammed sequence" even if this unprogrammed sequence bears a name like "PINC" or "MINC". The idea that a repetitive hardware pulse could generate CPU time is heretical. Only executed code can generate CPU time; an external signal can't generate CPU time at the exception of interrupts which provoke the execution of programmed routines. if a hardware signal was generating CPU time to increment a counter, it would be perfectly stupid (and a great waste of CPU time) because an electronic counter can do it just as well and the CPU has more intelligent things to do than to count a hardware signal. When a hardware signal must be counted, an electronic counter is used; not only it is currently the case, but it has always been the case (electronic counters are basic circuits and have existed even before processors did). The processor can read the counter through an I/O channel; of course when he does, it takes CPU cycles, but he doesn't have to do it at each hardware pulse, only when needed. A looping of the counter can also generate an interrupt on the processor, allowing the processor to do a treatment when a programmed count has elapsed. 5) Page 6: They say that the 16th bit of the accumulator (special register of the CPU) is used in association with the 15th bit to indicate overflow. There are other status flags which exist (like the carry for instance) and these status flags are gathered in a special register called status register. The accumulator is never used to indicate overflow; an overflow of the accumulator causes the overflow bit of the status register to be set like for any other register of memory data besides. It has always been the case from early processors. There's no reason to waste a bit of the accumulator to store a status flag in it. 6) Page 8: LRUPT is a register provided for storing the value of the L register during an interrupt service routine. But what's comical is that they say that vectoring to the interrupt routine does not automatically load the register LRUPT with the contents of L; and the restoration of the L register from LRUPT is not automatic either. This is absolutely ridiculous for L could be more conveniently pushed onto a stack to save it, and popped from the stack upon return. If the save to LRUPT and the restoration from LRUPT are not automatic, then this register is useless. 7) Page 9: TIME1 is a counter on 14 bits (why not 16 bits!) which overflows every 163.84 seconds; upon overflow of TIME1, the 14 bits counter TIME2 is automatically incremented. This is ridiculous; why isn't TIME1 16 bits long, and TIME2 too? They could count a value 16 times greater. With a clock of one millisecond, they could count even more than 31 days, and be more precise in the same time. 8) Page 9/10: TIME3 is a counter incremented every 10ms which generates an interrupt upon overflow. TIME4 is also a counter incremented every 10ms which generates an interrupt upon overflow. They say that the increment of TIME3 is dephased of 5 ms relatively to the one of TIME4 so that their interrupt routines cannot occur in the same time, provided that their treatment does not exceed 5 ms. Then they say that TIME5 is also a counter which is incremented every 10ms which generates an interrupt upon overflow; but nothing is provided to synchronize TIME5 either with TIME3 or TIME4. That means that the interrupt routine associated to TIME5 can interrupt either the interrupt routine associated to TIME3, or the one associated to TIME4. Furthermore the addresses of the interrupt routines associated to these counters are separated only by 10 octal, and 10 octal, that leaves only 8 memory bytes to program the interrupt routine; and this interrupt routine must mandatorily end with an instruction allowing the return to the interrupted program (which makes the interrupt routine itself still shorter). What do you want to program in less than 8 bytes (that makes only four instructions, since each instruction uses two bytes)? This is ridiculous! Of course there can be a jump at the interrupt location to another part of the memory where there is more room to program a service routine; but, to program the jump, only two bytes are needed, and there are 8 unused bytes; that means that the intervals between the locations of the interrupt routines could have been reduced to two bytes. So, to summarize, the interval between the interrupt routines is either two short or too long. 9) Page 10: TIME6 is a counter incremented every 1/1600 of second by an unprogrammed sequence. This means absolutely nothing; a sequence is always programmed, otherwise it is not a sequence. After having loaded TIME6 for the count corresponding to the desired delay, the user enables the counter by setting a bit in an I/O register. Upon overflow of TIME6, an interrupt routine is called; they say that the enable bit of the I/O register is automatically reset, but in fact it couldn't be automatically reset; it would be up to the user to reset the enabling bit in the I/O register! 10) Page 11: PIPAX is a register which stands for "Pulsed integrating pendulous accelerator". This is absolutely ridiculous: Registers of a CPU just represent data memory, they don't bear such dedicated names. 11) Page 13: The way the memory is mapped makes no sense. The banks of memory can be addressed without the need of making bank switching. Bank switching consumes both space and time in a completely unnecessary way. It may make a sense for Data, but not program code. 12) Page 15: They say that the processing of an interrupt routine can be deferred if an interrupt routine is already in progress and not yet terminated (by a RESUME instruction). In that case, why having dephased the increment of the timer TIMER3 relatively to the increment of the timer TIME4 in order to avoid their interrupt to occur in the same time, since the one which would occur second would wait for the first one to end before processing? 13) Page 15: They say that the step 2 of the processing of an interrupt routine is to save the instruction appearing at the memory location pointed to by the program counter into the BRUPT register. This makes absolutely no sense! It's the address of the instruction which is saved, but the instruction itself would never be saved; no CPU has ever done that! They don't finish the description of the processing of the interrupt, that is explain that the RESUME instruction reloads the program counter from the ZRUPT register. 14) Page 16: They say that an instruction is represented the following way: CCC AAA AAA AAA AAA That is an instruction code on 3 bits only, and a memory address on 12 bits. Normally the instruction code is not mixed with the address, but separated from it. The instruction code would typically be provided on a byte, which would allow to provide a set of up 256 instructions. The address would not systematically be provided after the instruction; some instructions only act on internal registers of the CPU and don't require a memory address to be specified; the memory address would only be provided when needed by the instruction. The address would be provided on 16 bits in the following word, its length would have no reason to be provided on only 12 bits; that would extend the capacity of memory addressing by a factor 16, and would eliminate the need of making bank switching which consumes both CPU time and space, and is not advisable in a system which is already slow and limited in memory space. Now in the Apollo AGC, the instruction code is in fact mixed with the address, because not all addresses are allowed for the memory address. The addresses starting from zero cannot be used (they are used as registers of the CPU) and are used to complete the instruction code. For example, if the instruction is "01000" octal, the adress is "1000" and is a valid address, in that case the instruction code "0" indicates that it is a TC instruction calling the subroutine located at address 1000. But, if the instruction is "00001", the instruction code is also "0", but the address "0001" indicates that the instruction is in fact "XLQ" instead of TC. That means that the knowledge of the instruction code is not enough to know what instruction to execute, the processor still has to analyze the address before it knows what instruction it has to execute; this is less efficient that if the the processor could directly determine what instruction to execute from the instruction code. 15) In All CPUs, including the very old ones, there is a set of instructions especially dedicated to make conditional jumps. These instructions test status bits set by previous operations: It can be addition, subtraction, but it also can be simple compare. These instructions include conditional jumps such as: Jump if equal, jump if greater, jump if greater or equal, jump if lower, jump if lower or equal, jump if carry, jump if not carry... On this CPU, there are only two conditional instructions: BZF and CCS. BZF only tests if the acculutator is zero, and it's totally insufficient, there also should be an instruction to test the sign. Oh there is the CCS instruction which can test the sign of a memory data.. the problem is that this instruction destroys the contents of the accumulator by computing something from the memory data in a determined way that the user can't choose; and it only performs skips according to the result of the test, which means that the user has to add jumps behind CCS to execute the desired sequence according to the result of the test. This is made to be as unpractical as possible, in a totally irrational way; no serious conceptor of CPU would make instructions so unpractical to use. It's not that this CPU works differently from other CPUs, it's that it works in an irrational way. 16) Page 24: The "DTCB" (Double transfer control switching both banks) instruction is said to perform a jump and switch both fixed and erasable banks. This is hilarious: This instruction is so inconvenient to use that it's difficult to imagine in what context it could be used. Switching just one memory bank is already extremely inconvenient to use (not to say impossible), but switching both banks in the same time still makes less sense! 17) The "DV" instruction divides the pair of CPU registers A and L by a data of which the memory address is given on 12 bits. They say that this instruction can work according to two different modes (divide the pair A&L by a single precision value or by a "double length 1s complement integer" pointed to by the memory location). The problem is that there is absolutely nothing which tells the CPU what mode to use, since there is just the instruction and the memory location and no additional information. The CPU must be extralucid to determine what mode to use! They give some examples of how the division works in a table. Among these examples, they say that, when +0.0 is in the pair A,L, and +0.0 is in the register K, then the instruction DV computes a quotient of "0.999389648" in the register A. So, dividing zero by zero would give something different from zero? It's original! 18) Page 28: The way the "INDEX" instruction works is hilarious. It is said to change the behavior of the instruction which follows; they give the following example: INDEX A TC JMPTAB ... TCF LOC-2 TCF LOC-1 JMPTAB TCF LOC0 TCF LOC1 TCF LOC2 TCF LOC3 The TC instruction normally calls a subroutine, but the fact that it's preceded with the INDEX instruction makes that it becomes a conditional JUMP according to the contents of the accumulator. They say that if the accumulator contains 0, it jumps to the label JMPTAB which performs a jump to LOC0, if the accumulator contains 1, it jumps to the next instruction after JMPTAB which performs a jump to LOC1, if the accumulator contains 2, it jumps to the second instruction after JMPTAB which performs a jump to LOC2... But where it becomes hilarious is that if the accumulator contains -1, it jumps to the instruction before JMPTAB, and if it contains -2, it jumps to the instruction still before. The instruction before JMPTAB performs a jump to the instruction one word before the label LOC, and the instruction before the latter performs a jump to the instruction two words before the label LOC. But if there is a jump to the instruction two words before the label LOC, the instruction one word before the label LOC will also be executed...unless there is a jump to another label at the instruction two words before the label LOC, but in that case why not directly use this label in the instruction "TCF LOC-2". 19) Page 32: the NOOP instruction is hilarious too; not because it makes no sense to have an instruction which makes nothing, for this instruction effectively exists in normals CPUs, and is used to provide short delays. What's hilarious is that this instruction is said to take two cycles if executed in erasable memory and one cycle in fixed memory. In normal CPUs, this instruction always takes one cycle, wherever it is executed in memory. And the erasable memory is only purposed to contain temporaty data, not executable code. 20) Page 33: the "RAND" instruction is said to logically bitwise ANDs the contents of an I/O channel into the accumulator. Oh really: None of the CPUs which exist and existed in the world ever provided this possibility. There is only an instruction to read an I/O channel (when it is readable) or to write it (when it is writable). This is a purely imaginary instruction. 21) Page 34: the "RESUME" instruction allows to terminate an interrupt routine and to go back to the instruction which was about to be processed when the interrupt occurred. They say that, when the interrupt occurs, the instruction pointed to by the program counter is automatically saved into the BRUPT register of the CPU. Upon return, the instruction saved in BRUPT is automatically executed; but why save it into BRUPT, since it will be executed anyway upon return of the interrupt routine if the BRUPT register is not modified by the interrupt routine! And, if the interrupt routine modifies BRUPT to have another instruction executed upon return, why not directly execute it, which would be faster, since, if the interrupt routine copies the instruction into BRUPT, the time of the copy of the instruction will be added to the execution time of the instruction, whereas there will just be the execution time if the instruction is directly executed. This is totally illogical and makes no sense at all! 22) Page 35: the "RETURN" instruction allows to return from a subroutine by loading the program counter (Z register) with the Q register which normally contains the return address; the TC instruction which allows to call a subroutine automatically saves the return address into the Q register. Since there is a unique register to save the return address, a subroutine cannot call another one. In a normal CPU, the return addresses are saved onto a stack (a part of memory which specially dedicated to save/recall memory data, return addresses..) which allows to call a subroutine from another subroutine. In this CPU, calling a subroutine (by the TC instruction) from another subroutine is not possible since the return address is saved into a unique register; calling a subroutine within a subroutine would result in the return address of the first subroutine to be overwritten by the return address of the second subroutine; it would become impossible to return from the first subroutine. 23) Page 39: the "TS" instruction (transfer to storage) is hilarious. First it transfers the contents of the accumulator to the memory location indicated as operand. Till then, nothing abnormal. But what's really weird is what is made with the accumulator: If the accumulator contains an overflow, and only in this case, it is loaded with +1 or -1 (what does that means?), and the next instruction is skipped! This instruction has a very unpractical use. There should be an instruction just to perform the storage, and another one to perform that very special function on the accumulator, but having an instruction which does both in the same time makes no sense; it's almost impossible to use. 24) Page 43: From page 43, they describe what they call "Pseudo-operations". If an instruction is not an instruction existing in the set of instructions of the CPU, then it can only be a "macro-instruction", that is a set of programmed CPU instructions which is associated to this macro-instruction. They describe the pseudo-operation 1DNADR as transmitting the two words pointed to by the provided memory location...but transmitting to what? There is always a destination in a transmission, saying it's just transmitted means nothing, if the destination of the transmission and the way it is transmitted are not specified! 25) Page 45: the "BANK" pseudo-operation is said to reposition the yaYUL's internal location counter to the first unused location of specified fixed memory bank.  The consequence of changing the program memory bank is that the program counter is set to another program memory bank, at an address which is said to be "the first unused one", and that it will not execute sequentially the instruction following the Bank instruction. It means that, if, in another memory bank, there is an instruction "Bank" which specifies the number of the current bank, it should start executing from the instruction following the Bank instruction.  I show here an animation showing how two banks could alternately go from one to another one, but it could involve more tasks: A bank 1 could change to a bank 2, which would change to a bank 3, which would change to a bank 4...and, at one moment, a bank would switch again to bank 1. But, when a bank would switch to another bank, the processor would have to know the address of the "first unused instruction" of this bank, which would have been saved when this bank itself switched to another bank and set to the address of the instruction following the bank instruction. It means that, in the main registers area, there should be an area to save the addresses of the "first unused instructions" of the banks, for each bank. But, there is no such area described in the documentation. 26) They describe the "pseudo-operation" STCALL this way: STCALL X Y and say X is in unswitched erasable bank. But they don't describe what this operation does! 27) Page 48: They say that the "SETLOC" operation places the next instruction or pseudo-op at the specified address. But what does that mean? If only one instruction is placed at this address, executing from this address will only execute this instruction. 28) Page 50. the instruction "STORE" stores data into the a specified address. 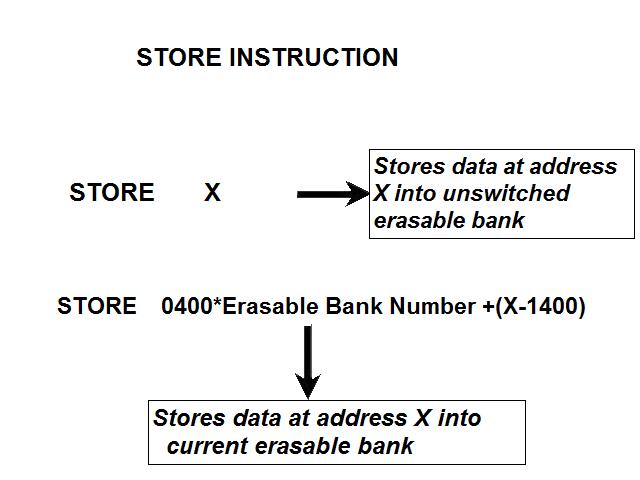 It saves data in two different ways: 1) Either into the unswitched erasable bank. 2) Or into the current erasable bank And it cannot be saved into any other erasable bank. In case that it must be saved into the current erasable bank, the instruction must be written under the following form: STORE 0400* Erasable Bank Number + (X-1400) X being the address in which the data is to be saved in the bank. But this is where it becomes absurd: The Erasable Bank Number can only and exclusively be the one of the current bank number, for the data can be saved in no other switchable erasable bank. Then, what is the use of specifying it, if it can only be the one of the current erasable bank?  Now, suppose that the current erasable bank is the bank 2, and that the user specifies the bank 3 in the second form.  Will the instruction do nothing, or ignore the bank number and save the data into bank 2? Probably the second case. 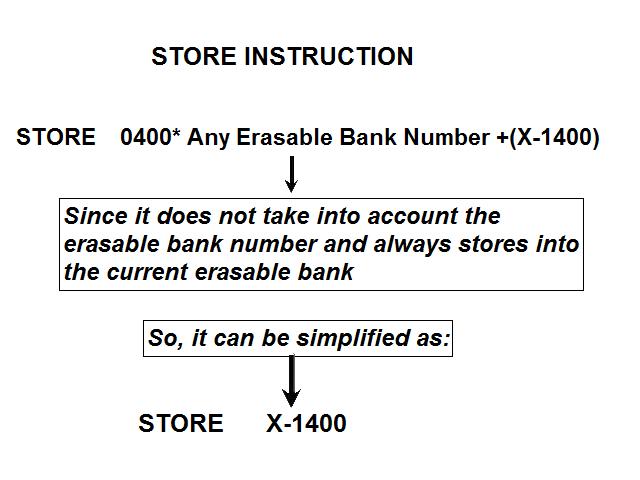 But, in this case, why not change the second form of the instruction not to have to specify the number of current bank, and just write it: STORE X-1400 But making it simple was out of question for the engineers who had decided to push absurdity as far as possible! 29) Why memory bank switching makes no sense. The AGC has reduced memory addressing to 12 bits, whereas 16 bits should normally used for memory addressing, it has no reason to be limited to 12 bits. It would allow to directly address 16 times more memory, and would eliminate the need of making memory bank switching. Memory bank switching on data already makes no sense. Imagine that you have a data in bank 1 that you want to add to a data in bank 2 and want to put the result into bank 3. You have to switch to bank 1, take the first data, then switch to bank 2 add the second data, and finally switch to bank 3 in order to write the result into the destination of the operation. That means that you have had to program the bank switching instructions, that is they take memory, when they are executed they take execution time; it's a waste of both memory space and execution time. This waste would be avoided if there was no memory bank switching. Memory bank switching still makes less sense on programming code. When you make a fixed memory bank switching, no value is initially provided for the program counter. That means that the execution normally starts at the beginning of the new bank. Of course, it would be possible to put a value in a data memory that the new bank could test to know where to jump to, but it's rather complicated to use. When you call a subroutine or branch to another sequence, it must be in the same memory bank, it can't be in another bank; this is not practical at all; there would be no such problem if there was no bank switching, a single program file could be used for the whole program. And if you put a program memory bank switching instruction in your code, that means that the code which follows this instruction will not be executed since the processor has jumped to another bank; if the instruction which follows has not label, it will be unreachable. |
|
Link to the CM program General considerations on the CM program. a) Even if you have some difficulties understanding my technical explanations, do you really think that the comments (the text after the character '#') fit with the instructions? b) The labels are the strings of characters which begin at the first character of a line; they are used to identify a location in the program, and allow a direct branch to that location. The labels must only contain letters and numeric characters, and some other characters (such as underscore, for example). They cannot contains blanks, punctuation characters (.,;), arithmetical characters (+-*/). The labels must also be unique; there cannot be two labels with the same name in the program (otherwise when a branch is made to that label, the CPU could not know which of the duplicate labels to go to). A program containing a duplicate label cannot be compiled, that is transformed into machine code, and therefore cannot be executed. c) In the instructions requiring a memory address, this memory address can only specified as a symbol (eventually with a valued added or subtracted) or eventually an octal address (generally it's a hexadecimal address, but in this CPU octal addressing seems to be privileged). In no case this memory address can contain a multiplication or a division (such as "A/B") or be a numeric floating value (such as "0.1234"). d) Several instructions are not referenced in the programmer's manual, neither as CPU instructions, nor as pseudo-operations; therefore it's difficult to know what they perform. e) There are several examples of useless instructions, such as saving several times a same data which is never modified (not even initialized) and never used; or a memory dara which is written with a value, and rewritten with another value without the previous value having been used. f) the TC instruction allows to call a subroutine; in the documentation it is said that a suboutine called by TC cannot call another subroutine inside its treatment for the good reason that the return address is saved into a unique register and not onto a stack. I give thereafter some examples of incongruities in the LCM program. 1) The instruction "BANK 35" switches to fixed memory bank 35; this bank contains another program which means that the instructions which follow are not going to be executed since they are not in the same bank! And the instruction which is behind this BANK instruction has no label, which means that it can't be branched at; thence it has no chance to be ever executed! 2) The instruction "SETLOC BODYATT" is used to place the next instruction at the address "BODYATT". But "BODYATT" is defined nowhere, only used in this instruction. 3) The instruction "BANK" allows to load the program counter with the first "unused" location of the current fixed bank. That means we are going to execute unprogrammed instructions...very insteresting! 4) CM/POSE is not a valid label. 5) In the program there is this sequence: SETPD VLOAD 0 VN The "VLOAD" instruction is an instruction of the interpreter, but it must be followed with the address of a vector, and it is followed instead with a numerical value (0). 6) The instruction "STORE -VREL" is an instruction of the interpreter allowing to "store" a vector into the specified memory location. But the address "-VREL" is not a valid address! 7) The instruction "STORE UXA/2" stores something (not specified) into the specified memory location. The second member can only be a symbolic name of a memory address, with eventually a value added or subtracted, but cannot contain a division. 8) At different points of the program we find the sequence "PUSH CDULOGIC". Apparently this sequence pushes a variable CDULOGIC onto a stack; this is weird for the following reasons: - CDULOGIC is not initialized. - CDULOGIC is never modified. - CDULOGIC is repetitively pushed without having be modified, and is never popped, which means that its contents is never used. - And anyway the documentation says that the CPU uses no stack! 9) The instruction "BZF DOGAMDOT" jumps to the label DOGAMDOT" if the accumulator is zero; if not, it continues in sequence; the instruction "TC NOGAMDOT" calls the subroutine "NOGAMDOT". 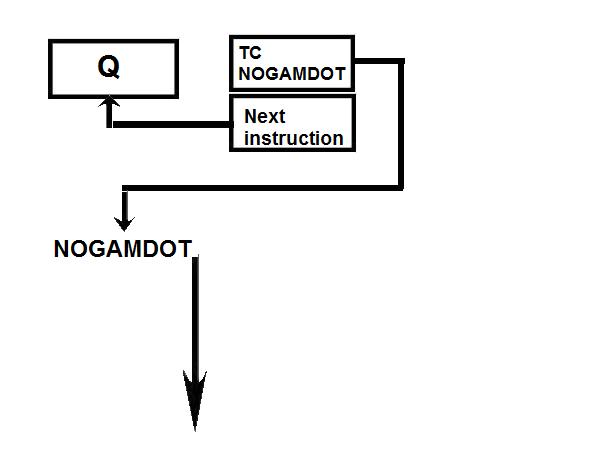 The instruction "TC NOGAMDOT" saves the address of the instruction following the call to NOGAMDOT into the Q register, and branches to the procedure NOGAMDOT, so that the program continues from this label.  Normally, as the instruction TC is supposed to call a subroutine, the procedure NOGAMDOT should end with an instruction "TC Q" which puts into the program counter the return address which has been saved into the register Q, and which is the address of the instruction following the call to NOGAMDOT; the processing then resumes from the instruction following the call to NOGAMDOT.  But the procedure NOGAMDOT makes itself a call to a subroutine "CORANGOV"; the call to CORANGOV is made in a similar way as the call to NOGAMDOT: The address of the instruction following the call to CORANGOV is saved into the Q register and the program counter branches to the subroutine CORANGOV which is then executed. 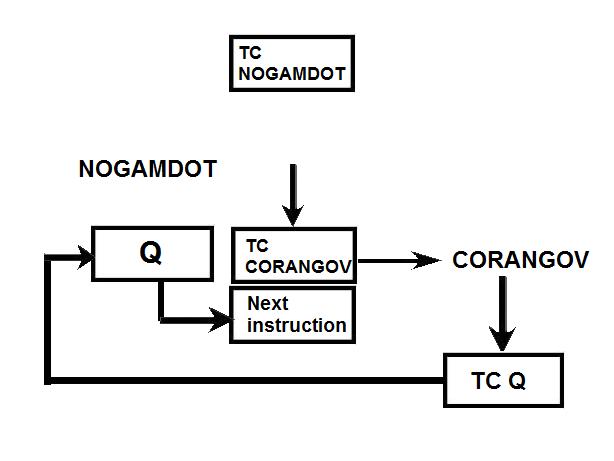 When the subroutine CORANGOV ends, it executes the instruction "TC Q" which puts into the program counter the return address which has been saved into the register Q, which is the address of the instruction following the call to CORANGOV, and the execution resumes from this instruction. 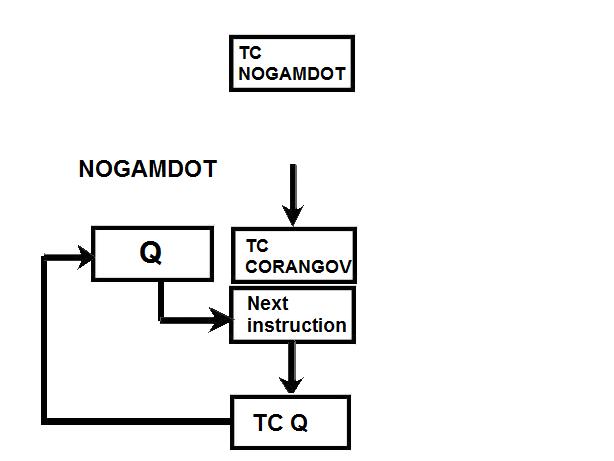 Now, if the procedure NOGAMDOT tries to return to its caller with an instruction "TC Q" after having called the subroutine CORANGOV, it will not return to the instruction following the call to NOGAMDOT, but to the instruction which follows the call to CORANGOV instead, for the address of the instruction following the call to NOGAMDOT has been overwritten with the address of the instruction following the call of CORANGOV when CORANGOV was called by NOGAMDOT; indeed the Q register can only memorize a unique return address, which means that nested calls are not allowed. It means that NOGAMDOT cannot return to its caller if itself calls a subroutine (or several subroutines). 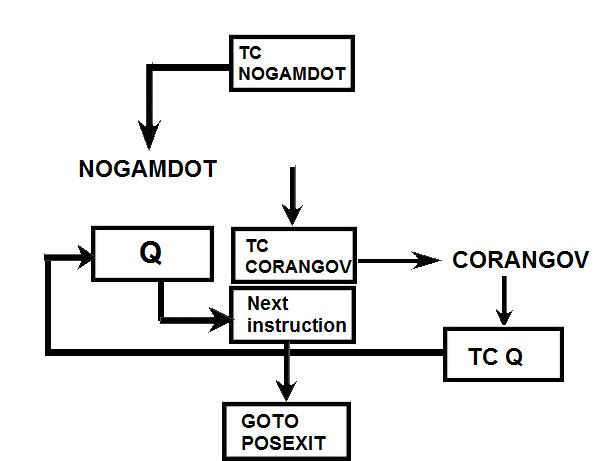 Anyway, it is not a problem, for NOGAMDOT does not return to its caller; it does not end with a "TC Q" instruction, but with a "GOTO POSEXIT" instruction instead. It it had come back with a "TC Q" instruction, it would have been an error. 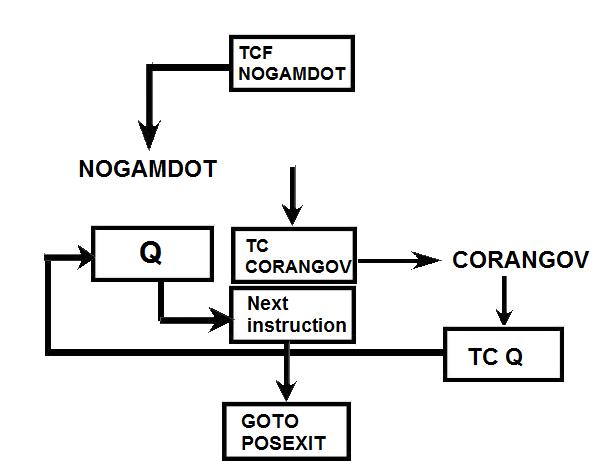 But, since NOGAMDOT does not return to its caller, it was not necessary to call it with a TC instruction, but it could have been called with a "TCF" instruction instead, which works like a "TC" instruction (i.e. allows to branch to NOGAMDOT) with the difference that it does not save the address of the instruction following the call to NOGAMDOT into the register Q. So, you are going to say: If it works with both solutions, where is the problem?  The problem is that the instruction "TC" makes an additional work relatively to the instruction "TCF" which is useless, since the return address it saves into the register Q cannot be used, as it it is further overwritten by the return address of another call. If the branch to NOGAMDOT is made with the instruction "TCF", the program will execute slightly faster than if the branch is made with the instruction "TC", for it does not make an useless operation. A program must not only work, it also must work as fast as possible, especially when this program works in a real-time environment, and on a computer as slow as the AGC was! Of course, I don't think that the engineer who wrote this program was incompetent, I think he did it on purpose to give a hint, for he knew that this program would never make a lunar module land on the moon. 10) the subroutine CORANGOV is strange: CORANGOV TS L TC Q INDEX A CA LIMITS ADS L TC Q 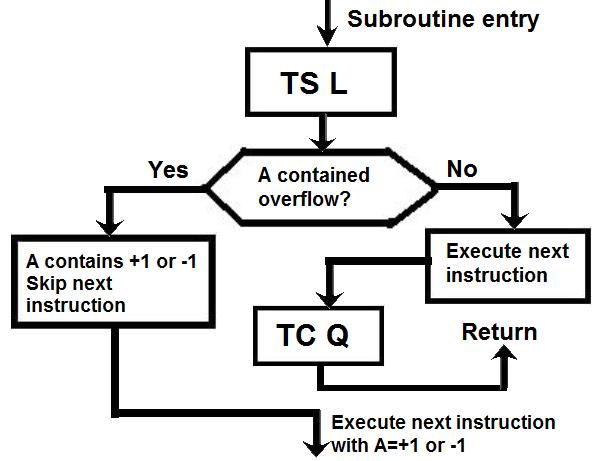 In this subroutine, the first instruction "TS L", according to the documentation, loads the accumulator either with +1 or -1 if the overflow is set (respectively positively or negatively), and skips the next instruction, otherwise the next instruction is executed. The next instruction, "TC Q", is therefore executed in all cases, except if the accumulator contained an overflow when executing the first instruction; this instruction "TC Q" makes that the subroutine immediately returns, and therefore the next instructions of the subroutine will not be executed. It means that the next instructions of the subroutine will be executed only if the accumulator contained an overflow when executing the first instruction, and in that case it will contain either +1 or -1, since the first instruction puts one of these values into it if the overflow is currently set. 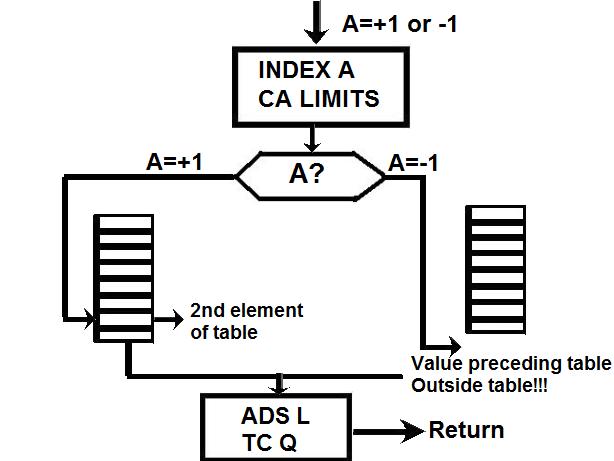 Then there are two consecutive instructions "INDEX A" and "CA LIMITS"; the instruction "CA LIMITS" would normally mean that the contents of the variable LIMITS is loaded into the accumulator; but the previous instruction, "INDEX A", modifies its behavior, and makes that the address of the variable LIMITS is added to the contents of the accumulator to form the address of the variable of which the contents is to be put into the accumulator.  It means that LIMITS is in fact to be considered an index table indexed by the current contents of the accumulator; but, when you index a table, the value you give to index this table must be positive and not exceed the number of elements of this table. Here, the accumulator can only have two values, +1, or -1; it means that this couple of instructions would exclusively retrieve either the second element of the table, or the value which precedes this table and is not included in this table!. So, either a unique element of the table LIMITS is used, or an element outside this table. Does this make sense? Furthermore, before returning from the subroutine, an instruction "ADS L" is executed; this instruction adds the accumulator to the register L, and puts the result both into the accumulator and the register L, according to the documentation. But the documentation says this about this instruction: "The accumulator is neither overflow-corrected prior to the addition nor after it. ". So, this subroutine was supposed to correct the overflow of the accumulator, but its last instruction destroys the effect of the correction.  I have found a similar subroutine in the program "CM_ENTRY_DIGITAL_AUTOPILOT" of Comanche055. The only difference is that the instruction "CA" is replaced with the instruction "CAF". In fact CAF works the same as CA, with the difference that it displays an errror message is the table LIMITS is neither in fixed memory nor in erasable memory. But why would the program "CM_ENTRY_DIGITAL_AUTOPILOT" need to test the accessibility of the table LIMITS and not the program "CM_BODY_ATTITUDE"? And in neither of these two programs is the table LIMITS defined. 11) The subroutine "NOGAMDOT" called by "TC NOGAMDOT" transfers the contents of the accumulator to the data memory "GAMDOT" by the instruction "TS GAMDOT". Upon return of this subroutine (if there is a return), the execution continues in sequence and meets the instruction "TS GAMDOT" again. Between these two instructions, GAMDOT has not been used (and is never used); so what is the use of copying the accumulator into GAMDOT, if it is to copy the accumulator into it again without having used the previous copy? 12) To end with this program, the conclusion is that the program contains 302 lines generating 7027 bytes. That makes an average of 23 bytes per line. For an assembler program, it seems absolutely delirious. |
 I have had an overview of the guidance equations in the NASA documentation. If you look at them from far, with an uninformed eye, they may seem impressive and very serious. But, when you look at them with more scrutiny, you start to see plenty of incoherences and absurdities. I will not show all the absurdities I have seen in this documentation, I will just give some examples.  This function "maximum of", from an excerpt of flow diagram of the NASA documentation, is supposed to give the maximum of two values; these values must be of course unique and precise; but one of the two values given as parameters does not represent a single value, but a variation between two values; so we may wonder how the maximum will be obtained! This formula is obviously completely incoherent. 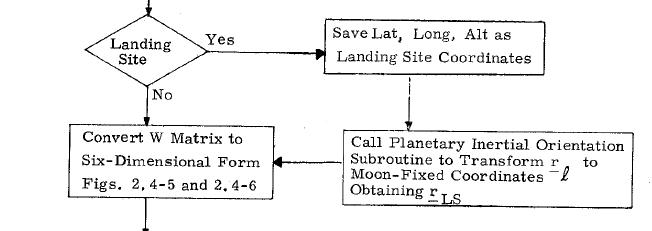 In this excerpt of flow diagram of the NASA documentation, a subroutine to transform relative coordinates of the LM to moon-fixed coordinates is called, but it is only called if the LM is on the landing site; this is completely absurd, for the LM needs the moon-fixed coordinates permanently, even before it is on the landing site...otherwise it will have some difficulty to land on the landing site!  In this excerpt of flow diagram, a test is made if a "Lambert solution" is currently available; if not, a treatment is made which does not use it; but, if this solution exists, a test is made to see if a variable "SF" is currently equal to 1, in which case the Lambert solution is not used; then why not allow to pass the previous test if this variable is equal to 1 since the Lambert solution is not used in that case?  It is obvious that, if the guidance had meant to be serious, each flow diagram would have been written in order to do its job in the smallest time as possible. This is especially important, since the computer is not powerful, and had big problems to finish its tasks in time (to the point of getting stuck sometimes for that reason and needing a restart!). So we might have expected that their flow diagrams would be as optimized as possible.  In this example, a set of values has to be computed for values of a variable P ranging from 20 to 0; the computation of the values uses two auxiliary variables i and j associated with the variable P. The variable j starts from the value 29, and decreases from this value, but it skips the values from 26 to 3, which means that it directly goes from the value 27 to the value 2; the variable i starts from the current value of j, and also decreases and skips the values from 26 to 3. 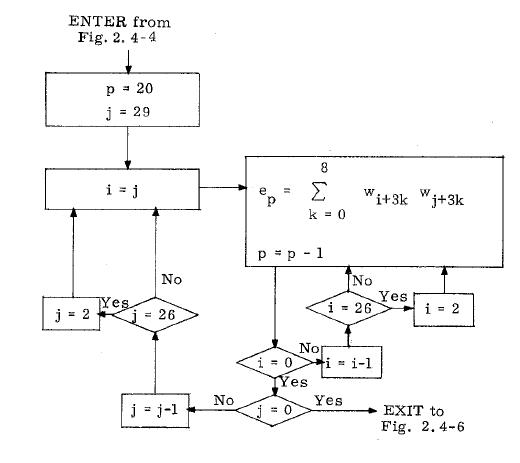 This is the flow diagram they give for the computation of the table of values. Do I mean that this flow diagram does not work? Oh no, it perfectly works. So, where is the problem? The problem is as follows: When the variable i has the value 27, the following operations are performed on it: - The value 27 of i is compared with 0; is it null? No it is not, so it goes on the "No" branch of the test. - Then the value 27 of i is decremented (that is: it is subtracted with 1), which gives 26 as a result. - The new value of i is then compared with 26; is it equal to 26? Yes, it is currently equal to 26. - so the test exits on the "yes" branch, and the value 2 is put into the variable i. So, when the variable i exits from the computation with the value 27, four operations are performed on this variable. And, for the variable j, it's exactly the same thing: four operations are perfomed on the variable j when it currently has the value 27. 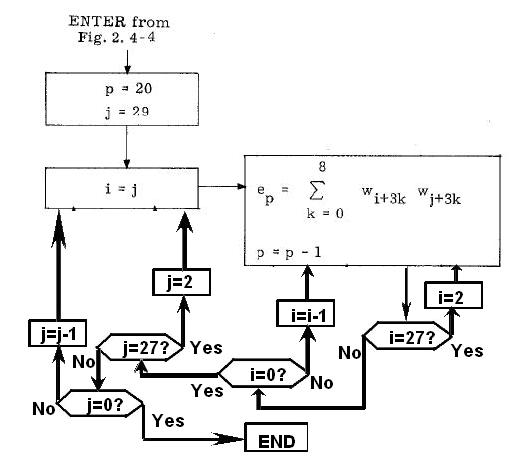 No, let's see this graph I have corrected. It also works, and the variable i and j will be processed exactly in the same order as in the previous flow diagram. When i and j are different from 27, the same number of operations are performed on the variables. It's when i or j has the value 27, that the difference appears: when the variable i exits from the computation with the value 27, it is directly compared with 27, and, if it has this value, the value 2 is directly put into it, and the computation is called again for the next set of values; so that makes only two operations for the value 27 instead of four in the previous flow diagram, whether for the variable i or j. That means that this new flow diagram will work more efficiently, will take less operations, and therefore will work faster than the previous flow diagram.  Now you are going to say: Both solutions work, and the difference for the processing time is not very important. It may not be very important, but the point is that IT DOES EXIST. If the guidance permanenly uses unoptimized processes, it is obvious that the guidance task is going to lose time on the expectation.  If the AGC had been a very powerful computer, and that plenty of time had remained after it had completed its task, it would not have been a problem...But we know that the AGC had big problems of performance, and the famous alarm 1202 was resulting from the fact that it was not succeeding in finishing the guidance task in time sometimes.  A competent computer programmer always writes his programs so that they are as performant and optimized as possible, even if they run on a powerful computer which does not have problems of processing time like the AGC. So there are only two possible solutions: - Either they have given the tasks of writing the guidance programs to incompetent engineers, which would be extremely surprising for a project as big and important as the Apollo one. - Or, the engineers were competent, but they were not intending to write serious programs that they knew they would never be used to make a lunar module land on the moon. For me, it makes no doubt that it is the second hypothesis which is the good one.  A document of the NASA library, "Critique of IBM Apollo study report" makes a comparison between the perfomances of the IBM computer of the Saturn rocket and the AGC  The IBM computer which was embarked in the Saturn rocket seems to be a serious computer, unlike the AGC. And, unlike the AGC, it was rationally using the two's complement system instead of the outdated and less performant one's complement system of the AGC, which shows that the AGC could perfectly have used it. I have found nothing to criticize to it, it was perfectly fit for its purpose. The reason it could not be used in the lunar module was that it was not compact enough for it; for the Saturn rocket, it is OK, because the rocket is big and can afford the volume and weight of this computer, but the lunar module was needing something smaller. The IBM computer had three modules of data, with each 4096 words of 28 bits, of which two parity bits and a sign bit  The AGC had 2048 words of erasable memory,and 36864 word of fixed memory. The words of the AGC had 16 bits, but one of these bits was the parity bit which was not usable, and therefore the words only had 15 usable bits. In the document they make various comparisons between the AGC and the IBM computer, and outline the flaws of the IBM computer. I am just going to show a selection of these senseless comparisons.  In this comparison, they show on the left the addition of two vectors of three double words of 28 bits in the AGC, using the interpreter, which requires only 60 bits of storage, and they show on the right the similar addition of three simple words of 25 bits on the IBM, which requires 117 bits of storage, so almost the double of storage; the conclusion of the report is that the AGC is more performant to make that addition than the IBM.. But the sequence of the AGC is not correct, the interpreter is incorrectly used. The instructions of the interpreter were only summarily described in the general documentation of the language of the AGC and did not allow me to check if the sequence was correct. But I have found a document in the library of the NASA, written by Charles Muntz, and which was precisely describing how the interpreter was working, and Bingo!  The interpreter instruction VAD allows to add two double precision vectors, but it adds a vector B which is specified behind this instruction to a vector which is already in a special memory area, called MPAC, and which is previously loaded by another instruction of the interpreter, called "VLOAD"; what is incorrect in the sequence is that the first vector to add is specified after the instruction VAD, when it should be specified before as a parameter of another instruction of the interpreter (VLOAD). I show on the right the correct sequence which would make the additions of the two double precision vectors A and B, and would put the result into the double precision vector C.  So, now we have on the left the correct sequence which would work to add two double precision vectors A and B, and put the result into the double precision vector C. With this sequence, unlike the one they showed, the comparison would make sense. I didn't care to determine the storage for this new correct sequence, but it is probably close to the storage of the previous one. However, even with this correct sequence, the comparison is still unfit.  The interpreted instructions are not directly executable by the processor, they have to be translated by the interpreter into assembly instructions that the processor can execute. And the processor of the AGC does not have instructions allowing to make double precision additions like the IBM computer; in fact it has instructions allowing to make operations on double words, but not allowing to make these additions as directly as for the the IBM computer; this will be made more clear on the last example I show. So, the comparison does not make much sense, for it compares interpreted instructions of the AGC which cannot be directly executed by the processor and need the interpreter to be translated with the instructions of the IBM computer which are directly executable by the processor.  Second example: Then they show a sequence of instructions represented on the left of this double view; the AGC programmers complain that the IBM programmers did not make any effort to optimize this sequence and ask them to optimize it; after optimization, this sequence becomes the one represented on the right of the double view. The following remarks can be made concerning this optimization:  1) The unoptimized sequence contains three times the instruction "CLA *+2" that we don't find in the optimized sequence. The instruction "CLA" exists in the instruction set of the IBM computer and allows to load a data into the accumulator (main register of the computer). It might seem a reasonable instruction if there was not the right member of this instruction; the right member designates the address of a data which is to be loaded into the accumulator; the problem is that this address is specified as "*+2"; the symbol '*' is used in the computer to represent the current value of the program counter (some computers also use '$'), that is the address of the currently executed instruction; "*+2" represents the current value of the program counter plus two words; as the instruction CLA occupies two words in memory, this address represent in fact the address of the instruction following the instruction "CLA"; that means that this instruction would load into the accumulator the contents of the instruction which follows it...But an instruction is meant to be executed and not to be handled as a data, it represents nothing as a data. This is to explain that the instruction "CLA *+2" is completely absurd, and of course the programmer who used it knew it; so no wonder that it has been eliminated in the optimized sequence.  2) The unoptimized sequence contains three times the instruction "HOPCON *+1" that we don't find in the optimized sequence. The instruction looks like the instruction "HOP" which is also used in the sequence; the instruction "HOP" exists in the instruction set of the computer and is mostly used to make calls to subroutines; according to the IBM documentation, a subroutine called with an HOP instruction returns to the caller with a HOP constant, which is symbolized by the instruction "HOPCON" used without right member (since it is the saved program counter which is used). So, first this instruction is used with a right member it should not have, but furthermore the address specified in the right member corresponds with the address of the next instruction, which makes this instruction still more absurd. So the instruction "HOPCON *+1" is also absurd, and intended as such; no surprise that we don't find it in the optimized sequence.  3) Finally we still have three instructions which are not either in the optimized sequence. In fact these instructions save into variables values which already were in other variables, for the program does not modify them after having loaded them into the accumulator before saving them into the new variables. A given value only needs to be saved in a unique variable, it does not need to be saved into two different variables which will contain the same thing. So finally, the IBM programmer put into this sequence instructions that he perfectly knew that they were completely senseless and he knew in advance he would have to eliminate them to obtain something coherent. He didn't have to make much effort to "optimize" his sequence.  Third example: On this stereoscopic display, I show on the left a sequence in which they successively add two words in simple precision on the AGC, which gives 28 bits of precision; they say that this sequence of 7 instructions runs in 168 microseconds. On the right, I show the sequence of 3 instructions which adds two words on the IBM computer, which gives 25 bits of precision only, and which runs longer than the AGC sequence, that is in 246 microseconds. They say that the sequence of 7 instructions of the AGC runs in less time than the sequence of 3 instructions only of the IBM!!! So a sequence of 3 instructions takes more time to run than a sequence of 7 instructions, that is more than the double of instructions?  This difference comes from an over-optimistic estimation of the timings on the AGC. In fact, most often the documentation of the AGC does not explicitly says at all what the hardware of the computer does....Like this memory cycle of 12 clock pulses to read a word of 15 bits which is described nowhere, and remains a mystery!  Whereas the IBM documentation describes exactly what the computer does. And there are other problems with the sequence of the AGC.  First, there is an useless complication with the instructions I have outlined, "CAF ZERO" and "AD A"; the first one loads into the accumulator a variable which obviously contains zero in the same time that it clears the overflow, while the second one adds the variable A to the accumulator; this is equivalent to directly loading the accumulator with the variable A, which is done by the instruction I show on the right "CAF A".  So, now, we have for the AGC a sequence of only six instructions instead of initially seven, and which does the same thing as the initial sequence, and which will execute a little faster. But does this sequence really do the job, and is it optimal? In fact, it does not really do the job, for the eventual overflow generated by the first addition (A+1 and B+1) should be reported into the second addition (A and B), and it is not since the overflow is cleared by the instruction CAF. We would need an instruction which loads a variable into the accumulator without clearing the overflow, but I have not found it in the instruction set of the AGC.  Then, more importantly, this sequence is not even optimal, for there exist instructions which can handle double words which could have been used for doing this job: - The instruction "DCA A" loads into the pair of registers A and L the double word pointed by A, that is A and A+1. - The instruction "DXCH C" exchanges the contents of the pair of registers A and L with the double word pointed by C; that means that it puts the double word A,A+1 (currently in the registers A,L) into the double word C,C+1; note that we could have used an instruction which just puts the contents of the registers A,L into the double word C,C+1 without making the exchange with the pair of registers A and L, but this instruction does not exist in the instruction set of the AGC. - The instruction "DCA B" loads into the pair of registers A and L the double word pointed by B, that is B and B+1. - Finally the instruction "DAS C" adds to the double word pointed by C the pair of registers A,L; as the double word C,C+1 currently contains the double word A,A+1, and that the pair of registers A,L currently contains the double word B,B+1, this is equivalent to putting into the double word C,C+1 the sum of the double words A,A+1 and B,B+1 which is precisely the job to be done. We now have for the AGC a sequence which is not only correct, for it correctly handles the overflow in the addition of the double words, but is also reduced to 4 instructions. It certainly executes faster than the initial sequence of the AGC (and correctly), but I have not tried to know its execution time, for I consider the timings of the instructions of the AGC pure fantasy (unlike the ones of the IBM instructions which are real and fully reliable). |
 This chapter deals about the binary representation which has been adopted for the computer of Apollo (AGC).  In the start of the sixties, the computers were not still mature; they still were existing only as big costly machines, and only big companies could afford them. They still were not running in an optimal way, and it was the time that the engineers were looking for solutions which were very far from being as performant as today.  The computers first used the binary representation which is called "one's complement", because it was then seeming to be the simplest, the most obvious one. In this representation, the negative numbers are just represented by inverting the bits of the positive numbers (i.e. a bit 1 becomes 0, and vice versa). What is odd in this representation is that 0 has two different values, one called "+0" and coded with all bit to zeroes, and one called "-0" and coded with all bits to ones; yet, we have been taught in our mathematic lessons that +0 end -0 represent the same value! The fact that 0 could be represented with two different values in this representation system did not seem to bother those who first used it.  The IBM 7090, a computer of the start of the sixties (1962) used this representation system.  The UNIVAC 1100 of the same period also used this representation system.  However, as soon as 1963, computers started to use a different representation system called "two's complement". In this representation system, the negative numbers are the negative numbers of the one's complement system (with all bits complemented) added with one bit. Therefore the representation (on one byte) of -1 is no more 11111110 but 11111110+1=11111111, that is the representation of -0 in the one's complement representation; in short the negative numbers of the two's complement system are shifted by one position relatively to the one's complement system (-1 takes the place of -0 in the two's complement system). So, in this representation system, 0 has a unique value and no more two different values like in the one's complement system. The consequence of this is that the negative numbers can encode one more number than the positive numbers. In the one's complement system, a 16 bit word can represent numbers from -32767 to +32767, whereas, in the two's complement system, the same 16 bit word can represent numbers from -32768 to 32767. You are going to think that, if it is the only difference, it seems rather poor to explain the success of the two's complement system and the abandon of the one's complement system, but in fact the difference is much more important as I am going to explain you.  The first computer (or one of the first) to use the two's complement system is the PDP-5 of DEC. It was developped in 1963, and publicly released in 1964.  DEC made a successor to the PDP-5, the PDP-8, also using the two's complement system, and which was developped in 1964 and publicly released in 1965.  In April 1964, IBM announced the IBM 360, its first computer to use the two's complement system. This computer was used by the NASA for its mainframe computers.  And, in what concerns the microprocessors, which started to appear in the seventies (here the first of them, the intel 8080), they used the two's complement system from the start, and never the one's complement system. So why did the computer builders abandon the one's complement system for the two's complement system? 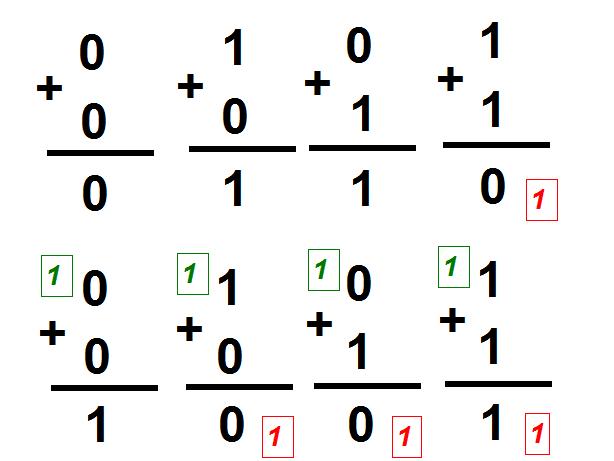 I first have a word about the addition of bits; bits are added taking into account a carry which is produced by the previous addition of bits, like in the decimal additions you are used to do. The upper row shows the addition of bits when there is no carry, and the lower row the addition of bits when there is a carry. I indicated on the bottom right of each addition the carry which is generated by the addition of bits, and which is taken into account by the next addition of bits.  This animation shows the mechanism of the addition of -0 with +1 in the one's complement system. Very oddly, the obtained result is...+0! Yet we have all been taught in our mathematic lessons that 1+0=1 and not 0. However, it does not mean that a computer using the one's complement system cannot correctly do additions, because the overflow is then tested to update the addition in a second pass. 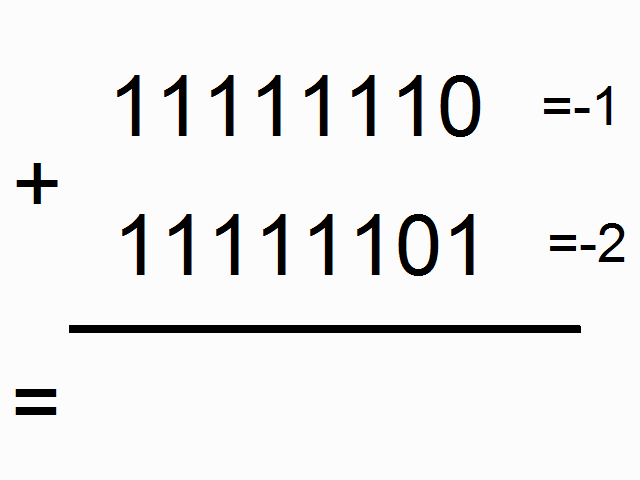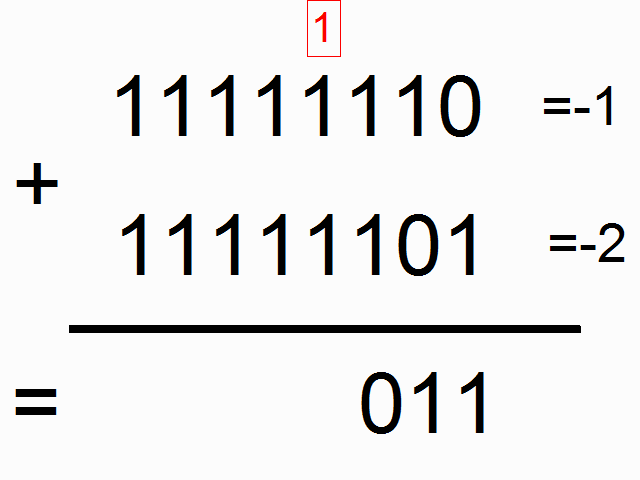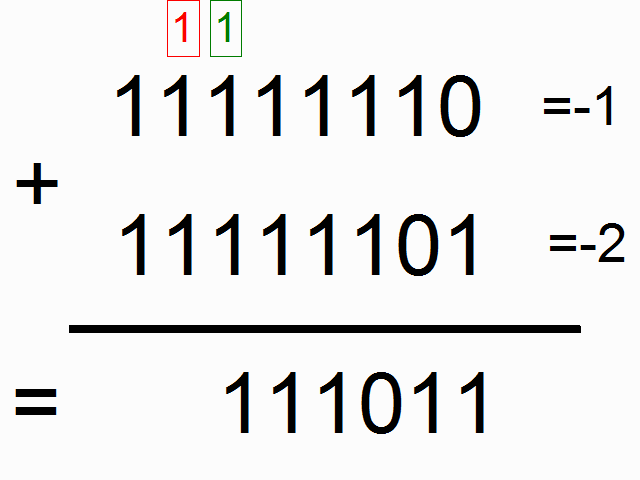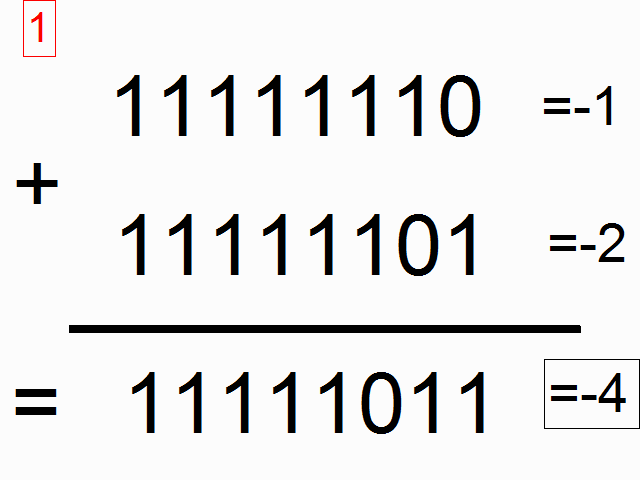 This second animation shows the mechanism of the addition of -1 with -2 in the one's complement system. Very oddly, the obtained result is...-4! Yet we have all been taught in our mathematic lessons that -1 added with -2 makes -3 and not -4. Once again the test of the overflow allows to correct the result of the addition and obtain the correct result. But it shows that the result of additions is not immediate and requires further tests.  Now let's see how an addition of negative numbers works with the two's complement system: If we add -1 with -2, we obtain...-3, that is directly the good result, no need to update it like in the one's complement system. That means that the two's complement system gives more direct results than the one's complement system, and avoids to make tests.  As the tests which are to be done by the one's complement system have better be made by hardware rather than by software, which would consistently decrease the performances of the system, that means that the hardware is more complicated to implement a one's complement system than for implementing a two's complement system. And, even with the added hardware, the one's complement system remains less performant than the two's complement system. So, you are beginning to understand why the two's complement system is largely preferable to the one's complement system.  In 1964, the NASA organized meetings to talk about the hardware of Apollo, and the choices which had to be made, in particular for the hardware of the computer.  In particular, they talked about using integrating circuits, in order to reduce the volume of the computer It was the time of making the good choice for the hardware and obtain the best efficiency as possible of the computer (i.e. minimization of its hardware, and optimization of its speed).  In that time, the advantages of the two's complement over the one's complement were known, and the computer builders were starting to use the two's complement instead of the one's complement for a better efficiency of their computers and reduce their costs. The engineers of the MIT could not ignore it (the engineer would developped the PDP-5 had even graduated from the MIT)! They knew that there were existing two representation systems, with one more performant than the other one.  They had the choice between the two's complement system, requiring less hardware to perform the same functionalities, and more performant...  ...and the one's complement system less easy to implement in hardware and less performant.  So, who got the crown? The more peformant system or the less performant one? Very surprisingly, it is the second one which was chosen, against any logic!  So, why the engineers of the MIT, who were certainly not stupid, chose what they knew to be the less performant system, the one which was requiring more electronic circuitry to obtain a result which would be less performant than the result which would have been obtained with the system they rejected?  I doubt that it was because they had the "nostalgy" of the one's complement system!  I rather think that the reason was that they didn't intend to make a serious computer that they knew that it would never make land a lunar module on the moon. |
 I have had a look at the book of Frank O'Brien "Apollo Guidance Computer, Architecture and operation". Frank O'Brien starts describing the philosophy of real-time systems with concurrently running tasks. What he says in his preface makes sense. Then he starts to describe the management of tasks in the computer of Apollo. But O'Brien is not a specialist of real-time systems; he is more a writer than a computer engineer. So, he is not conscious of some absurd aspects of the way the computer of Apollo was managed. On my side, I am really a computer engineer specialized in real-time applications, and I have worked on high-tech processes. So, what O'Brien fails to see, I can see it, and I am going to describe it in this chapter.  Modern computers have a stack. A stack allows to memorize local temporary variables, and also allows nested calls. In a multi-task system, the stack makes easier the swapping of tasks. Each task has its own stack, and when a task is to run, the stack pointer of the processor just has to point on the stack of the current task. A stack works according to the principle "Last in - First Out"; when data is to saved into the stack, it is pushed onto the top of the stack, and, when it is restored, it is popped from the top of the stack; if it is the last one to have been pushed, it will be the first one to be popped.  A stack allows to intelligently handle local data, and to make successive calls to subroutines: Each time a subroutine is called, its return address and its parameters are pushed onto the stack; this subroutine can also have temporary data that it also pushes onto the stack; this subroutine can at its turn call another subroutine, and the return address of this new subroutine and its parameters will be at their turn pushed onto the task; when the subroutine ends, its local data and parameters are popped from the task and so is its return address which allows it to know where it must return, that is to the address which immediately follows its call; the only limitation to a stack is its size.  Now, the computer of Apollo had no stack. It had a unique register to save the return address of subroutines, called Q. When the processor was processing an instruction of the main program calling a subroutine, before going to the start of subroutine, it was saving the address of the instruction following the call into the register Q. Then it started to execute the subroutine.  When the end of the subroutine was reached, the processor was reloading the program counter with the contents of Q, that is the address of the instruction following the call, and the processor could then resume the main program from this instruction.  So the register Q works perfectly for calling a subroutine from the main program. A stack is not necessary for a simple call of subroutine. 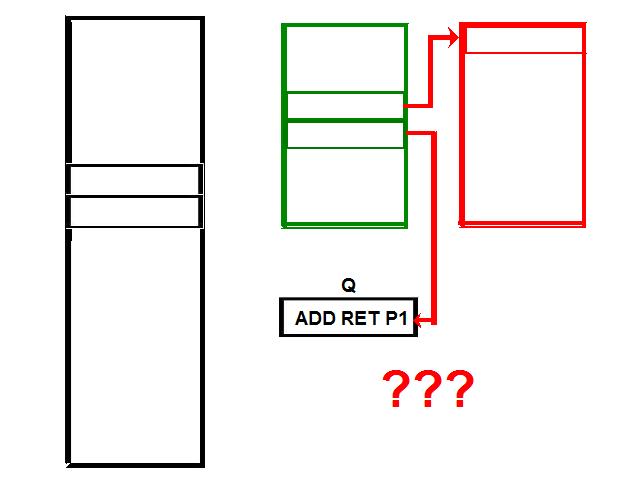 Now, let's suppose that the subroutine which has been called by the main program wants to call a second subroutine. It also has to save the address of the instruction following the call into the register Q, but there is a problem, for Q currently holds the address of the instruction following the call in the main program. So, what will the subroutine do?  Suppose that the subroutine decides to force the writing of the register Q with the address of the instruction following the call of the second subroutine, so that the second subroutine can come back to the first subroutine when it is finished. The second subroutine starts executing.  The second subroutine ends its execution, and the program counter is reloaded from the contents of Q which contains the address of the instruction following the call to the second subroutine. The first subroutine can continue processing. So, I have been too pessimistic, it can work?  No, in fact, because, when the first subroutine ends, the program counter is reloaded with the contents of Q; but Q currently contains the address of the instruction following the call to the second subroutine in the first subroutine, and not the address of the instruction following the call to the first subroutine in the main program. Therefore, the instructions between the call to the second subroutine and the end of the first subroutine are going to be executed again, and so on, indefinitely...  So, you see the effect of having a unique register for saving the return address: It forbids from making multiple nested calls. The main program can call a subroutine, but a subroutine cannot call itself another subroutine, otherwise it creates a fatal endless loop that the computer cannot get out of. Now, you can say that it may not be necessary that a subroutine can call another subroutine, that it is not worth implementing the management of a stack in the processor. May be, but the programmer must be conscious of that fact, and be sure never to call a subroutine from another subroutine.  Yes, we can accept the simplification of using a unique register to handle the calls of subroutines, which can be justified by the fact of not having to manage a stack which creates a complication for the processor. But, however, there is something which is less justifiable: When an interrupts occurs, not only the address of the interrupted instruction saved into the ZRUPT register, which is perfectly normal, but moreover the contents of this instruction is saved into the BRUPT register, and this is much less normal! 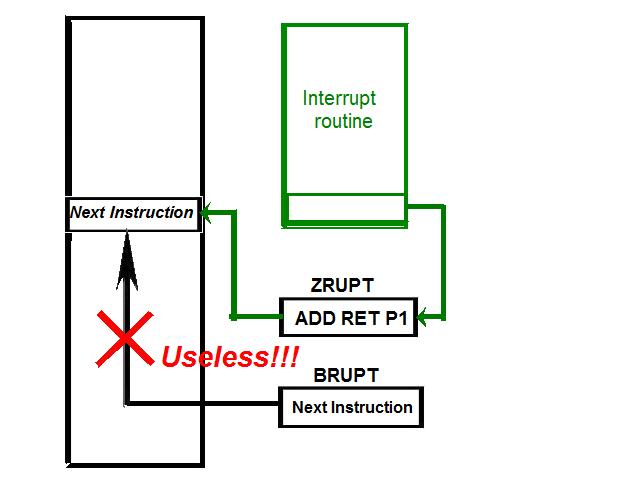 Indeed, when the interrupts ends, the program counter is reloaded from the contents of the ZRUPT register to continue processing from the interrupted instruction, which is a perfectly normal process, but moreover, this instruction would be updated with the contents of the register BRUPT in which it was saved prior to the interrupt processing? What for??? This is totally useless, as the interrupted instruction has kept its contents during the execution of the interrupt so there is no need to reload it from the BRUPT register! So the processor is doing operations which are totally useless; it unnecessarily complicates the processing of the interrupt and moreover it wastes time cycles, for saving into the BRUPT register and restoring from it take time cycles from the processor. So, the management of the BRUPT register is absolutely not justified by simplification, much to the contrary, for it creates a completely unnecessary complication, and wastes computer power (which is already limited).  We are now going to see how the management of tasks was done on the computer of Apollo. The principle is that each task was allocating a set of resources; these resources were consisting in a core set into which the task was memorizing its main attributes (current address, priority,...) and a larger area called VAC area, in which the task could memorize the variables it was specifically working upon. The task could also use global variables which are also used by other tasks. The first operation that a scheduled task was doing was to allocate these resources from pools of memory reserved for these resources. That means that there had to be at least a remaining available core set in the pool of core sets, and a remaining available VAC area in the pool of VAC areas; when the task had found a core set and VAC area among the available ones, it was marking the first word of them as being reserved, so that other incoming tasks could not take them. Conversely, when a task was ending, it was releasing the resources by unmarking the first words of the resources as being free. But, it is not because a task had allocated resources that it could immediately run. The higher priority tasks had priority of execution over the lower priority ones. Suppose that two tasks are currently defined; a task P3 of priority 3, and a task P1 or priority 1; as P3 has a higher priority than P1, it is current by running, and P1 is waiting for P3 to finish before executing. A register NEWJOB indicates if the currently running task is the most prioritary one or not; if it is, NEWJOB contains 0, and if not, NEWJOB contains the address of the core set of a waiting task more prioritary than the current task. Generally NEWJOB will contain 0.  Now comes a task P2 of priority 2 intermediary between the priorities of P1 and P3. The first thing that P2 does is to allocate its resources, that is a core set and a VAC area, and to initialize the core set (marking it as reserved, putting into it the start address of its program, its priority...).  But P2 sees that it is less prioritary than the current executing task P3, so it does not change the contents of NEWJOB which remains set to 0. So P3 goes on executing without being disturbed by P2. 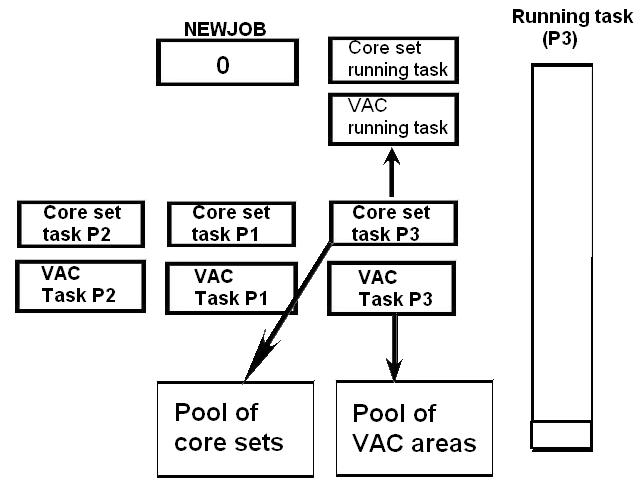 P3 reaches its ends and releases the resources it had reserved (the core set and the VAC area). The processor now looks for the most prioritary task among the waiting tasks by examining the priorities memorized in the core sets, and finds that it is P2. 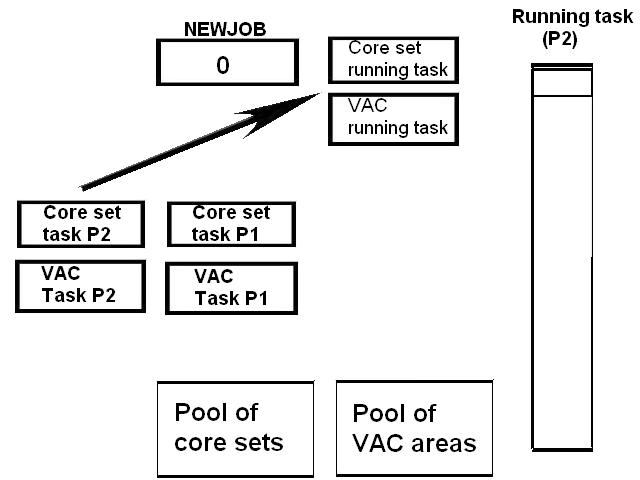 The core set and the VAC area of P2 are copied into the first core set and the first VAC area which are always the ones of the currently executing task. The program counter is loaded with the address of the first instruction of P2 which starts executing..  P2 finally ends, and releases the resources it had reserved (the core set and the VAC area).  Now, P1 is the only remaining task, so its core set and VAC area are copied into the first core set and VAC area, which are the ones of the currently executing task, and P1 starts executing.  P1 finally ends, and releases it resources. There is no remaining task, so they say that in this case, they make run a pseudo task called "DUMMY JOB". But, this has little chance to happen, as they say that the SERVICER tasks were accumulating for being delayed by other tasks, so there always were several tasks remaining (even to the point of draining out the resources!). 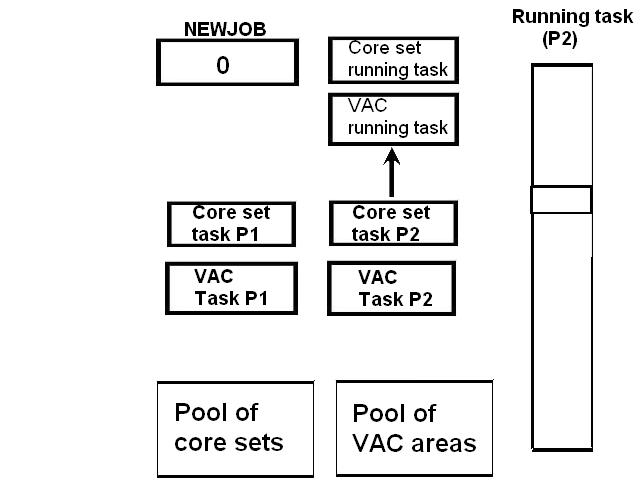 Now let's suppose that the most prioritary task currently running P2 has a priority 2. 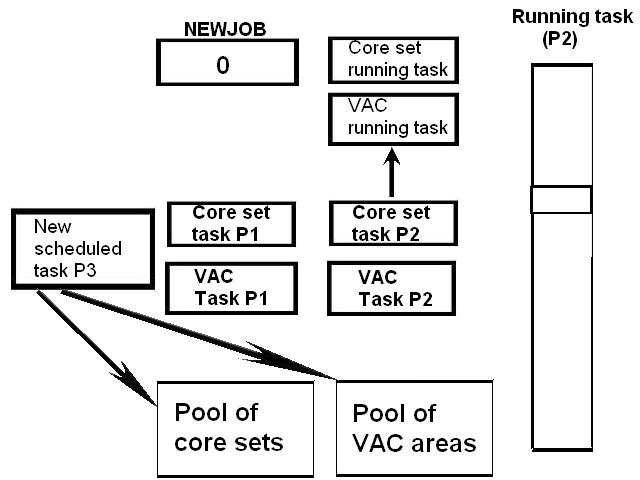 Now comes a task P3 of priority 3 higher than the priority of the two other tasks. The first thing that P3 does is to allocate its resources, that is a core set and a VAC area, and to initialize the core set (marking it as reserved, putting into it the start address of its program, its priority...). 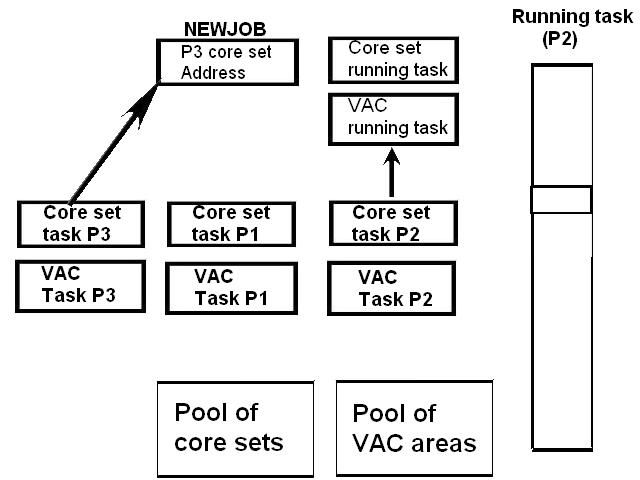 But, unlike in the previous example, P3 can see that it has a higher priority than the currently running task P2. So, it does not leave the register NEWJOB unchanged, but much to the contrary writes the address of its core set into it, so that the task P2 can be informed that a more prioritary task is waiting to execute.  P2 goes on executing till it means a test point of task change. A test point is described as being a set of the two following instructions: CCS NEWJOB TC CHANG1 If NEWJOB is currently 0, the current task is currently the most prioritary one, and the test of NEWJOB by CCS makes the processor skip the next instruction; the task goes on executing; but, if NEWJOB is not zero, the test of NEWJOB by CCS makes that the following instruction is executed, which calls a program which was making the swapping of tasks to replace the current task with the more prioritary one. Here it is the case, NEWJOB is not zero, and contains the address of the core set of P3.  Consequently, the swapping of tasks must be done. The core set and VAC area of P2 are first updated with the fist core set and VAC areas of the currently executing task (formerly P2), so that P2 can recover its executing context when it starts executing again.  Then the core set and VAC area of P3 are copied into the first core set and VAC area of the currently executing task, and P3 starts executing from its beginning. 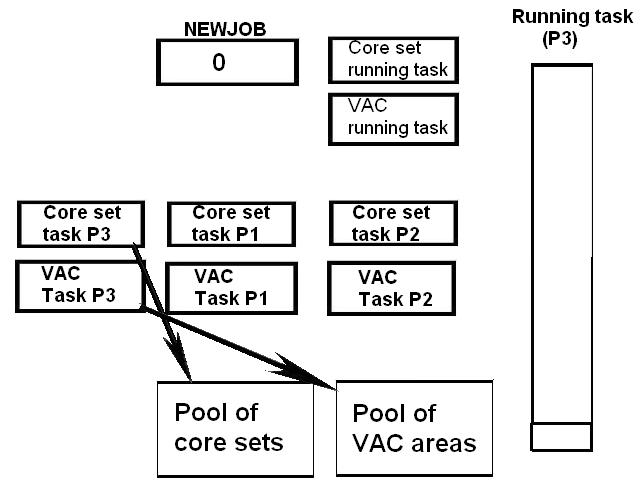 P3 finally ends and releases its resources (Core set and VAC area). 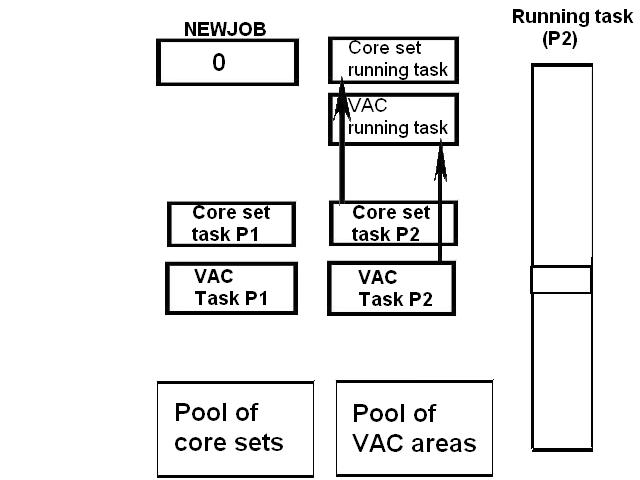 After the end of P3, P2 is now the more prioritary task. the first core set and VAC area of the currently executing task are updated with the core set and the VAC area of P2; as the current program counter of P2 has been memorized into its core set, P2 can restart from the point it had been interrupted by P3, and not from its beginning.  P2 ends and releases it resources (core set and VAC area). Now, P1 is the only remaining task, so its core set and VAC area are copied into the first core set and VAC area which are the ones of the currently executing task, and starts executing. P1 finally ends, and releases it resources.  Now, this process is uselessly complicated. The NEWJOB register is not even necessary. As soon as P3 arrives, instead of waiting for P2 to reach a test point, it would be more practical if the core set and VAC area of P2 were immediately updated with the core set and the VAC area of the currently executing task (P2). 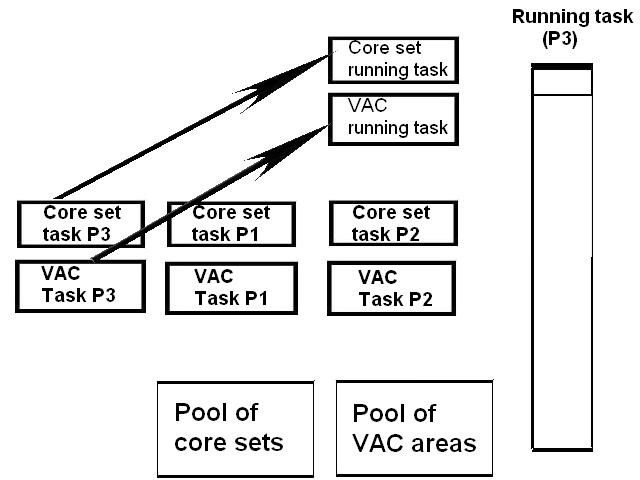 And the core set and VAC area of P3 would be copied into the first core set and VAC area of the executing task, so that P3 could begin to execute.  With this management, P3 would not have to wait for P2 to see that there is a more prioritary job waiting; it would immediately start to execute as soon as it is scheduled, without delay.  In the management they have devised, compared with the management I have described, there are operations that the management I have described does not have to do, and which overload the switching of tasks. First the incoming task has to update the NEWJOB register; but this is not the operation which takes the more time from the processor. The operation which takes the more time is that the currently executing task has to regularly test if a more prioritary task has not arrived, by regularly inserting these two instructions into its program: CCS NEWJOB TC CHANG1 If it does not do this test often enough, then the new incoming task will have to wait longer before being serviced. On the other hand, if the currently executing task makes this test quite often, then, may be that the new incoming task can be serviced quite quickly after it arrives, but the currently task will waste much time making these tests. With the process I have described, no time is wasted in making tests, and the new incoming task is immediately serviced. They say that the programmer should take care that no more than twenty milliseconds separate two successive tests, but how do you want the programmer to estimate that? It is delirious! Now, you can say: In the system I have described, a more prioritary task can interrupt the current task anywhere it currently is. The current task cannot choose the point where it is interrupted. Most of times, it does not matter, because, when the current task works on its own VAC, as it is the only one which accedes and modifies it, it can be interrupted at any moment. But, in some cases, the current task may wish not to be interrupted during a limited sequence (when it read or updates global variables which are also used by other tasks, for instance). In that case there is a possible solution. 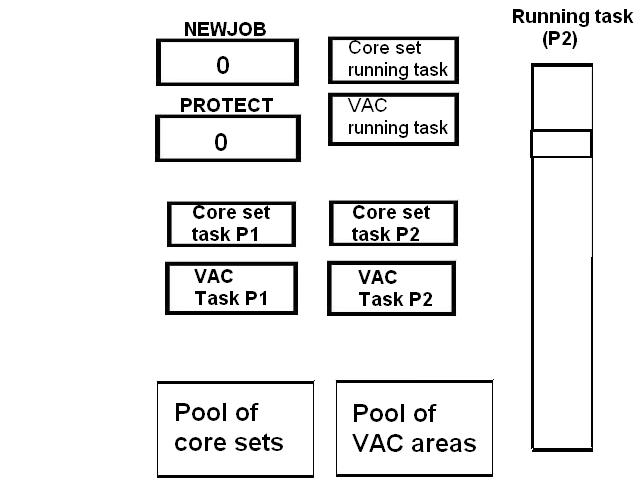 We still use the register NEWJOB in this solution, but we add another special register I'll call "PROTECT". Generally the NEWJOB and PROTECT registers contain 0. 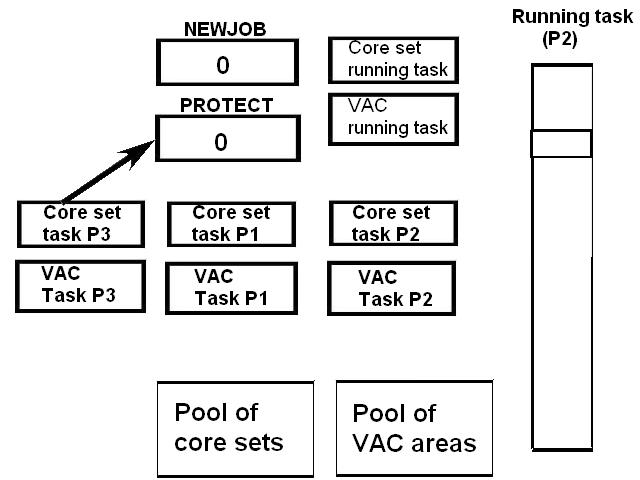 When a new more priotary task P3 is scheduled, it checks the PROTECT register. 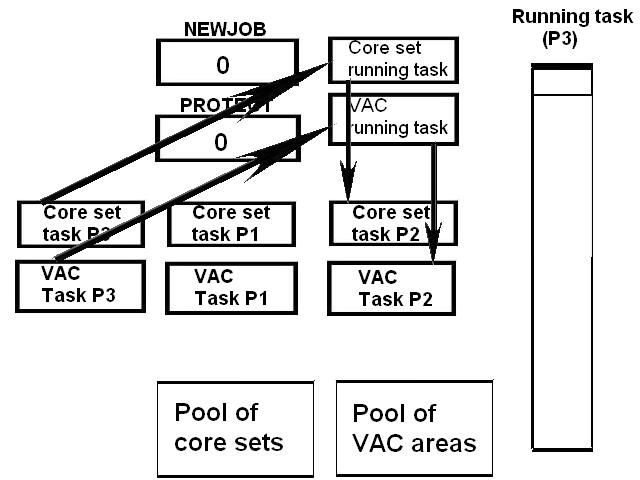 If the PROTECT register contains 0, it means that the current task is not currently executing a protected area of code, and the new task P3, instead of updating NEWJOB, immediately makes the swap of tasks, updating the core set and VAC area of the task P2 with the core set and the VAC area of the currently executing task, and copies its own core set and VAC area into the core set and VAC area of the current task. Then it starts executing from its beginning.  Now, suppose the current task wants to execute a sequence of program during which it does not want to be interrupted by a more prioritary task. It first writes a 1 into the PROTECT register, to notify the fact that it is currently executing a protected area of code.  Then, while the current task is executing its protected area of code, a new more prioritary task P3 arrives. P3 checks the PROTECT register and sees that it contains 1. 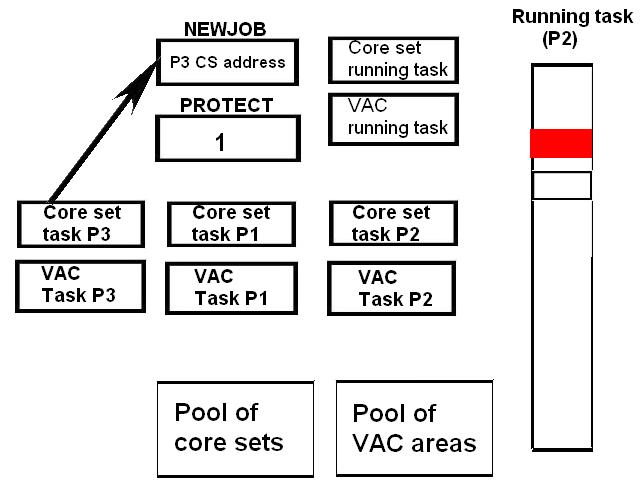 P3 then knows that the current task is executing a protected area of code, and, instead of immediately making the swap of tasks, just writes the address of its core set into the NEWJOB register, the same as the solution which has been retained by Apollo. Then, it does not execute, but waits for P2 to start it.  P2 ends its protected area of code, and writes a 0 into the PROTECT register in order to end the protection from an interruption.  Immediately after having unlocked PROTECT, P2 must test NEWJOB in order to know if a more prioritry task has been scheduled while it was executing its protected code. if it is the case (i.e. NEWJOB does not contain 0), P2 makes itself the swap of tasks and starts P3, while it starts waiting for P3 to finish to resume from the point it has been interrupted. 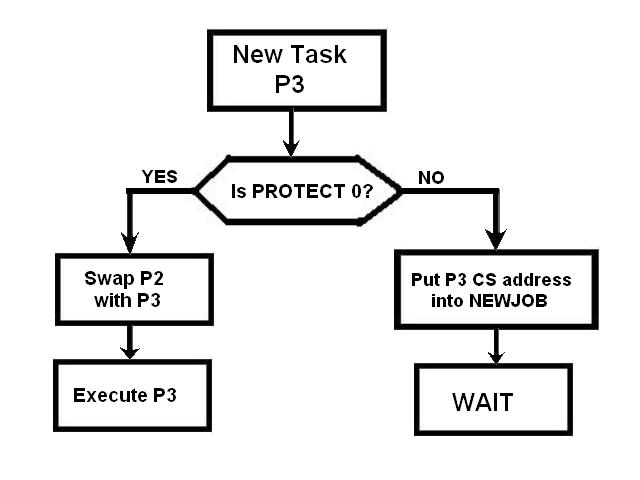 I show here the logical diagram for a new incoming task.  And I show here the logical diagram for the current task when it wants to execute a sequence of instructions that it does not want to be interrupted while it is executing it. 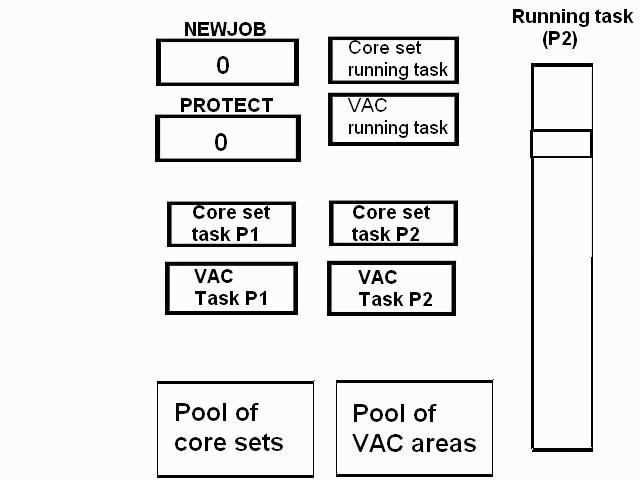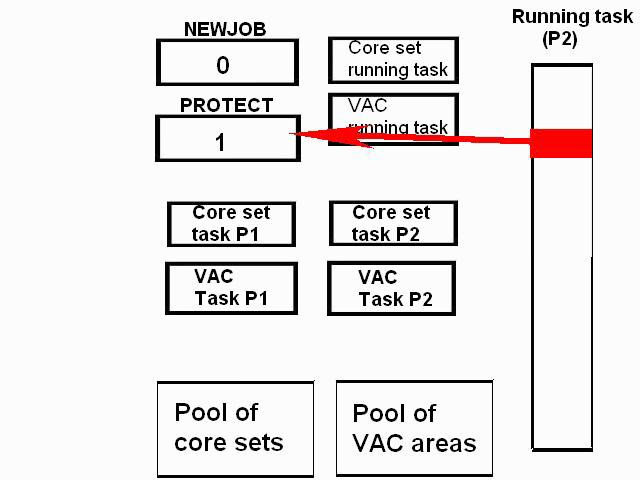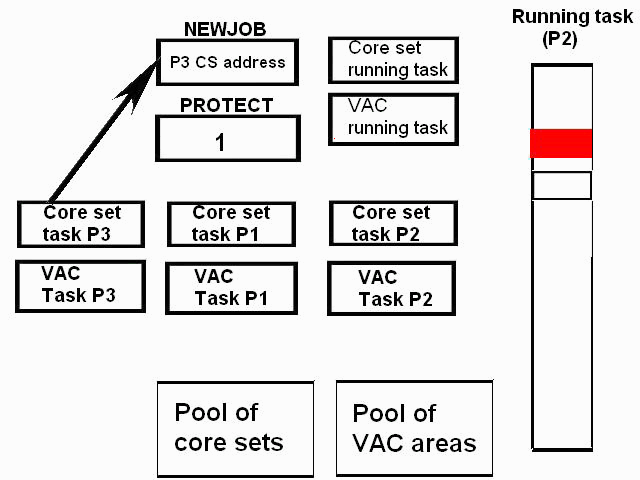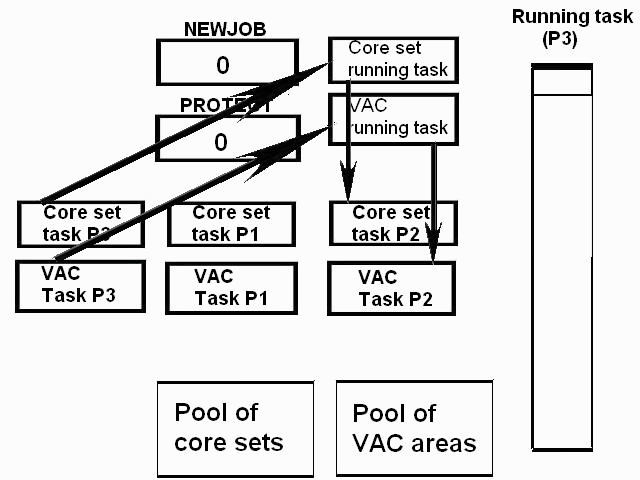 In this solution, there still are tests of the NEWJOB register, so why have I protested against the way they have devised it? Because, in the latter solution, the use of NEWJOB is only occasional, exceptional...  ...while in the Apollo solution, this test is systematical, and repetitively made at close intervals. Therefore, it is going to suck a good part of the power of the computer.  Now, what was the main problem of the management of tasks of the computer of Apollo? The main problem is that they had given the lowest priority to the most important task, that is the task "SERVICER", which was in charge of the guidance (which was including acquiring the data from instruments, computing equations from these data and the expected data which were resulting in corrections to apply to the main engine and the RCS, and sending corresponding commands to the engines). As a result, the SERVICER task was often interrupted by more prioritary tasks which were delaying its execution. The consequence was that the execution time of SERVICER was often longer than what it should have been and was exceeding its period of execution (after each period a new SERVICER task was automatically scheduled, for it had to run periodically); this period was of two seconds, which should normally have been enough for the SERVICER task to complete its treatment before the next occuring SERVICER task; but it often was not, due to the perturbation from other tasks (including the task managing the keyboard and display).  So, by force of being constantly delayed, and not being able to finish in time before the next occurring SERVICER task, the waiting SERVICER tasks were progressively accumulating. And, each time a new SERVICER task was scheduled, it was reserving resources from the pools of available resources (a core set and a VAC AREA). At a given moment, there were so many delayed SERVICER tasks waiting, that they had drained out all the available resources, and there was remaining no free core set or VAC area in the pools of resources.  If, at that moment, a new more prioritary task was scheduled, it was trying to allocate its own resources, but it could not for they all had been drained out by the waiting SERVICER tasks. The computer was then in a situation it could not manage, for the new incoming task could not get the resources it absolutely needed to run.  In this situation, they say that the only solution was to make a restart of the computer. They say that they have convenient solutions to make a restart, to minimize the work the computer has to make to come back to the situation where it was before it got stuck, but it is bullshit, a restart is never innocuous. The truth is that this situation should NEVER have occurred. And there are solutions never to let it happen as I am going to show.  A first solution would be that, even if there are several waiting SERVICER tasks, only one should currently reserve resources. Suppose a new SERVICER task is scheduled and the previous one is still running (for having been too often interrupted by more prioritary tasks).  Since there already is a SERVICER task running, this new task would not take new resources (i.e. it would not reserve a core set and a VAC area).  Instead of that it would just increment a task counter in the core set of the current SERVICER task, to inform it a new SERVICER task has been scheduled while it was running.  Then it would just vanish and the currently executing SERVICER task would go on normally executing (unless interrupted by a more prioritary task).  When ending, the current SERVICER task would test its task counter in its core set in order to determine its next action. 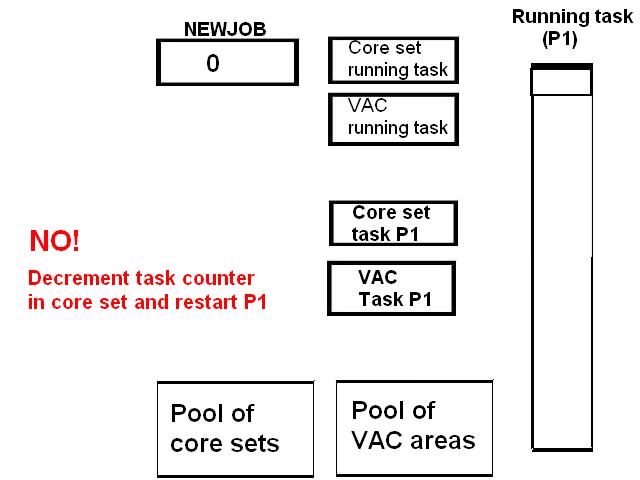 If the task counter is different from 0, that means that at least a new servicer task has been scheduled while it was executing; in that case, it would keep its resources instead of releasing them, decrement the task counter, and start again from its beginning.  And if the task counter is null, it means that no SERVICER task is currently waiting, and the current SERVICER task would just normally free its resources. With this process, even if there are several SERVICER tasks waiting, and whatever this number, only one core set and one VAC area would be reserved for all the waiting SERVICER tasks; there is no danger that the waiting SERVICER tasks could drain out the available resources, and the computer would not get stuck, and would not have to ever restart.  Even if this solution is not retained, and that a new incoming SERVICER task allocates resources even if another SERVICER task is already running, there is still another solution for preventing the SERVICER tasks from draining out all the available resources. Suppose a SERVICER task is currently running, and another SERVICER task is waiting for the currently running SERVICER task to finish. Then comes a third SERVICER task. What shoud this third SERVICER task do? Allocate resources and wait like the second SERVICER task? 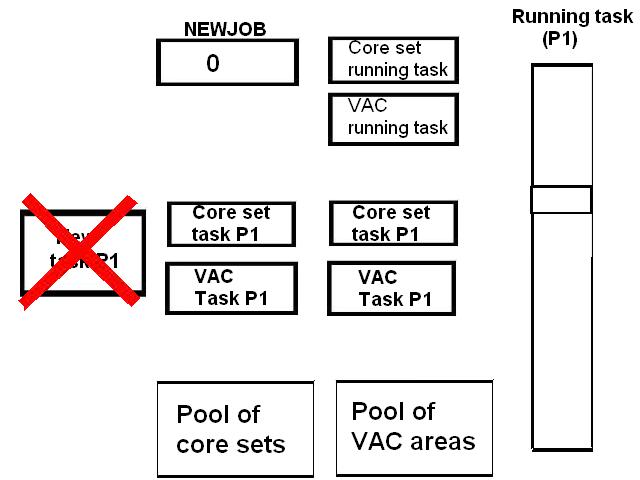 Not at all, it is totally useless that this new SERVICER task waits....Because, by the time it can execute, a new SERVICER task will already have been scheduled! So it is better to just drop it; it is not sane to let the SERVICER tasks accumulate, because there is no way that too many accumulated SERVICER tasks can be serviced at a regular pace, and it is important that they be serviced at an as regular pace as possible, and not a floating one. So, the fact that the SERVICER tasks drain out the avalable resources is far from being a fatality and can easily be avoided.  So, how was the AGC managing the restart? At regular points, called "way points", a task was saving its data into a save area before processing the next instruction.  So, the AGC is stuck, after having insanely wasted processing time.  Each existing task goes back to its last way point.  The task's data is restored from the data which had been saved at this way point.  And then the task executes again all the instructions between the way point and the point it got stuck. So the task wastes time restoring data and executing again instructions it had already executed before getting stuck. Why do I say that it wastes this time? Do I mean that the task could have restarted without going back to the way point? This management of way points is made still more absurd by the fact that saving the task's data is far from being instantaneous. Some imagine that it could be done very fast by a hardware trick, but there is no miracle: the task's data is in the core magnetic memory, and so is the save data; so saving all the words of a data area toward another one means a sequence of read and write accesses in the magnetic memory, and this is far from being instantaneous; nowadays the memory accesses are extremely fast, but the memory accesses in the core magnetic memory were rather slow in comparison.  A guidance routine is currently running. 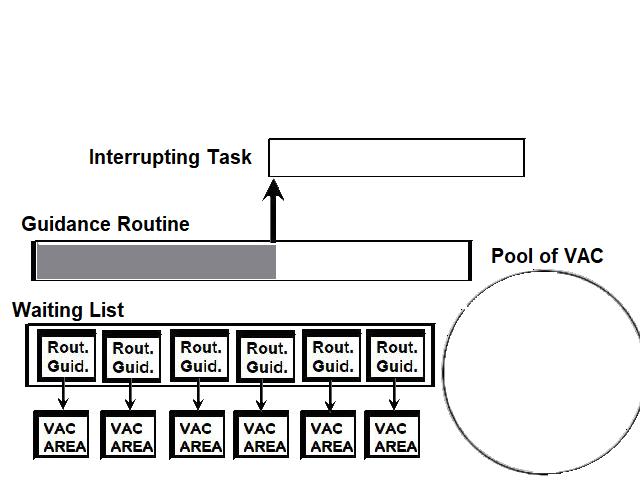 A task with more priority interrupts it. 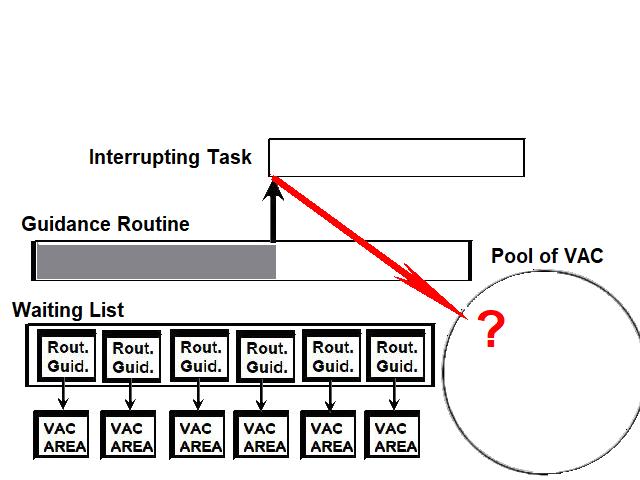 This task tries to allocate a VAC area so that it can run with. But it can't, for the delayed guidance routines in the waiting list have drained out all the available memory ressources. 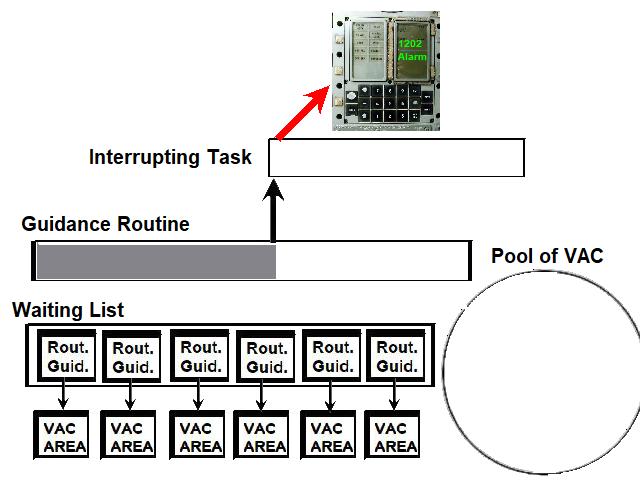 So, the 1202 alarm is displayed on the DSKY, warning the astronauts of the problem. 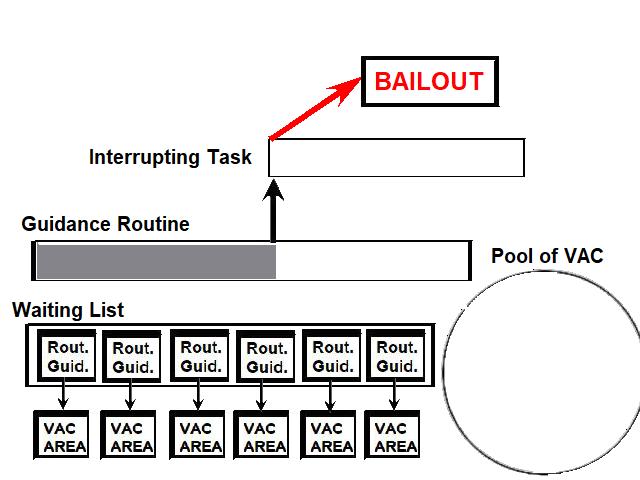 The procedure BAILOUT is then called, in order to make the final treatment. So, what should the procedure normally do? 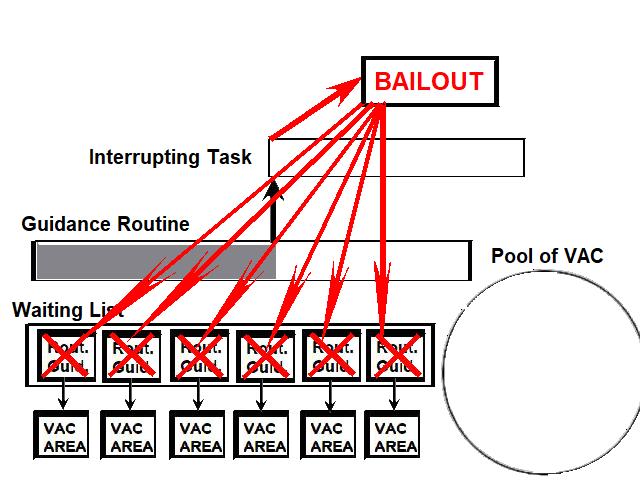 BAILOUT should first remove all the delayed guidance routines from the waiting list. Indeed, they are too late and will never be executed, for, when the current guidance routine has finished running, it will be automatically replaced with the next guidance routine, the delayed guidance routines in the waiting list will not be used. 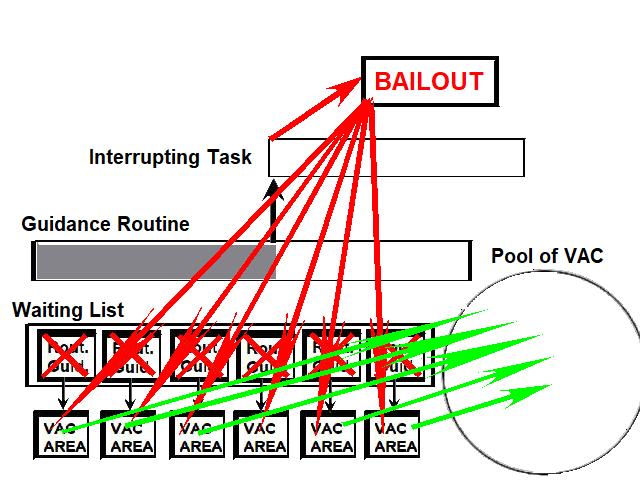 So the removed guidance routines do not use the memory resources they have allocated any more, and these ones can be returned to the pool of memory resources. 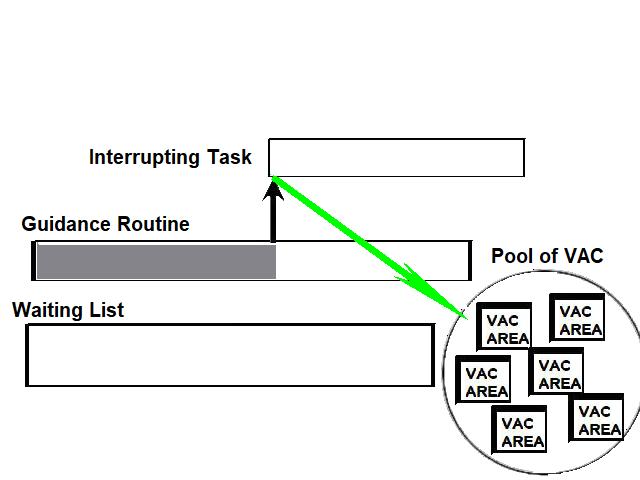 Now that the pool of VAC areas has been replenished, the interrupting task can allocate the VAC area it needs to run. 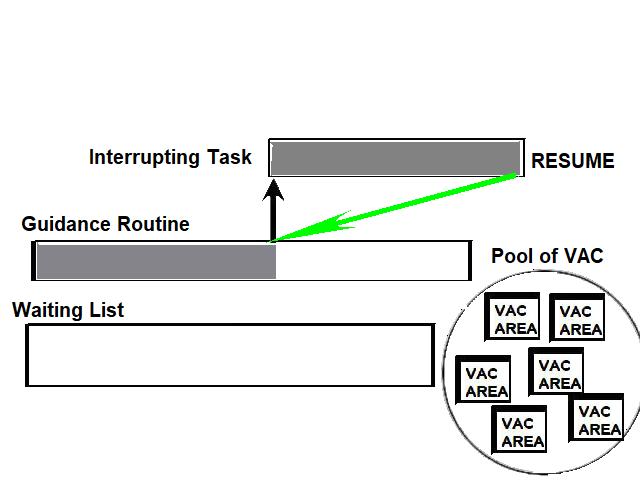 The interrupting task can then run, and, when it ends, it executes the instruction "RESUME" which allows to go back the point of the guidance routine where it had been interrupted. 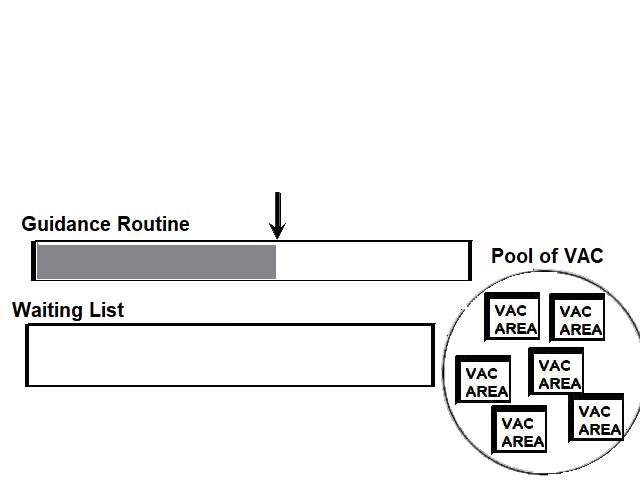 And the guidance routine can them resume its processing from the point it had been interrupted, with the current data it uses.  When the current guidance routine ends, the next guidance routine is automatically started, for the guidance routines are automatically started every two seconds. We here have a clean restart, a sane situation where the memory resources are available again, and which allows the computer to work normally. 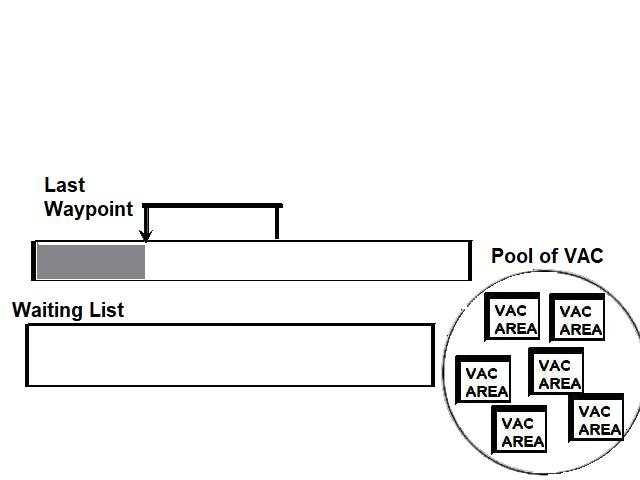 So, why, when the interrupting task has returned to the point that the guidance routine had been interrupted, the program would come back to the previous last way point...  ...would transfer to the current data the data saved at this way point, which is a relatively long process... 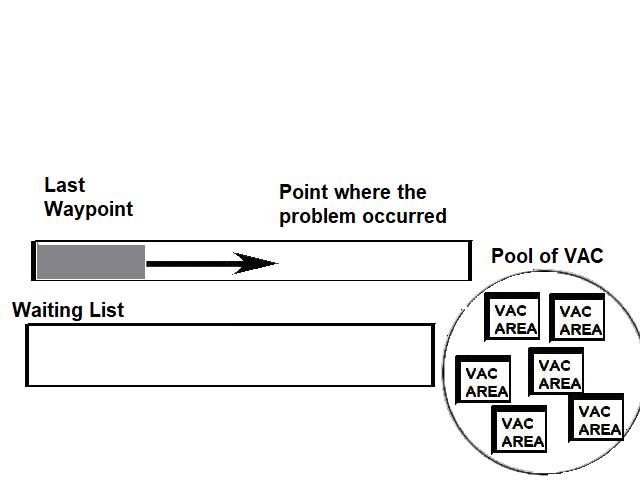 ...and would execute again the instructions between this way point and the point that the guidance routine had been interrupted... ..While all it had to do, after having returned from the interrupting task, was just to continue executing the part of program which follows the point of interruption! First of all, and that alone could have ensured that they don't accumulate and drain out the resources, the SERVICER task, which is the most important task, for it ensures the guidance of the space ship, should have been given the highest priority and not the lowest one. What are the other consequences of giving the lowest priority to this task?  In his "Tales about the Apollo guidance computer", Don Eyles says that the delay of reaction of the engine to the command was of 0.3 seconds, but they had initially estimated that it would be of 0.2 seconds; so the engine was late of 0.1 second on the estimation; the consequence, according to Don Eyles, is that they were observing serious perturbations in the reaction of the engine, that they were calling "throttle excursions" and of which I represent the graph on the figure, and these throttle excursions could potentially be dangerous, according to Don eyles, and endanger the guidance of the space ship.  So, they were planning to compensate the delay of the engine by sending the command 0.1 seconds earlier, in order to make like the reaction time of the engine was only of 0.2 seconds.  But an engineer decided not to compensate, and he was right, for the NASA managed to reduce the reaction time of the engine from 0.3 seconds to 0.2 seconds, which made that the compensation was no longer necessary, and which made the "throttle excursions" disappear.  Now, imagine, if the SERVICER task cannot regularly be serviced, and its execution is constantly delayed in a random way, that means that the moment that the command is sent is going to vary consistently more than the 0.1 seconds. So, if the fact that the command is delayed of 0.1 second can have serious consequences, imagine what it can give if the command is delayed more than that and in a random way? Wouldn't it be a good reason to give the highest priority to the SERVICER task, so it can run in a regular way, and can make the computations and send the commands in time? And, if the SERVICER task had not had to make repetitive tests to see if there is a more prioritary task waiting, it would have saved time for its execution, and it would have had more chance to finish in time!  And also, if there had not been instructions (PINC ancd MINC) of the computer to count hardware pulses (and little matters that they are called "unprogrammed instruction", for they still steal time cycles from the computer)...  ...And that the task of counting the hardware pulses had been devoted to a simple electronic counter that the processor can read at any moment with an I/O operation (and the I/O operation exists, it is described in the documentation!)... ...it would have saved a hell of computer cycles which would have been more intelligently used for processing the SERVICER task which would have stood much more chance to finish in time and be served at a regular pace instead of an erratic irregular one (and even resulting in the draining out of resources because of the absurd management, and consequently the restart of the computer!). THERE SHOULD NEVER HAVE BEEN A RESTART OF THE COMPUTER, NEVER! And it was perfectly possible, even with the limited resources of the computer, without adding any complication to the hardware (and even simplifying it!).  It even goes further in the absurdity, because they say than an unknown program was stealing time cycles from the computer, degrading its performances. LOL, hackers were existing even in this time!  So, definitively, the computer of Apollo was not a serious computer, but a clown, just good for the circus! |
 This chapter deals about the core rope memory which supposedly contained the software which allowed the lunar module to land on the moon.  Nowadays, the memory of the computer is contained in integrated chips. This one is already quite old, the current ones are smaller and contain more memory, but relatively to the memory which was available in the time of Apollo, it is revolutionary and super concentrated. This type of memory is called "RAM" memory (for "Random access memory"), which means that it is possible both to write into and read from it. But this type of memory also loses its contents when it is powered off.  This type of memory is called "ROM" ("Read only memory") or "PROM" (for "Programmable read only memory), and unlike the previous one, it can only be read and not written. But it has the advantage over the previous one not to lose its contents when it is powered off. This type of memory is used when it must contain a fixed program which must always remain in it, and allows the computer to start when it is powered on. It is also possible to plug such chips if the computer must do a given task when powered on, this task being programmed in the chip.  The PROM are programmed with a special device; the programmer starts a program which commands the PROM programmer, and the user inputs his program; the burning program then sends the user's program to the PROM programmer which burns the instructions into the PROM, so that it definitively contains these instructions. the programmed PROM will always contains these instructions, whether the computer is on of off (but it can't be dynamically written, unlike a RAM).  There also are specials PROM chis called EPROMS (for Erasable PROMS) which can't be written several times, though not dynamically. In order to rewrite an EPROM, its contents must first be erased; in order to do that, the EPROM has a sort of little "window" that the UV light can go through and which allows the UV light to erase the contents of the EPROM.  When an EPROM has to be reprogrammed, it is put into a special device which sends UV rays through the window of the EPROM; after some time of exposition, the contents of the EPROM is erased, and it can be programmed again the same way as a normal PROM, with the PROM programmer. Of course, it is not as fast as writing into a RAM, which is immediate, but it allows to re-use several times the EPROM unlike with the ROM, whereas the EPROM can keep its program when it is off like the ROM and unlike the RAM memory. So, it is more economical than using a ROM, if the resident program has to be modified several times.  In the fifties, sixties, and seventies (at least the beginning of the seventies), the microchips were not existing. The computers were all big machines which were not affordable to common people and that only industries could afford. The memory of these computers are consisting in arrays of ferrite cores; each core was representing a bit of memory; it gives you an idea of the number of such cores which were needed to have an important amount of memory (though these computers didn't have as much memory as the modern micro-computers). In that time, there was no fixed memory which was keeping information when it was not powered because there was no need for it.  When a computer was started, the operating system was first read from magnetic tapes, and stored into the core memory reserved for it.  Then the users were giving their programs on punch cards (one instruction per punch card, which means that your program had as many punch cards as it had instructions), and the operator was introducing the bunches of punch cards into a special reader which was decoding them and sending them to the processor which was storing the instructions into the core memory. These programs were using data which were also stored and modified in the core memory.  Planes might have needed dead memory for the computer if embarked computers had been existing at that time, but the computers were still not compact enough to be embarked on planes; so the planes were using analog calculators which were fit for guiding the planes of that time, even if they could not have been used to manage your budget or play with video games.  So, how was the core memory working? The cores were put at the intersection of rows and columns of a matrix of wires; there were two perpendicular wires going through each core. The magnetic field of the core could be modified if each of the wires crossing in it was fed with a half current, for the sum of these two half currents was making a full current which was allowing the magnetic field of that core to be modified. On the other hand, if only one wire was fed with a half current and not the other one, this half current alone was not enough to change the magnetic field of the core. On the schema which is shown, only the central core is crossed with two wires fed with a half current, and it is the only one which will have its magnetic field modified. The other cores have only one wire fed with a half current and the other wire has no current going through it, so their magnetic field will not be modified. This process allows to specifically target the core which is to be modified (or read). 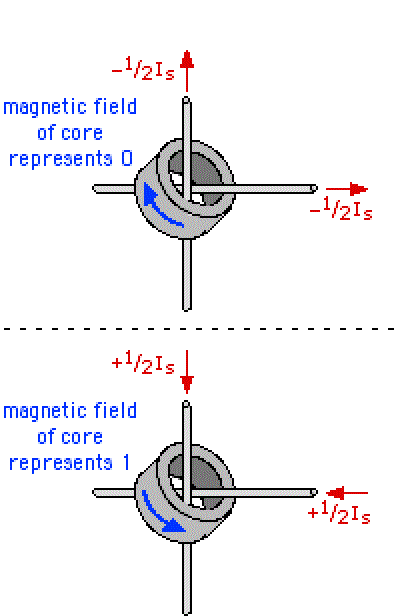 When the two crossing wires are fed with a negative current, the ferrite core is polarized negatively, and conversely, when the two crossing wires are fed with a positive current, the ferrite core is polarized positively. The fact that the ferrite core is polarized negatively corresponds to a bit set to zero, and the fact that it is polarized positively corresponds to a bit set to one.  When the core is already polarized negatively, and negative currents are sent through the crossing wires, the magnetic field of the core will remain unchanged; a sense wire which goes through the core will then detect nothing; the computer then knows that a zero was stored on this core. On the other hand, when the core is currently polarized positively and negative currents are sent through the crossing wires, the magnetic field of the ferrite core will change, and this change creates a short pulse through the sense wire; though this pulse is very short, the electronics is fast enough to detect it; it is the detection of this pulse which says that the ferrite core was polarized positively before the currents were sent through the wires; the computer then knows that a one was stored in this core. The problem of the reading is that it is always made by sending a negative current through the crossing wires, and thence the core will always be polarized negatively after it has been read, even if it was polarized positively previous to the reading; that means that, if a pulse has been detected in the sense wire, positive currents must then be sent through the crossing wires so that the core returns to it previous state corresponding to the one it was memorizing (otherwise, next time a zero would be read instead of a one). If may seem a little complicated explained that way, but in fact this process is extremely fast and allows to read the memory with a quite high speed.  So the cores are inserted into an array of wires, and these wires are commanded with circuits of which the schema is represented on the right; this circuit can send either a negative current (for reading the cores) or a positive current (for reprogramming the ones of the cores which have been detected to a one); the negative or positive current will only be sent if an enable signal allows it; this enable signal depends on the current memory address which is to be read or rewritten. So, you can see that the principle of the core memory lays on a dynamic change of the magnetic field. When the core memory is switched off, it is always deprogrammed, and cannot hold information; when it is switched on, the cores must first initially be polarized positively or negatively by sending either positive or negative currents, according to the fact that the cores must memorize a one or a zero. And when a memory data is to be modified, the crossing wires of the cores corresponding to the ones of this data must be fed with positive currents (unless they already were positively polarized), and conversely the crossing wires of the cores corresponding to the zeroes of this data must be fed with negative currents (unless they already were negatively polarized).  In the normal core memory, you can see that the activation wires passing through the cores have a quite important diameter relatively to the core. Indeed, they must be able to carry a sufficient current to change the magnetic field of the core, and, if they were too thin, they would not be able to stand this current. In the Wikipedia's article, they say that each half current was between 0.4 and 0.8 ampere (two half currents must be sent to change the magnetic field of the core, one is not enough); if it is a single wire which must change the magnetic field of the core, this current must be doubled; it would then be between 0.8 and 1.6 ampere. Concerning the sense wires, they can be thinner, for the pulse they get is relatively weak. So, how was the "rope core memory" of Apollo working? They were making the sense wires go through cores or over them; when a sense wire was going through a core, it was supposed to represent a one, and when it was going over instead of going through, it was supposed to represent a zero! Up to 64 sense wires could go through a core! I have found a document on the site of the NASA explaining how the core rope memory of Apollo and the erasable memory too were working.  First I have to give some explanation about the diode and the transistor, for I'll refer to these explanations in what follows. A diode is a device which lets the current pass into one direction and blocks it in the other direction; and in the direction it lets the current pass, the diode behaves like a resistor of almost null value. A transistor is a more sophisticated device which has three electrodes called the base (the electrode on the left), the emitter (the electrode with an arrow) and the collector (the top one). The particularity of a transistor is that a small variation between the base and the emitted yields a bigger variation between the collector and the emitter; this particularity allows to use the transistor as an amplifier. A transistor can also be used to block or allow a current between the collector and the emitter with a command inputted on the base of the transistor. There are two types of transistors: - In the transistors called "NPN" the current goes from the collector to emitter; these transistors are represented with the arrow of the emitter oriented toward the exterior of the transistor. - In the transistors called "PNP" the current goes from the emitter to the collector; these transistors are represented with the arrow of the emitter oriented toward the interior of the transistor. When the transistor is connected so that a current can go from the base to the emitter, the current can go from the collector to the emitter (or from the emitter to the collector in the case of a PNP); the transistor if then unblocked. But, when the transistor is connected so that no current can go from the base to the emitter, the current cannot go from the commector to the emitter (or vice versa in the case of a PNP); the transistor is then blocked. 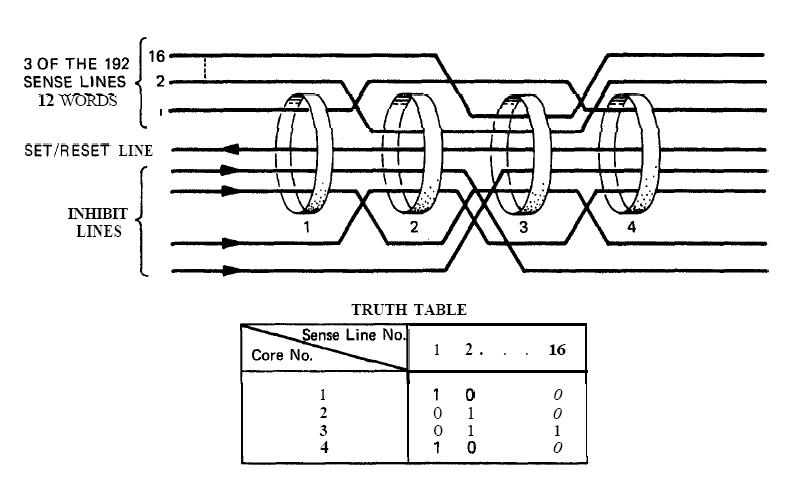 Now this is the the simplified schematics they give for explaining how the core rope memory of Apollo works. In order to test which cores a sense line is passing through, and which cores it is bypassing, it is not possible to activate several cores in the same time. 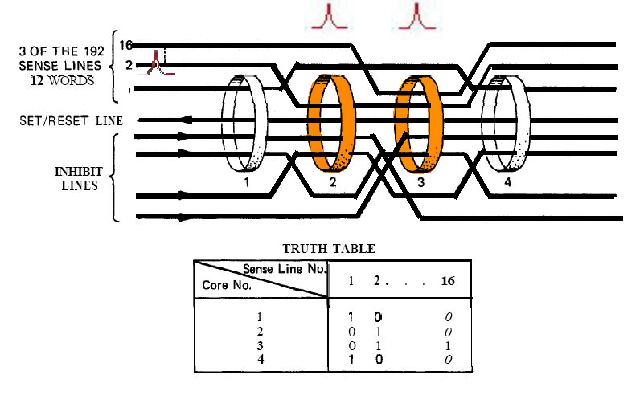 Indeed, if two cores a sense line is passing through are activated simultaneously, the sense line will receive a pulse, but it will not be possible to know if the sense line is going through the first of these two cores, or the second one, or both, because, whether only the first core generates a pulse, or the second does, or both do, in all these cases the same pulse, standing for a 1, will be generated in the sense wire. On the other hand, if the sense wire receives no pulse, then it can be sure that it is passing through none of these cores, and so that zeroes are programmed on these cores for this sense wire. The only solution to test the bits on a sense line is to activate the cores one at a time (but when a core is activated, all the sense lines can simultaneously be tested for this core). 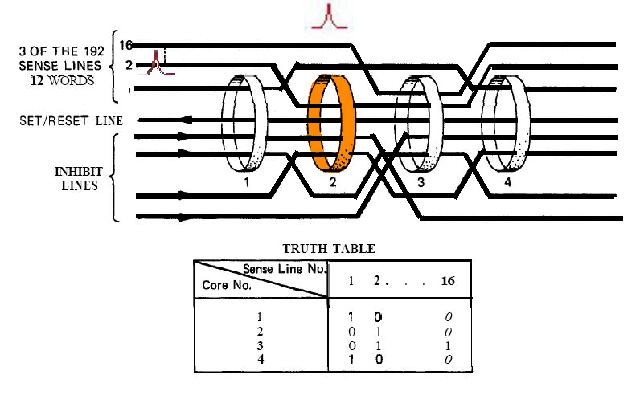 If only the second core is activated, if a sense line sees a pulse, then it can be sure it is going through this core; and if it sees no pulse, it can be sure it is bypassing this core. 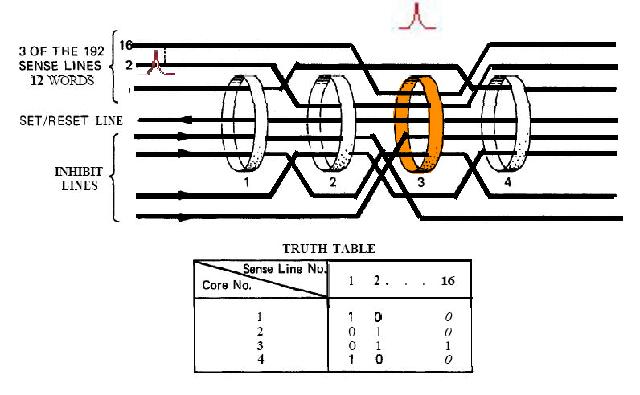 Likewise,if only the third core is activated, if a sense line sees a pulse, then it can be sure it is going through this core; and if it sees no pulse, it can be sure it is bypassing this core. When successively activating the second core and the third core, the second line receives a pulse in both cases, and it thence knows with certainly it has a 1 programmed on these two cores.  So, how to activate cores independently, so that only one can be activated at a time? The most logical way is to make each activate line pass through a single core, one per core. There are two possible ways: 1) the way described on the upper half of the figure A set current (left of the figure) in one direction is first sent into the activate line, changing the magnetic field of the core. Then a reset current (right on the figure) in opposite direction is sent into the activate line to reset the magnetic field of the core back to its original state. This double change of the magnetic field of the core generates a pulse into a sense line which goes through the core (and, if the sense line bypasses the core, it will see no pulse). 2) The way described on the lower half of the figure. A set current (left of the figure) in one direction is first sent into the activate line, changing the magnetic field of the core. Then a reset current (right on the figure) in opposite direction is sent, not into the activate line, but into a common reset line to reset the magnetic field of the core back to its original state. This double change of the magnetic field of the core also generates a pulse into a sense line which goes through the core. In this mode, only set currents are sent into the activate lines, and only the common reset line resets the cores.  But, curiously, they have not chosen this natural mode to activate the cores. The lines which allow to select which core is activated are not "Activate lines", but "Inhibit lines", and they work in a converse way: They don't allow to activate a core, but to the contrary to prevent the activation of a core. On my examples, the bottom wire going through a core is an inhibit line, the central wire is a common set/reset line which goes through all the cores, and the upper thinner wire is a sense wire. 1) The processus of activation of a core is described on the upper half of the figure. A set current (left of the figure) in one direction is first sent into the common set/reset line, changing the magnetic field of the core. Then a reset current (right on the figure) in opposite direction is sent into the common set/reset line, resetting the magnetic field of the core back to its original state. This double change of the magnetic field of the core generates a pulse into a sense line which goes through the core (and, if the sense line bypasses the core, it will see no pulse). 2) in case that a core must not be activated because it is not currently the tested core, the processus of inhibition of the activation of the core is described on the lower half of the figure. The set current (left of the figure) in one direction is sent into the common set/reset line, but a reset current in opposite direction is simultaneously sent into an inhibit line going through the core. The set current and the reset current are of equal intensity, and, as they are opposed to each other, they are going to cancel each other; because of the reset current going through the inhibit line, the set current of the common set/reset line cannot change the magnetic field of the core, and thence no pulse will be generated by this core in a sense line passing through this core. The reset current (right on the figure) is then sent into the common set/reset line, but, as the magnetic field has not been changed because of the inhibition, the core will not react to this reset. So, in order to activate a single core, no current must be sent into the inhibit line(s) passing through this core, and, in all the other cores, there must be (at least) an inhibit line that a reset current is passing through. (note too that the fact that currents are sent into two wires must not be compared with the currents sent into two wires in the normal core memory: In the normal core memory, it is two half currents complementing each other, and here it is two full currents cancelling each other). So, the concept of the inhibit lines seems less obvious to use than the one of the activation lines, but it seems to work anyway. Yet this concept creates big problems that we are going to see. 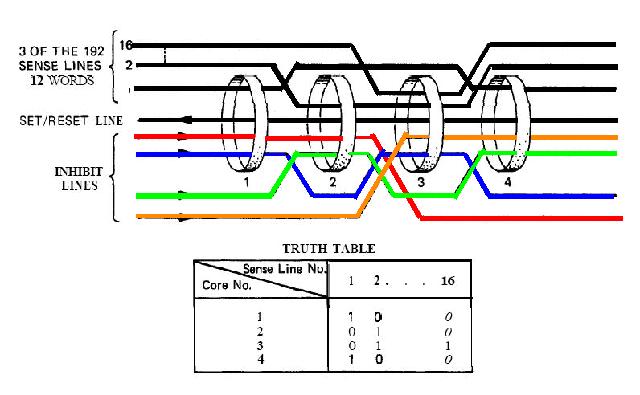 I have colored with different colors the four inhibit lines which allow to select or inhibit the cores. 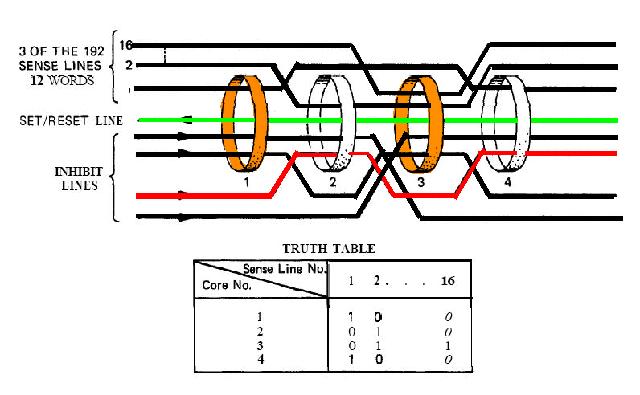 You can see that each of these inhibit lines goes through two cores. The third activation line goes through the second and fourth cores. If a reset current is sent into this line only, the set current going through the common set/reset line will activate the first and third cores, for only the second and fourth are inhibited from changing the magnetic field of the core. 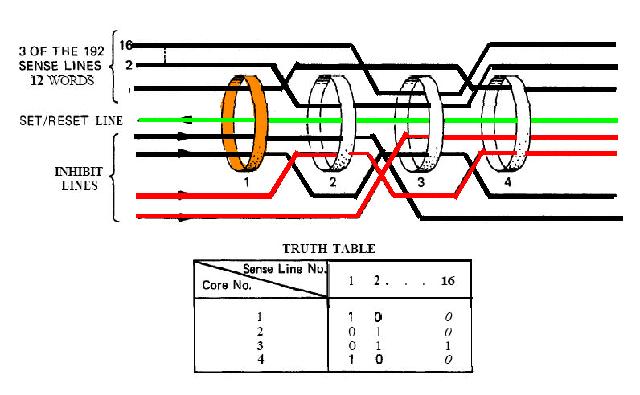 If we want only the first core to be activated, then reset currents must be sent both through the third and fourth inhibit lines. Notice that these lines both go through the fourth core; that means that two reset currents instead of one will be sent through this core. 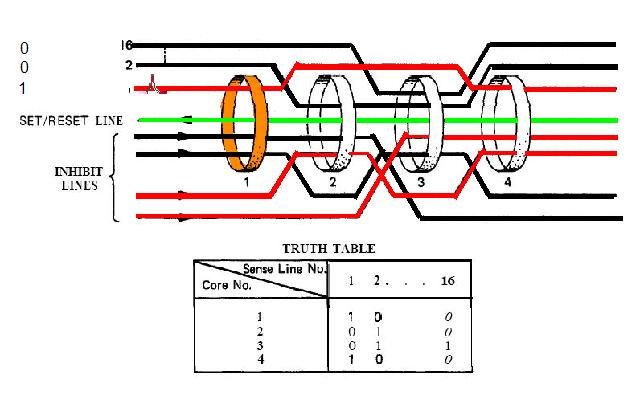 The process of reading of the bits programmed on the cores for the 16 sense lines is described in this demonstration. Reset currents are first sent into the third and fourth inhibit lines when the set current is sent into the common set/reset line so that only the first core is activated. As only the first sense line is going through the first core, but neither the second sense line nor the 16th sense line (the other sense lines are not specified), only the first sense line has a 1 programmed on this core while the other sense lines have a 0 programmed on this core. So, for the first core, we have the combination "10...0" (starting from the first sense line). 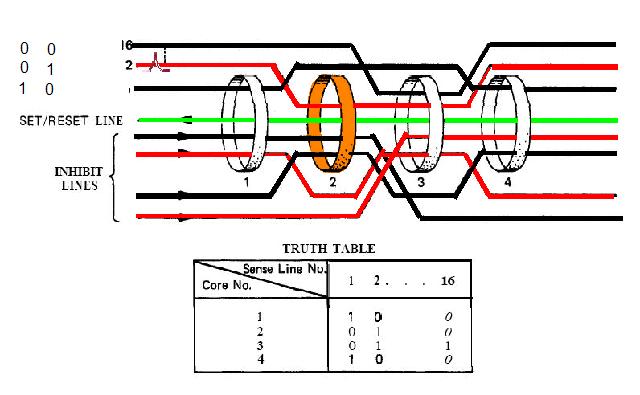 Then a reset current is sent through the second and fourth inhibit lines, causing the inhibition of all the cores save the second one, which is the currently tested one. As only the second sense line is going through the second core, it is the only one which will get a pulse. So, for the second core, we have the combination "01...0".  Then a reset current is sent through the first and third inhibit lines, causing the inhibition of all the cores save the third one, which is the currently tested one. As the second and 16th sense lines are going through the third core, it is these two ones which will get a pulse. So, for the third core, we have the combination "01...1". 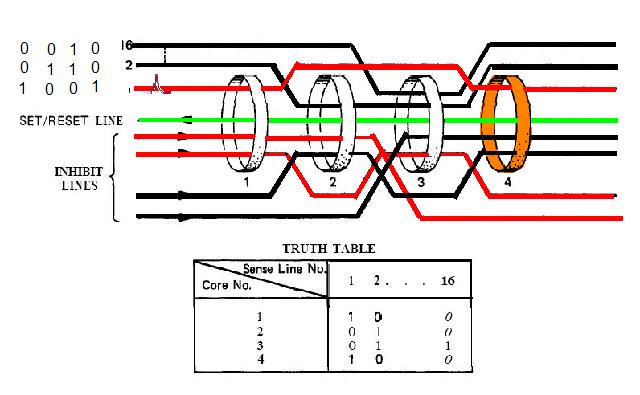 Then a reset current is sent through the first and second inhibit lines, causing the inhibition of all the cores save the fourth one, which is the currently tested one. As only the first sense line is going through the fourth core, it is the only one which will get a pulse. So, for the fourth core, we have the combination "10...0". 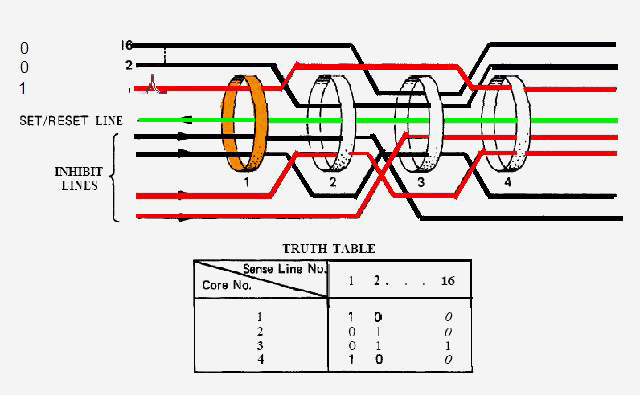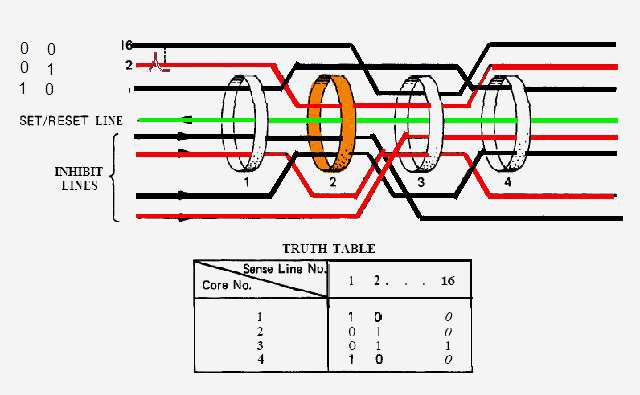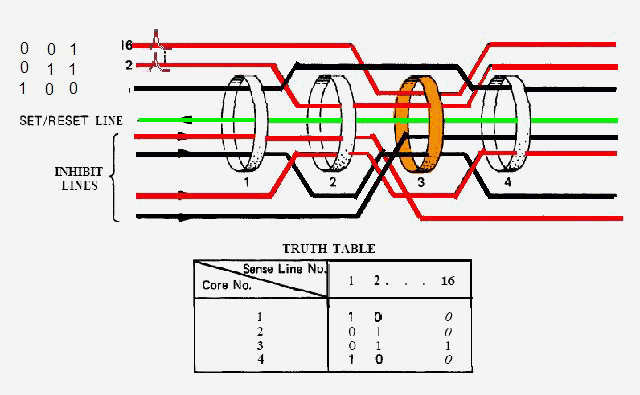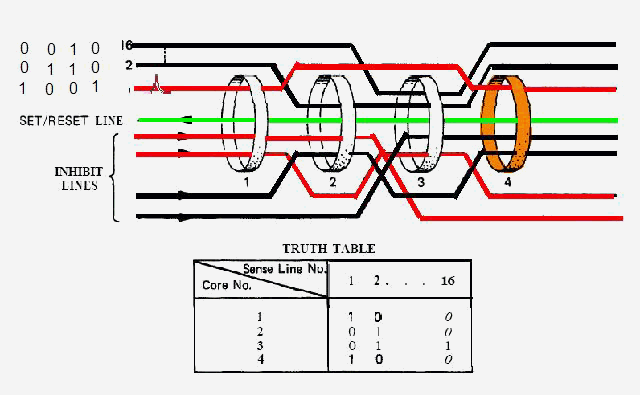 So, by successively activating one core at a time, it is possible to read the bits which have been programmed on the sense wires by making them either go through a core (for a 1) or bypass a core (for a 0). With these 4 cores and 16 sense lines, it is possible to memorize 4*16=64 bits. Notice however that we have had to send two reset currents at each step of the process (and that there is a core which receives two reset currents instead of one).  Another solution would be to make each inhibit line go through all the cores save one, so through 3 cores in this simplified example. .The first inhibit line goes through the second, third and fourth cores, but not the first one; so sending a reset current into it will inhibit the activation of all the cores save the first one. .The second inhibit line goes through the first, third and fourth cores, but not the second one; so sending a reset current into it will inhibit the activation of all the cores save the second one. .The third inhibit line goes through the first, second, and fourth cores, but not the third one; so sending a reset current into it will inhibit the activation of all the cores save the third one. .The fourth inhibit line goes through the first, second, and third cores, but not the fourth one; so sending a reset current into it will inhibit the activation of all the cores save the fourth one.  So now we just have to send one single inhibit current to test each core...but we have to make pass through each core a number of inhibit wires equal to the number of cores minus one (3 in our example of 4 cores). We'll thence have to look for another solution.  Another solution is to make pass a single inhibit line through each core: . The first inhibit line will go only through the first core and will only allow to inhibit the first core. . The second inhibit line will go only through the second core and will only allow to inhibit the second core. ... So, in this solution, only one inhibit line goes through a core, and it solves the number of inhibit lines going through a core. 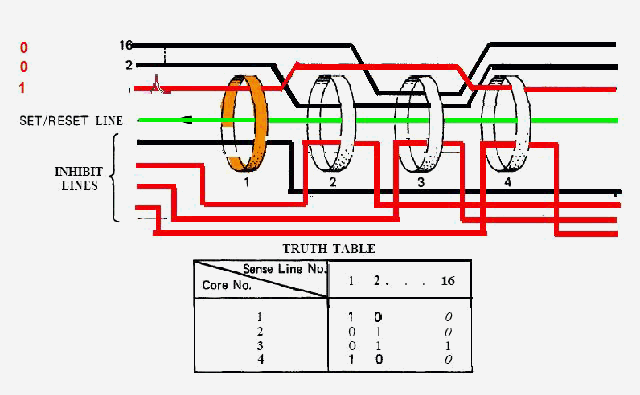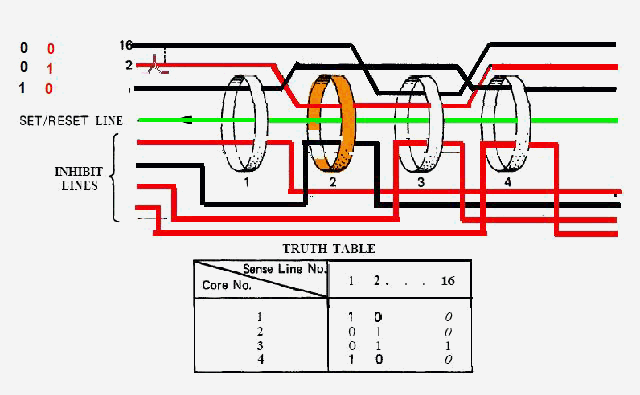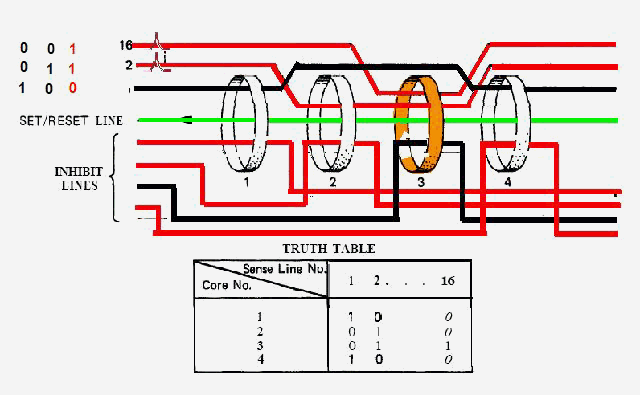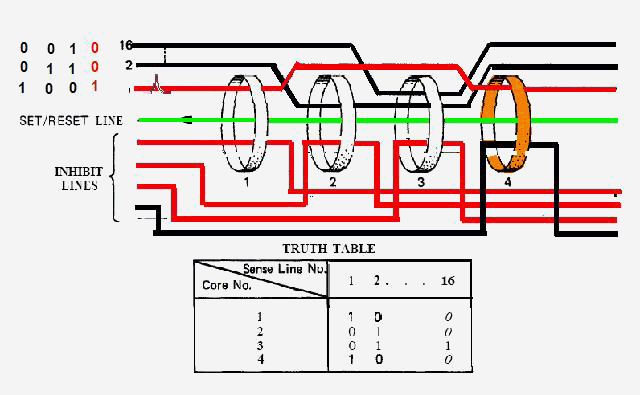 But, when a core is to be activated, all the other cores must be inhibited, which means that reset currents must be sent into all the inhibit lines save the inhibit lines going through the currently tested core. Even if the management of the memory is made with separate units of which they show the schema, that still makes three currents which must be sent to read a core when one would have been enough if activate lines had been used instead of inhibit lines.  So, why not use the normal concept of "Activate wires" instead of "Inhibit wires"? In the concept of "Activate wires", only one Set current is sent into an activate line when a core is tested, and only one activate line goes through a core. No problem of multiple lines going through a core and no waste of energy. This shows that using the concept of "Inhibit wires" to alternately activate the cores which are tested makes no sense, and that the concept of "activate lines" is the only reasonable concept which can work. In fact, they could have activated the core which is to be tested the same way as in the conventional core memory: By sending half currents in lines and columns of a matrix of wires, so that the core which is tested is at the intersection of the line and column into which half currents are currently sent.  But the fact that they have illogically used "Inhibit lines" instead of "Activate lines" is not the only problem of the ROM card. This schema shows how the pulse generated by the cores was read. There were commands to activate the reading of the pulses generated by the cores individually. In order to select the sense line which was to generate a pulse on the output coil (circled in blue), they were using line selection and module selection commands; for instance, on this schema, the only sense line of the four which can generate its pulse into the coil is the one framed in light green, because it is the only one connected to both a selected line (represented in dark green) and a selected module (also represented in dark green); the three other ones, framed in light red, cannot generate their pulse into the coil, for they are connected either to a non-selected line (represented in dark red) or a non-selected module (represented in dark red too), or even to both. 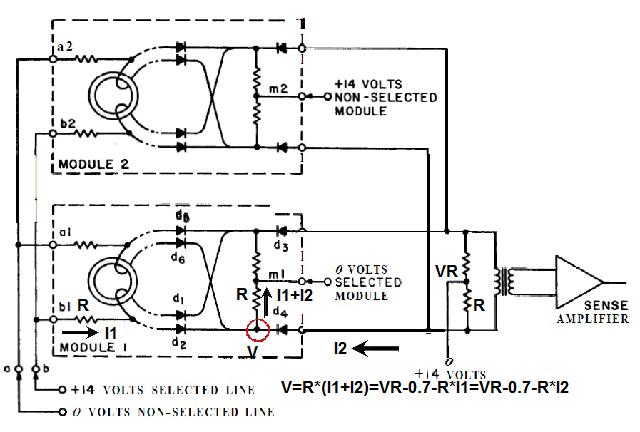 I give some explanations about the way the sense current was transmitted to the coil. - I call VR the reference voltage of 14 Volts. - I call R the value of the resistors - I call I1 the intensity which comes from the line selection. - I call I2 the intensity which goes through the diode D4 (which comes from the right). - I call V the voltage of the common point I have circled in red. The intensity which goes to the module selection point is equal to the sum of I1 and I2. So V: - Is equal to R*(I1+I2) - Is also equal to VR-0.7-R*I1 - And also equal to VR-0.7-R*I2 (0.7 being the voltage between the ends of the diodes) so we have the two equations: R*(I1+I2)=VR-0.7-R*I1 R*(I1+I2)=VR-0.7-R*I2 Solving these equations gives: I2=(VR-0.7)/(3*R) 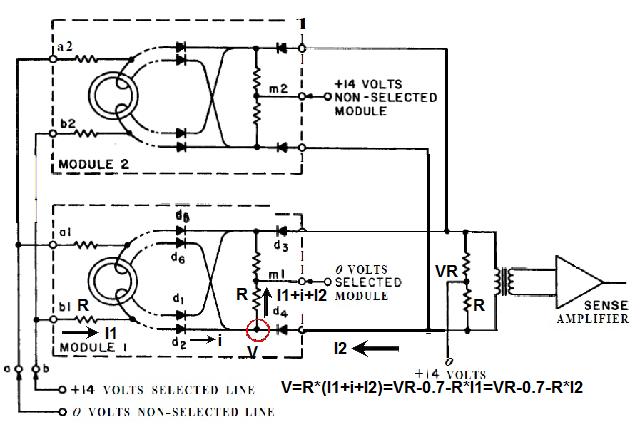 When the sense line generates a current I'll call i, this current also goes through the resistor which is connected to the module selection point. So, now we have: V=R*(I1+i+I2) And the equations become: R*(I1+I2+i)=VR-0.7-R*I1 R*(I1+I2+i)=VR-0.7-R*I2 Solving this equation gives this result: I2=(VR-0.7)/(3*R)-i/3 So a variation equal to i/3 relatively to the previous value.  That means that only one third of the very weak pulse in the sense line comes to the coil! 48 selected sense wires may potentially have a current going through, and, as the current of the selected sense wire is divided by three before coming to the primary of the coil of the amplifier, it makes a too weak current to be amplified.  The pulse detected in the sense line is amplified to be used by a circuit of which the schematics is shown here. We have seen that the pulse in the coil is only one third of the impulstion in the sense line. Now we are going to see that this very weak pulse was even incorrectly amplified.  This amplifier uses two pairs of transistors; this special assembly is called a "push-pull"; it means that the first coupled pair of transistors (circled in green) amplifies the positive edge of the pulse (colored in green), and the second coupled pair of transistors (circled in blue) amplifies the other edge of the pulse (colored in blue).  I show here a simple amplifier made with a transistor. The signal to amplify is sent on the base of the transistor (the connection which is on the center of the transistor), and the amplified signal is obtained on the collector of the transistor.  On the first pair of the push-pull (transistors circled in green), the collector of the first transistor of the pair is connected on the base of the second transistor; it is the connection I have drawn in red. But, on the second pair of the push-pull (transistors cicled in blue), the collector of the first transistor should also be connected to the base of the second transistor...but it is not the case, the connection between the collector of the first blue transistor and the base of the second blue transistor is missing; I have circled the place at which this missing connection should be visible...and is not. As there is no connection between the two transistors of the second pair of the push-pull, it means that the second edge of the sense pulse cannot be amplified. This omission is clearly intended as a clue of the fakery.  The missing connection between the base and the collector is certainly not accidental, for this mistake exists in two different schemas, one in a document dated 1966, and the other one dated 1972. 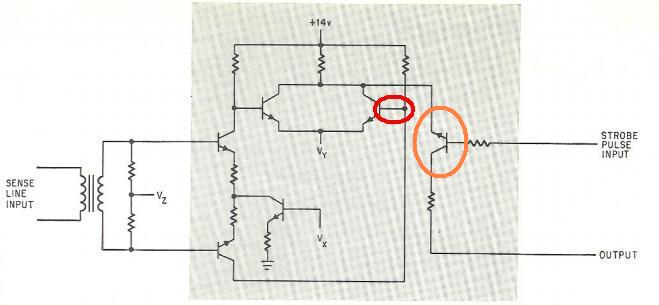 In an article published in 1967, Hopkins shows the schema of the amplifier, and, on this schema, the bug of the missing correction has been corrected; as the article of Hopkins has been published between the dates of the two documents in which the error exists, it shows that the argument that there might have been a decision of adding this connection or removing it does not hold. Hopkins corrected this mistake to attract the attention, to show that something was abnormal. However, Hopkins left the error of the incorrectly mounted output transistor.  About the incorrectly mounted output transistor, I initially thought that the strobe controlling the output was intended as an anomaly. This would have been true on the prototype card, which had up to 64 sense wires passing through the cores. Indeed, as there are 16 bits to simultaneously read, that would make 64/16=4 sense wires per bit.  As the sense line selection was allowing to select one in four sense lines, it then means that the selected sense line would have represented one bit of the 16 bits word to read.  And the diagram to read a bit of the 16 bits word to read would have looked like this. The sense line selection would have selected one of the four sense lines of the bit, the amplifier would have amplified it, and the output of the amplifier would directly have been a bit of the word. So, for the prototype card, the strobe would indeed have been useless, and its presence an anomaly.  But, in the final core rope modules, it is not 64, but 192 wires which could pass through a core, three times more than for the prototype card. That could make 192/16=12 sense lines for a bit. It means that what the sense line selection was selecting was not representing a bit, but one in three possibilities for the bit. For the sense line selection to select a sense line directly corresponding to a bit, it should have been able to select one in 12 lines.  Furthermore, as I have previously demonstrated, the sense line selection was reducing the current of the selected sense line to a third before it was coming to the amplifier.  For the final core rope module, the diagram for the acquisition of a bit of the 16 bits word would have looked like this. There would have been three sense line selection modules; each of these sense line selection modules would have selected one in 4 sense lines; each output of a sense line selection module would have come into an amplifier which would have amplified it, but only one amplifier's output would have been taken into account to represent the final bit, and the two other amplifier's outputs ignored, although they also were amplifying a selected sense line. So, for the final core cope module, the strobe finally has a meaning: It was allowing to specify if this amplifier's output would be taken into account to represent the read bit, or ignored. But, if the strobe is not finally an anomaly, the output transistor is still incorrectly connected. It is in fact upside down. 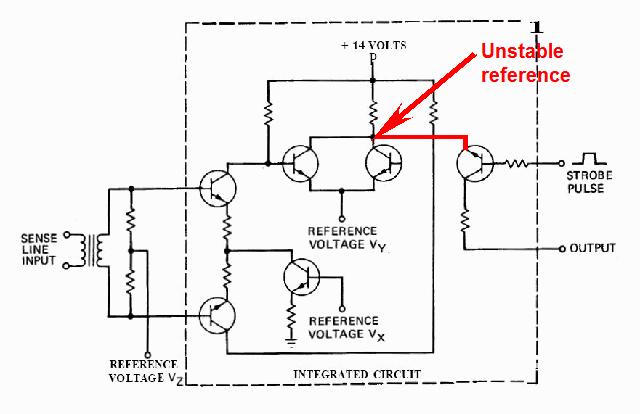 When a NPN transistor (emitter's arrow oriented outward) is used to validate or invalidate a signal by controlling its base, its emitter is connected to a steady reference, generally the ground; here, it is not the case, for the emitter is connected to the amplifier stage's output, of which the voltage changes when it amplifies a pulse. 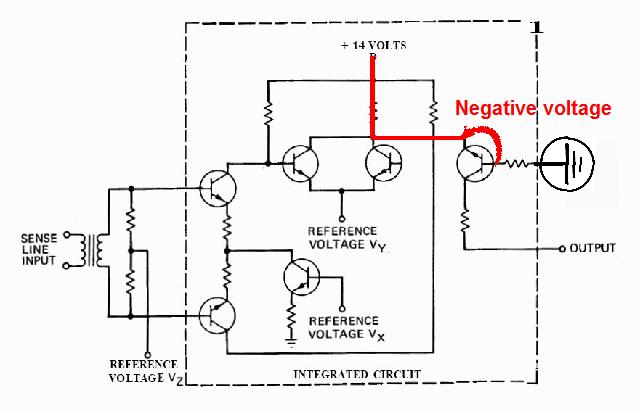 And, when the transistor's base would be grounded, and the amplifier's stage was not ampliying a pulse, it would have a negative voltage relatively to the emitter connected to the +14V, and it is not good for the transistor. 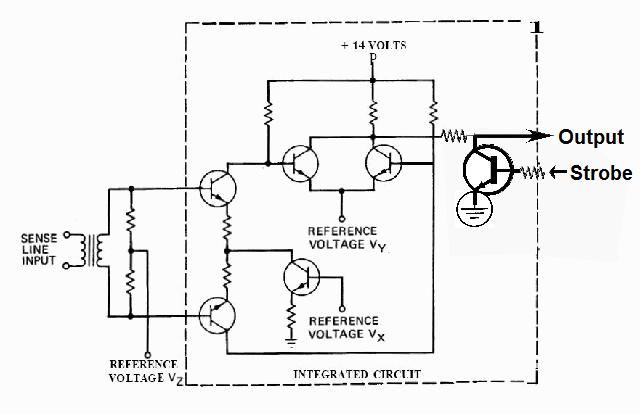 This is the way the output transistor should have been connected, with its emitter connected to the ground.  When the base of the transistor is activated, the output transistor would conduct, forcing the collector to the ground, and the final amplifier's output would then not follow the output of the amplifier stage, which means that it would not be selected to output the bit.  And, when the base would be grounded, the transistor's collector would then follow the output of the amplifier stage, which means that it would then be selected to output the bit. 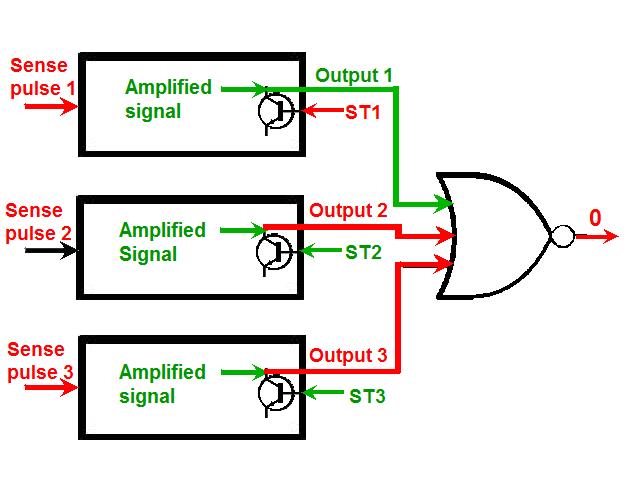 This simplified schema shows how the three amplifiers would be connected, so that only the output of one of them would be selected to output the bit.The outputs of the amplifiers would be inputted to a NOR gate; a NOR gate outputs a 1 when all its inputs are 0, and a 0 otherwise. For two of the amplifiers, the ones which are not selected, the strobes would be activated, which would force their outputs to 0, and, for the third one, the one which is selected, the strobe would be grounded, allowing its output to follow the output of the amplifier's stage; when there is no pulse, this output would be 1, forcing the bit output to 0.  And, when a pulse would occur, the output of the amplifier's stage would be pulled down by the pulse, and the amplifier's output would become 0, which would force the output bit to 1. So, if the missing connection between the base and the collector in the amplifier's stage is restored, and if the output transistor is correctly connected, does it mean that this amplifier would be correctly working? In fact, there still is another problem, though it is less visible.  This is the schema of the selection of a sense line, and its amplification, in a patent of core rope memory of a printer, which memorizes the dot matrix for a character to be printed. The cores, which represent lines of the dot matrix, are successively activated, and the sense lines, representing the columns of the dot matrix, are successively selected and amplified to print a dot of the character. About this amplifier, the patent says that it does not only amplify the pulse, but also stretches it. 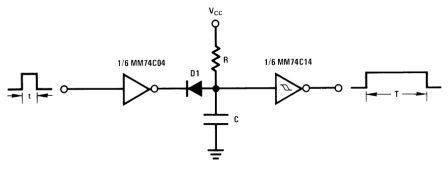 A pulse stretcher is an interface which allows to make a pulse longer, in order to exploit it more easily, to leave the time to read it. 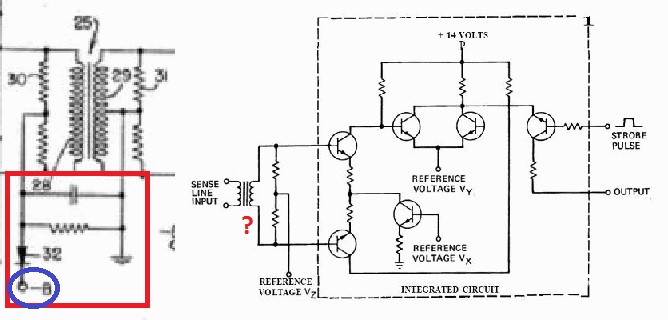 Now, look: The part I have framed in red on printer's bit amplifier is called a RC circuit (with a resistor and a capacitor), and it allows to convert the pulse on the secondary of the transformer into a temporary permanent current, which then can be read by the reading logic. After the bit was read, the state of the input I have circled in blue was changed, in order to discharge the capacitor, and allow the reading of the next bit. In the AGC's bit amplifier, this circuit is absent, which means that the pulse is not memorized on the secondary of the transformer, and all the transformer does is to transmit the pulse to the amplifier without memorizing it, and, as such, it is useless. If the pulse is not memorized, it cannot be read by the reading logic, for it passes too fast.  Now, why would the sense pulse need to be stretched? For the bit interface to correctly acquire the bit from the sense pulse, there are two conditions: 1) The sense pulse must already be activated when it is read. 2) The sense pulse must still be activated when it is read. If the bit was acquired exactly at the same time as the core is activated, it would not be acquired correctly for the sense pulse would not still be present.  That's why the process of the bit reading is made in three steps sequenced by timing: 1) Activation of the core 2) reading of the sense pulse 3) Reset  However, there is no guarantee that the pulse will still be active when the bit is acquired at the second step, in which case it would be read 0 whereas the pulse actually occurred.  That's why the pulse is stretched by the amplifier, so that the amplified pulse is certain to be present when it is acquired at the second step. The reset at the third step cuts the stretched pulse moreover resetting the core.  So, how would the interface of a bit have worked, supposing all the flaws I showed would have allowed it to work? There are 12 possible sense lines for a bit, but, for a given address, only one of these sense lines is to be taken into account. Let's suppose the first one has to be taken into account to output the corresponding bit. The first sense line selection module must select the first sense line; as the selection lines are inputted into the three selection modules, the two other selection modules also select the first line, but it is not relevant in fact, for their amplified outputs will not be taken into account. The strobes are programmed so that it is the output of the first amplifier which is taken into account; finally the output bit corresponds to the first of the 12 sense lines associated with this bit. 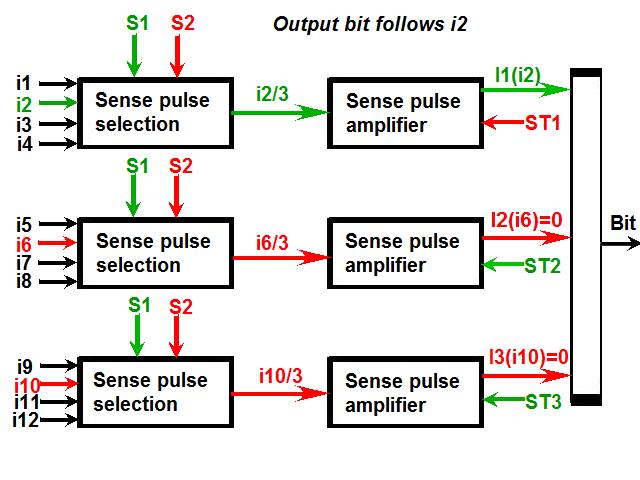 Let's now suppose that it is the second of the 12 sense lines associated with the bit which is to represent the bit. The first sense line selection module must now select its second input, and the strobes are still programmed so that it is the output of the first amplifier which is taken into account; finally the output bit corresponds to the second of the 12 sense lines associated with the bit.  Let's now suppose that it is the fifth of the 12 sense lines associated with the bit which is to represent the bit. The second sense line selection module must select its first input, and the strobes must be programmed so that it is the output of the second amplifier which is taken into account; finally the output bit corresponds to the fifth of the 12 sense lines associated with the bit. 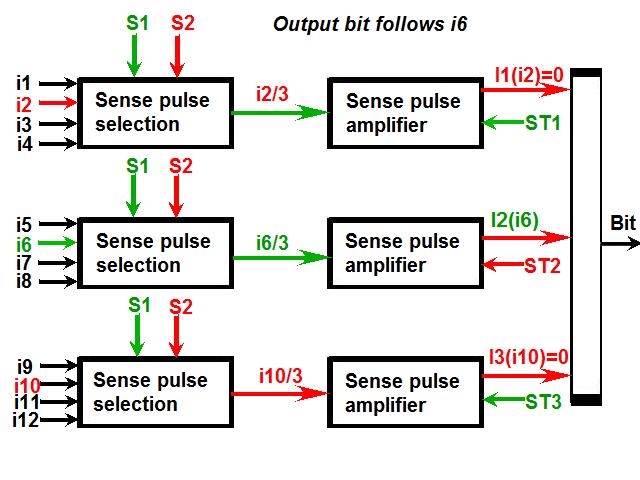 Let's now suppose that it is the sixth of the 12 sense lines associated wit the bit which is to represent the bit. The second sense line selection module must select its second input, and the strobes must be programmed so that it is the output of the second amplifier which is taken into account; finally the output bit corresponds to the sixth of the 12 sense lines associated with the bit.  I don't think I have to give more examples: Selecting a sense line is done by making a double selection: selecting a sense line selection's input, and selecting an amplifier's output. But, is this the best way for a bit's interface to work (ignoring the flaws of the amplifiers)?  I have only represented two commands to control the sense line selection block, for there only are four possible combinations to select one in four sense lines. It means that each input is inputted twice in the control of the selection interface; once non inverted, and once inverted. 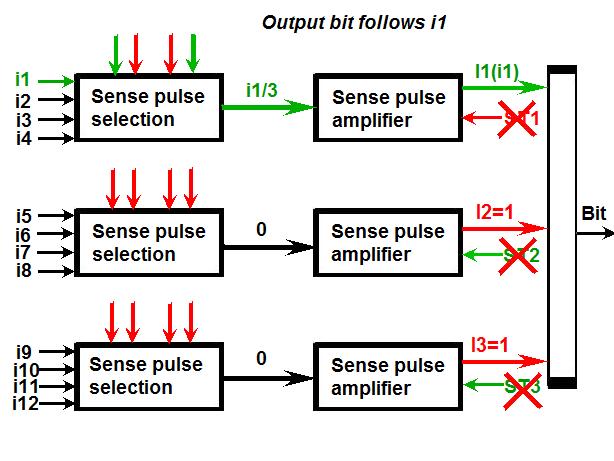 Now, it would be possible to control the sense line selection interface with four independent commands. It would allow to select several sense lines in the sense time, which does not offer the least interest, but it would also allow to select none of them, which means that no current would go from the sense line selection interface to the corresponding amplifier, and this is more interesting on the other hand. This might be interesting, for there would be no reason that a current would run through a sense line, and would be ampified, if the amplifier's output is not taken into account to generate the bit. But, in this case, it would mean that the strobes would be unnecessary. 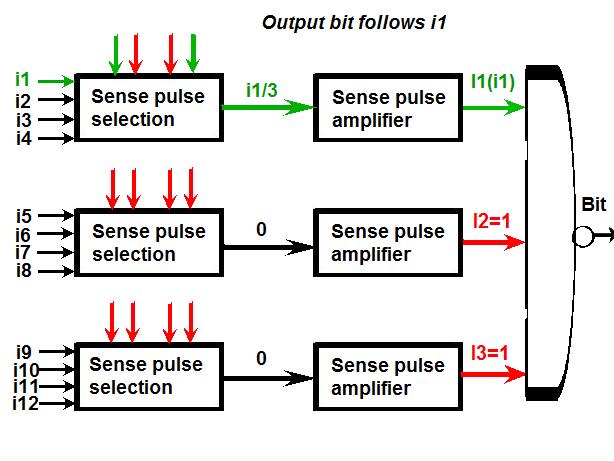 Indeed, since the corresponding amplifiers receive no pulse, their outputs will remain to 1, which means that the outputs of the amplifiers can directly be connected to a NAND gate, without being controlled by a strobe. The amplifier which receives a pulse, will amplify it and will output a 0, which will force the NAND's output to a 1. And, if the selected sense wire gets no pulse (i.e. does not pass through the activated core), the corresponding amplifier will output a 1, which will generate a 0 on the NAND's output, since the outputs of the other amplifiers remain to 1, as they receive no pulse, the output of their sense line selection interface being disabled. 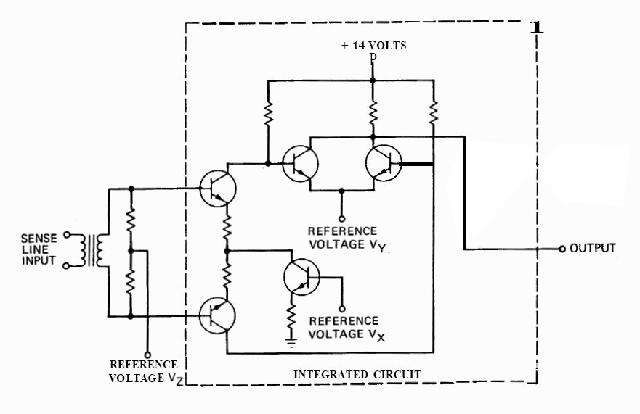 In short, it means that, if the sense line selection interfaces could be controlled so that they would select no sense line at all, the strobe which controls the amplifier's output would become useless, and the amplifier could be simplified as I show. But the strobe which controls the amplifier's output is here, and its presence proves that the engineers had excluded the possibility that the sense line selection interfaces could be controlled to select no sense line at all.  Now, let's consider again the selection and amplification of the sense lines of the printer's interface (and we can assume it has worked, it has not gone on the moon, it had no reason to cheat). Look how the selection was done: the selection commands (C1 to C5) were inputtted on the middle of resistors bridges, and the sense lines were arriving on the extremities of these resistors bridges; they were connected to the primary of a transformer through diodes; a sense line was selected by activating its command line, while the other command lines were grounded; only the sense line of which the command line was activated had a current running through it, provided that it was going through the currently activated core, and it is its current which was running through the primary of the transformer, without being reduced, and amplified and stretched by the amplifier which follows.  This printer's interface shows how the selection of the sense lines should have been made: There should have been a unique transformer, and as many resistors bridges as sense lines associated to the bit (12), as many command lines as sense lines to select; only one command would have been activated at a time, allowing a current to run through its associated sense line when it was passing through the activated core, and the current of the selected sense line would have run through the primary of the transformer without reduction; all the other 11 sense lines would not have had a current running through them, for their command lines would have been grounded; notice the capacitor connected on the secondary of the transformer, which allows to maintain the pulse after it has disappeared on the primary, and which leaves the time to read it; this capacitor is missing on the memory of Apollo.  For instance, if it is the first sense line which is to be read for the bit, only the first command line would be activated, and all the other ones grounded; the current of the first sense line would run through the transformer, entirely, without reduction, and would be correctly amplified and stretched by the unique amplifier of the bit, and the unique amplifier for the bit would have output a memorized bit, without a strobe being necessary.  And, likewise, if it is the second sense line which is to be read for the bit, only the second command line would be activated, and all the other ones grounded; the current of the second sense line would entirely run through the transformer, and would be correctly amplified and stretched by the unique amplifier of the bit. So, this is definitively the way the bit's interface should have worked, provided that we keep the logic of using sense lines for programming the bits. 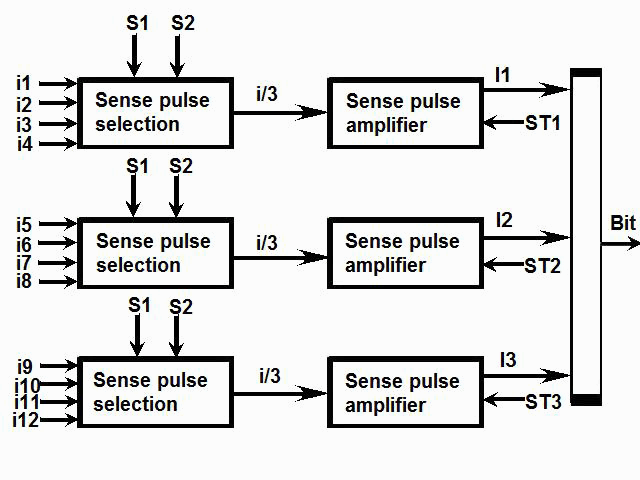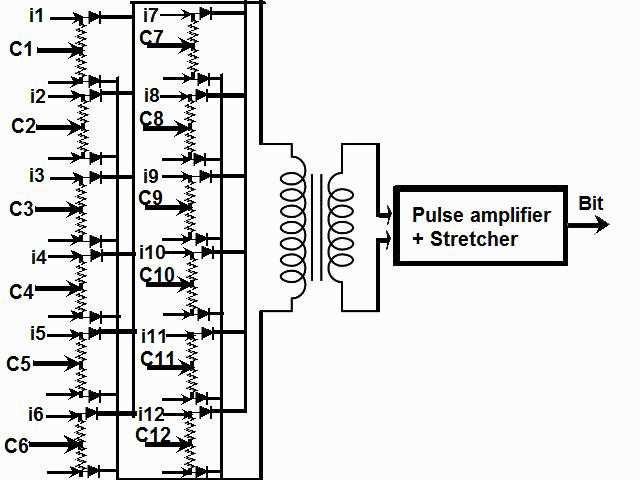 On one side, we have three sense line selection modules, reducing to a third the current of the selected sense line, and allowing three currents to run through three selected sense lines, three amplifiers, consuming currents, incorrectly amplifying the pulse, not stretching it, and incorrectly strobed, and, on the other side, we have a unique selected sense line, which is the only one which has a current passing through, which is not reduced before coming to the amplifier, which is correctly amplified and stretched by a unique amplifier which directly outputs the bit. No use to tell you which is the best of the two; If you are not completely stupid, you must be able to figure out!  And selecting the sense line for the bit does not require more bits from the address bus for the improved interface than for the AGC interface. Indeed, selecting the command among the 12 possible ones for the improved interface would be made with a circuit called "1 of N decoder"; it is a circuit which accepts a combination of n binary inputs and outputs 2^n outputs (Two n times multipled by itself), of which only one is activated at a time, which corresponds to the binary combination of the inputs; the displayed example shows how to validate one of the four outputs according to the binary combination of the two inputs.  Rather than showing a complete schema for a decoder having 4 inputs and 16 outputs, which would be a little overloaded to be legible, I show here an animation which shows how each gate of the decoder would be connected to the four inputs. This decoder would allow to select one of the 12 commands of the improved bit interface from a 4 bit address. It is not necessary to repeat this decoder for the 16 bits, the same decoder could be used for all the bit interfaces. And concerning the bit interface of the AGC, a two bit address would be needed to select one sense line out of 4 ones, and another two bit address would be needed to select one of the three amplifier's outputs, which would also make a four bit address at total. It means that the improved bit interface does not need more bits to be controlled from the address bus than the AGC bit interface.  Moreover, the inhibit lines were not even used correctly; the way they were used, there were two inhibit currents passing through a core.  If they had been used correctly, then only one inhibit line would have passed through each core, and would have been activated to inhibit this core, like it was made in the printer's memory, which actually works.  Moreover the fact that the inhibition process is incorrect (because of two activated inhibit lines passing through a core), using the inhibit wires like it was made in the memory of Apollo also implies that the inhibit wires also had to be woven to alternately go through or bypass the cores. And we are going to see that it complicates the weaving test. 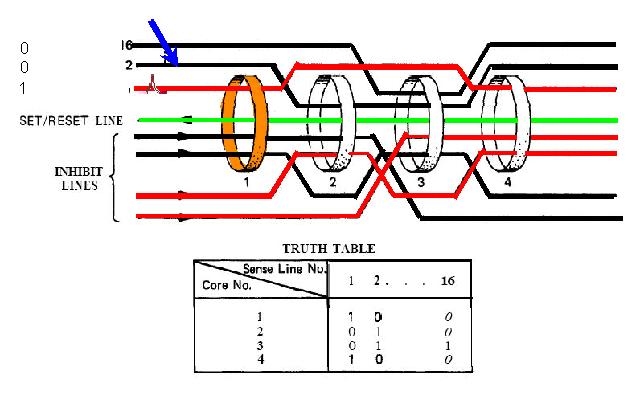 Let's consider the sense wire 2, I indicated with a blue arrow. This wire bypasses the first core (when it is correctly woven), because a 0 is programmed for this sense wire on the first core. So, when a current is sent into the common set line (wire colored in green), and counter-currents are sent into the third and fourth inhibit lines, as these inhibit lines pass through all the cores save the first one, they will prevent all the cores from being activated by the current of the common set line, save the first core which will thus be the only one to be activated. If the sense line 2 bypasses the first core, like it should, it will then show no current, showing that a 0 is programmed for this sense line on the first core; the detection of no current in the sense wire 2 will show it has been correctly woven.  Now, let's consider this situation. The sense wire 2 (indicated with a blue arrow), instead of bypassing the first core, passes through it instead, because a gentle weaving hand has made a mistake. The result is that, when the first core is activated (by sending a current into the common set line, and counter-currents into the third and fourth inhibit lines), it will show a current, when it should not. The engineers will then deduce that a gentle weaving hand has made this sense wire pass through the first core, when it should have bypassed it, and will have the faulty sense wire removed and woven again. 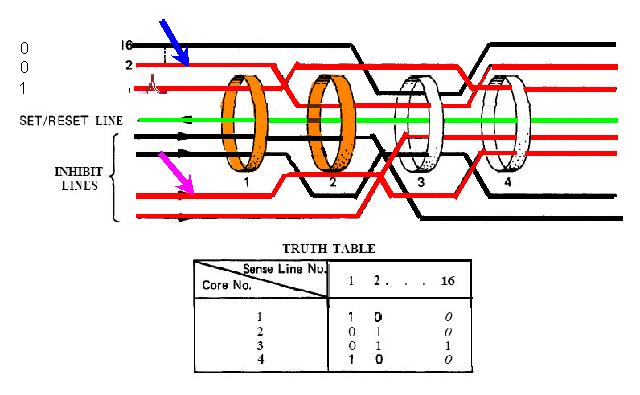 Now, let's consider this situation instead. The sense wire 2 (indicated with a blue arrow) has been correctly woven, and bypasses the first core like it should. But the third inhibit line (pointed by a pink arrow), instead of passing through the second core, bypasses it. The result is that, when a current is sent through the common set line, and counter-currents through the third and fourth inhibit lines, there will be no activated inhibit line passing through the second core, and thence the second core will be activated in the same time as the first core, when it should not. As the sense wire 2 passes through the second core, and that the second core is incorrectly activated, the sense wire 2 will be activated, not because the first core is activated, but because the second one is. If the engineers think that the inhibit wires are correctly woven, they will deduce that the sense wire 2 has been incorrectly woven, that it passes through the first core when it should bypass it, and will have it rewoven, whereas it is correctly woven in fact, for it does bypass the first core, exactly like it should. So reweaving the sense wire will not solve the situation. So, does this mean that, if the bit interface had looked like this, it could have worked normally, and that it is the way it should have been conceived? There is however a big difference with the printer's memory we have seen: In this printer's memory, the selection is made between all the sense lines which can pass through the cores; it means that there will never be more than one sense line that a current is passing through. In this bit's interface, there is only one current passing through the selected sense line of the bit, but there are 16 bits to read for the word to be read, which means that there are 15 other currents which can run through the 15 other selected sense lines corresponding to the 15 other bits (provided of course that they go through the activated core, which can happen). So, if this interface is used, it still means that there may be 16 currents running through selected sense lines (in the original interface of the AGC, it is 48), and 16 is too much, it implies a consistent reduction of current running into each of these selected sense lines (provided of course that they all go through the activated core, which may happen). It means that, although this interface is much more performant than the one of the AGC, it still has a severe deficiency to work correctly.  That's why the core rope memories of other computers than the AGC, like the one of the UNIVAC (right on the stereoscopic view), although they show a similarity with the core rope memory of the AGC, work in a completely different way.  Indeed, in these memories, the lines, which pass through or bypass the cores, are not sense lines, but drive lines instead, and that changes everything. In these memories, the cores have a unique sense wire. Indeed, the text associated with this figure, in the patent of a core rope memory for a computer, is as follows: "When the magnetic easy axis of the magnetic thin-film wire 1 is in the circumferential direction thereof, the magnetic thin-film wires 1 are used as information lines (which function doubly as digit lines and sense lines), and the conductor wires 2 are used as word drive lines." In the memory of the AGC, only one core is activated at a time, and currents can go through several sense lines, and, in the core rope memories which actually work, only one drive line is activated at a time, and several cores may be activated by this drive line at a time, generating a current into each of their unique sense lines.  Instead of being read on a unique core, the bits are read on several cores. With the same number of drive lines as sense lines, and the same number of cores, these memories can memorize the same number of bits, for, the same that a sense line programs a bit by passing through or bypassing a core, a drive line also programs a bit by passing through or bypassing a core.  So, if the core rope memory of the AGC was working according to the same principle as the core rope memories of other computers, which are proven to work, the schematics would be changed as I show here; the lines passing through or bypassing the cores would be labeled as drive lines, and not sense lines, and there would be no inhibit lines, which means that the latter would not have to be woven in the cores, unlike in the original memory of the AGC.  I explain here how it would work: The first drive line passes through the first and fourth cores, which means, that, when it is activated, the first and fourth cores would be activated, and their sense lines would detect a current, which would correspond to the four bit word 1001.  The second drive line passes through the second and third cores, which means, that, when it is activated, the second and third cores could be activated, and their sense lines detecting a current, which would correspond to the four bit word 0110. 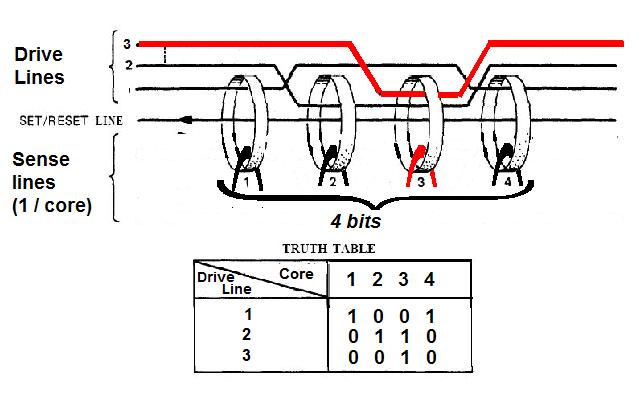 Finally the third drive line passes through the third core, which means that, when it is activated, the third core could be activated, and its sense line detecting a current, which would correspond to the four bit word 0010.  This demonstration has been made with four cores, but the number of cores for reading a 16 bits word would in fact be extended to 16, in order to read the sixteen bits of the word. So, you can see that this way of working is much better: 1) No need of inhibit lines 2) Only one current running into a sense line, which means that the current running through it would be consistent enough to be amplified. So, this interface is much better than... ...this one, which itself is much better than... ...the one which has been conceived for the AGC. This interface is so bad, it accumulates so many handicaps, that it has absolutely no chance to work, and the engineers knew it, for they wanted it to be extremely bad, and not to work. Now, to come back to the prototype card, there also is a problem of transport of wires visible on this card (which also exists on the final memory module). We have 256 inhibit lines plus the 64 sense lines, which makes a total of 320 wires to control this memory interface. The three connectors I have circled should be able to transport 320 connections, which makes 106.66 connections per connector; and, as a connection can't be fractional, that makes that each connector should have at least 107 pins!  The cover of the connectors allows to partially see the pins of the connectors; we can see three of them for each connector; we can measure the gap which separates them, and from it we can evaluate how many pins each connector has.  I have here reconstituted the pins of a connector by duplicating the three visible pins over the whole length of the connector; In my reconstitution, the connector has 19 pins; of course, there may be a margin of error, the connector may have a little more pins (or a little less), but we are very far from the 107 pins the connector should have, and even if there are two, or even three rows of pins, we are still far from the required number.  Furthermore it is difficult to believe that there are 107 wires in the bundle of wires coming to each connector!  The documentation of the NASA says that it was possible to insert 6 rope modules into the housing of the computer of Apollo. And also that each of these modules had 512 cores with 192 sense lines passing through or bypassing the cores, which makes a capacity of 98304 bits, and 98304/16=6,144 16-bits words, or 6K words in shorter. So, with 6 modules of 6K words, we have a total capacity of 6*6K=36K words, the memory that the NASA was claiming the ROM memory of the AGC had.  This is the exploded view of the computer of Apollo.  In this exploded view, we can see the bottom tray, called tray A, into which could only be plugged short modules, which was excluding the rope modules which are relatively long modules, and, above, the tray B, on which there was a window allowing to plug the rope modules, which had to be easily removed, for they might have to be corrected (unlike the short modules which are hard wired).  Here we can see the interior of tray A with the connectors for the short modules.  On this view, we can see tray B on top of tray A. Rope modules can be inserted on each side of tray B, but rope modules cannot be inserted on the bottom of the computer, because this bottom is tray A, and is reserved for the short modules; there is no room for the rope modules in tray A.  At first view, the tray B seems able to contain six rope modules (three on each side). Now let's see: For the two upper modules, we can see slots to insert them...But, for the lowest one, we can see no slot; without the slots, the lowest module will not be correctly maintained, will be loose.  On this photocomposition, I have added the missing slot on the right side for the lowest module that I indicate with an arrow.  On this illustration of Tray B alone, we see four connectors at the end of the tray. Someone said that there are already two modules inserted on each side of tray B...  ...But, on this close-up, we can see that: 1) These modules only have half the width (red arrow) they should have (green arrow). 2) These modules don't touch the frontal plates (orange arrow). 3) And on the frontal plates, there is the inscription "RETREAD" written upside down.  On this close up of the previous illustration, we see two rope modules; one is already half inserted, and the other one is not inserted. On the one which is not inserted, we can see the inscription "RETREAD", but normally, not upside down. And it is not because this module is itself put upside down, for we can see, by several details I have circled, that this module is not upside down. That means that, when a rope module is inserted, the inscription "RETREAD" should not be upside down. Some have said that what I show as gaps would be shadows...  So the black area I have circled in red would be a shadow on the module and not a gap? The shadow cannot come from the bar which is above, for we can see its shadow I have circled in yellow, and which is not even black, but grey! This shadow could only come from the frontal plate; but, for the frontal plate to create this shadow, the light source should come from the front of the tray, along the arrow I have drawn in red. But, if the light really had that direction, then the parts I have circled in orange on the right of the tray would not be shaded, and they are. Even if the light was coming from the right side, these parts would not be shaded; for these parts to be shaded, the light has to come from the rear of the tray... ...And, in this case, the frontal plate could not create the shadow we see! The Apollo believers have also told me that we could not see the edge of the module; this is only true at the beginning at the module; but, farther, at the place I indicate with a yellow arrow, this edge is visible.  I here show a close-up of the part I indicated with a yellow arrow on the previous figure. We can clearly see the edge of the rope module I indicate with a yellow arrow. So, the modules which are already inserted would have been inserted upside down, and would not have the normal width, only the half of it?  On a video, we seem to see six white connectors on the back of Tray B, which would show that six rope modules can be inserted, but first these connectors are misplaced...  ..And, second, on the left side of Tray B we can see only two slots to insert rope modules..  ...And, third, we see a rope module before Tray B, and it is obvious that it is not physically possible to put three of these modules on each side of Tray B; Tray B is not high enough. Notice too that we see no slots on the central plate. Now, the main point is that the rope modules of the computer had 512 cores and 192 sense lines, theoretically giving a capacity memory of 6K words. Now let's see if this rope module was really working with 192 sense lines and 512 cores!  We don't see very well the cores of the rope module everywhere, but we see them quite well on the bottom right of the rope module.  It is possible to count the cores of the rope module; there are 8 rows of 32 cores, which makes a total of 256 cores, and not 512. Where are the 256 other cores? And, if the sense wires are too thin to be directly counted, we have an indirect way to count them. Each sense line is indeed individually connected to a couple diode&resistor which allows to select it for reading (or not select it); these couples diode&resistor are indicated with an arrow on the top of the module and they are visible enough to be counted: There are 96 of them. 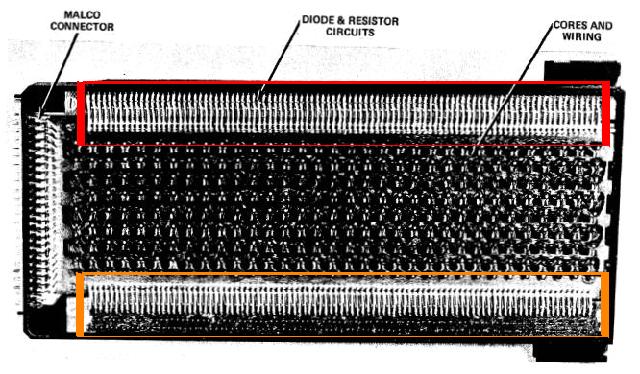 There should be 192 of them, so the 96 other couples diode&resistor must be on the bottom of the module!  We can see the diodes of the couples; I have circled one of them. Now, if we compare some couples of diode&resistor on the top of the module and on its bottom, we can see that they are different, when they should normally be identical! They are longer on the top than on the bottom; yet they should normally have the same length!  In fact, if they are different, it is because the resistors I have framed in red on the top of the module are missing on the bottom of the module; and, without these resistors, the sense lines connected to the couples diode&resistor of the bottom cannot be selected, and thence not used. Only the 96 sense lines connected to the couples diode&resistor of the top of the rope module can be used. Someone has suggested that the other 256 cores and 96 diode&resistor couples would be on the other side of the rope module.  Let's focus on the connector of the Rope module.  We can see the connector wholly, which shows that the module is placed under the connector; that means that the module is placed on the bottom of its case; there is no place to put core modules on the other side of the module, because a second layer of core modules could not be too close to the first layer, there should be a minimal separation between the two, and that would exclude placing the rope module too close to the bottom of its case.  And on the diode&resistor couples of the lower part of the module, we can see the diodes of the couples; it is the resistors which are missing, making the couples of the lower part inoperative. Only the sense lines are connected to diodes, the command wires are not. They would not have put diodes on the count of the 96 other sense lines which have no use, they would have put nothing; putting these diodes means that the lower part of the modules was supposed to contain the 96 other diode&resistor couples, but the latter have been made inoperative by removing the resistors. There are no diode&resistor couples on the other side. So, now, this rope module has only half the normal number of cores, and half the normal number of sense lines which are usable...and, consequently, its capacity memory falls down to the fourth of its advertised memory, so 1.5K instead of 6K words. So we now have four rope modules with a capacity memory of 1.5K words only, which makes a total capacity of 6K words; we are far from its advertised memory of 36K words; and eve, if six rope modules can be inserted, and that these six modules only have 1.5K words, it still makes only 9K words instead of 36K.  And the manual way the memory was woven makes no sense either: Rely on workers not to make any error! The weavers had to make wires pass through cores or bypass them 16384 times (for a memory card). That makes 16384 occasions to make an error! And if really they had made all the memory cards to memorize the announced 36384 words of memory, it would have made 589824 occasions to make an error! Well, or course, after the female workers had woven the memory, they certainly had a process to check if there was no error, but, if there was one, the card had to return to the factory to be corrected, and the corrections were awfully difficult (a faulty wire had to be completely removed and woven again - provided that they were localizing the faulty wire correctly and not confusing it with a correctly woven one!). And, if there were several corrections made in the ROM program, making corrections in the woven memory was a real nightmare!  So, there is absolutely no doubt that the core rope memory of Apollo was a joke and never intended to work.  So, when they baptized the core rope memory "LOL", it was not really meaning "Little Old Lady"...  ...But what it generally stands for, that is "Laughing Out Loud". It was clearly meaning this memory was a joke, and that it could not work.  Now some claim that the expression "Laughing Out Lout", abbreviated "LOL", has specially been created for Internet and was not existing before; so the engineers of the NASA could not have used it to baptize the core rope memory.  Nothing is more wrong: The expression "Laugh Out Loud" is far from being recent. An old cartoon "Laugh Out Loud cats" can testify of it; this cartoon was created around 1912, which proves that the expression "Laugh Out Loud" is far from being new. And it is very probable that this expression is even older than that. The creators of internet did not create the expression "laughing out Loud", they just used an expression which was already existing. 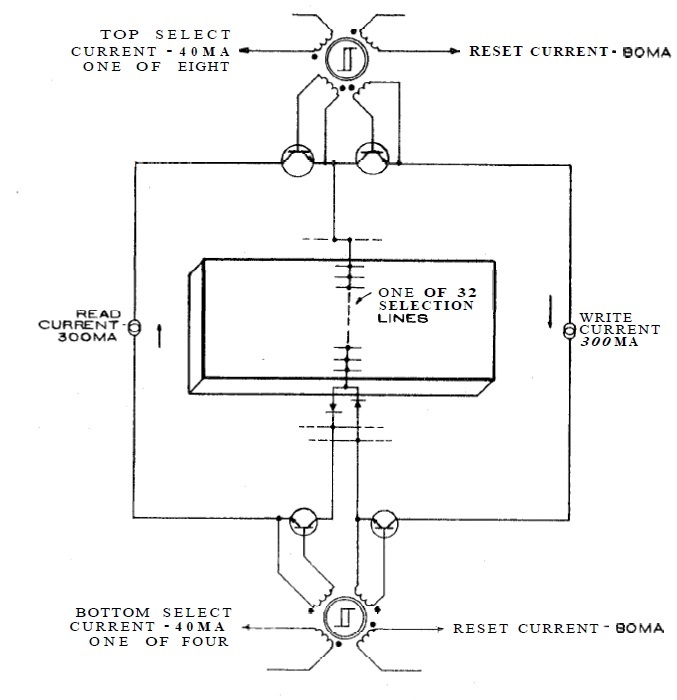 This is the simplified schematics of the erasable memory. The brick which is inside the loops of current represents the arrays of cores. If no core rope memory has ever been used apart for Apollo (at least the way it was designed for Apollo), such is not the case of the normal erasable core memory which can perfectly work. So, if the ROM memory of Apollo could not work, we could at least have expected that the RAM memory would have worked...But they have managed to make even the erasable memory not work!  I have represented in red the path of the write current; the current turns clockwise in the loop; this makes it go up in the block of the cores.  And I have represented in blue the path of the read current (the sense line); the current turns also clockwise, but, as it is on the left of the wite loop, this makes it go down in the block of the cores.  Now, what's abnormal is that the write current loop and the read current loop have a common part: it is the same wire which allows both to change the magnetic field of a core and also to sense the pulse which is generated by the change of magnetic field of a core. 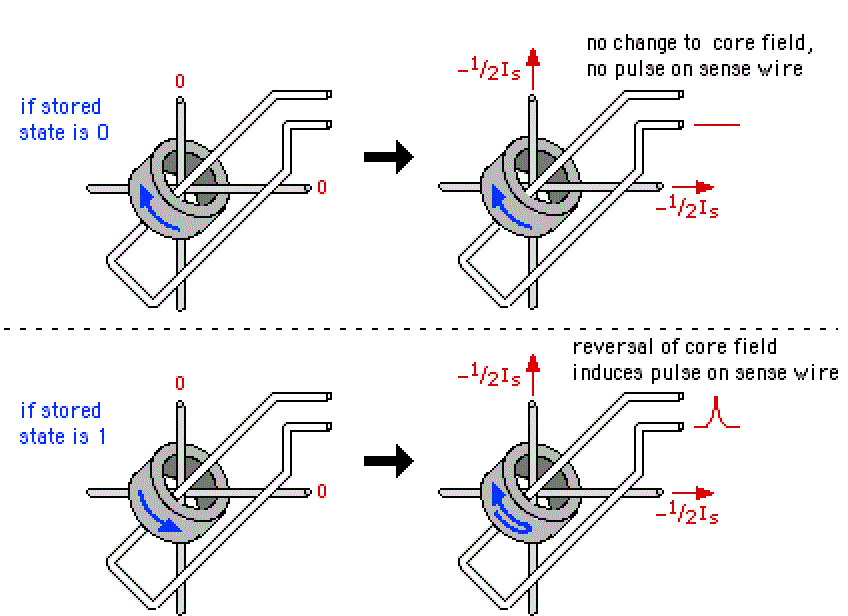 This is absolutely impossible: The wire which allows to generate the change of magnetic field of the core by sending a current into it cannot also get the pulse generated by the change of the magnetic field; this change of magnetic field has to be detected in another wire, called sense wire; the wire generating the pulse and the one reading it cannot be the same, NO WAY! And what makes it still more absurd is that the current of the write loop and the current of the read loop go in converse direction in their common part! 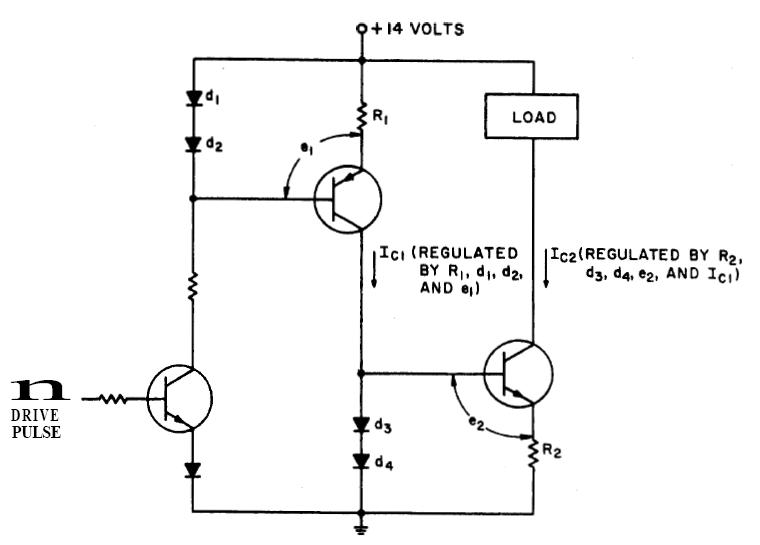 You might have thought that it was incoherent enough for the fakers to be satisfied? Oh no, they had to add some more salt! This is the schematics of the regulated pulse current driver which allows to read the sense pulse.  This interface contains two transistors (T2, T3) mounted in current regulator. The current regulation is based on the fact that, when a current runs through a diode, it generates a difference of voltage of 0.7 volts on the ends of the diode. When there is a pulse coming on the base of T1, T1 gets activated and the current can pass between the collector and the emitter of T1. Because of the double diode connected to the base of T2, the voltage on the base of T2 is then equal to 14-1.4 volts (2x0.7=1.4); the voltage on the emitter of the PNP transistor T2 is equal to the voltage on the base of T2 plus 0.7 volts, so 14-0.7 volts; this would generate a regulated current of 0.7/R through the resistor R. If T2 is activated, the current can go through its emitter to its collector, and also go through the double diode connected to the base of T3; the voltage on the base of T3 is then equal to 1.4 volts (2x0.7 volts). If the transistor T2 is activated, the voltages on its emitter and its collector should be equal, but the double diodes D1&D2 force the voltage of the emitter to 13.3 volts, and the doubles diodes D3&D4 force the voltage of the collector to 1.4 volts! It can't work, this interface is aberrant.  So, as incredible as it may seem, neither the ROM memory nor the RAM memory of Apollo could work. They both appear as a complete joke. But have no qualms for Apollo, Otto is here to manage the situation. |
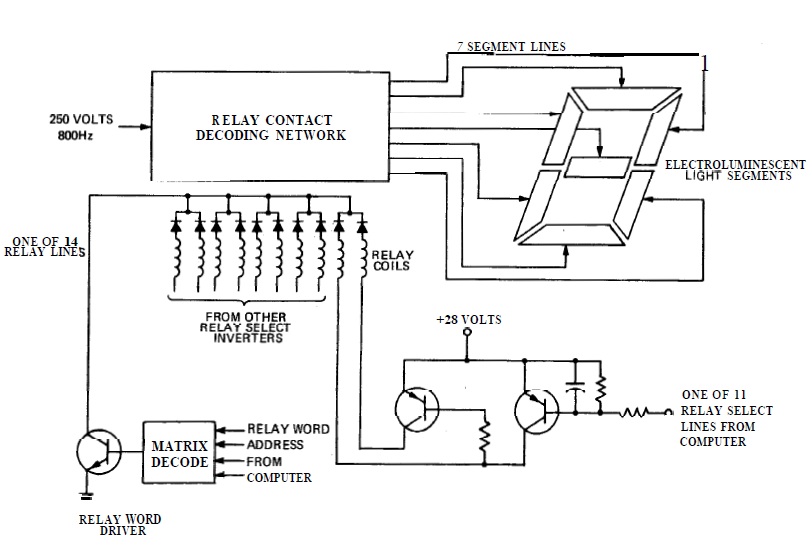 And, between the man and the computer, there was the DSKY unit, that is a display coupled with a keyboard. You might have thought that this unit was correctly working? NOPE! This schema shows how the display was commanded. 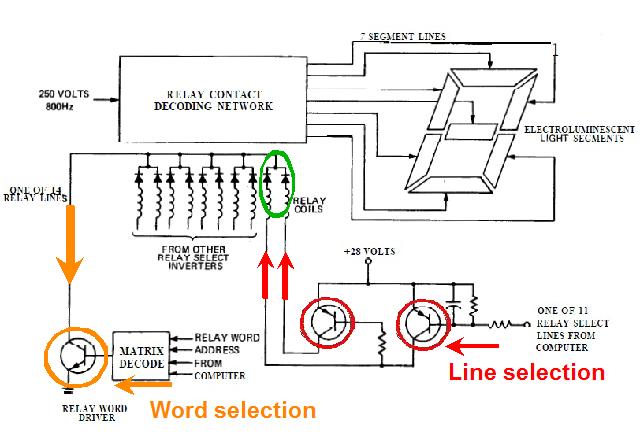 There are two commands to select a relay (represented as a spiral): - A word command which selects the digit which is to be displayed. - And a line command which selects a relay to be activated in this digit. In order to activate a relay, its line and word commands must be activated. When the line command is activated, the transistors I have circled in red are activated by the line command. A current then runs from their collectors toward relays, I have circled in green; but in order for this current to be running through the relays, it also must run through the transistor I have circled in orange, which one is activated by the word selection command. But, why are there two transistors, and two relays, when one would be enough? The argument is that it creates a redundancy: If one transistor fails to activate the relay through its own connection, the other one still can through its own connection. So, there are two transistors for each relay to activate, so that it still can work if a transistor fails. 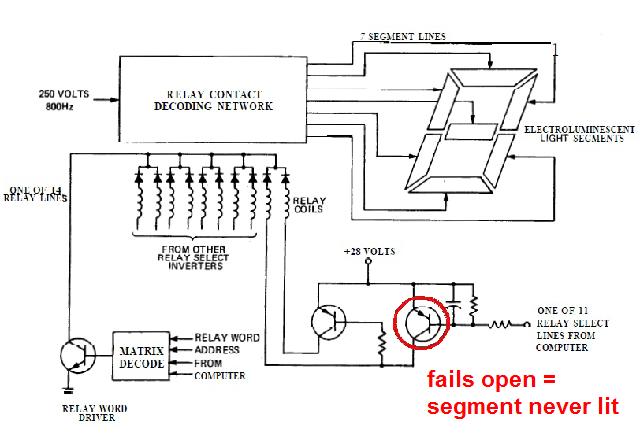 But, if the first transistor of the pair, the one I have circled in red, fails open, it will not activate the relay (when both the line and word commands of the segments selection are activated), but it will not allow to the next transistor to activate the relay, for the failed transistor also allows to activate the next transistor. So, in spite of the presence of the second transistor, the relay will not be activated. The redundancy does not play its role. 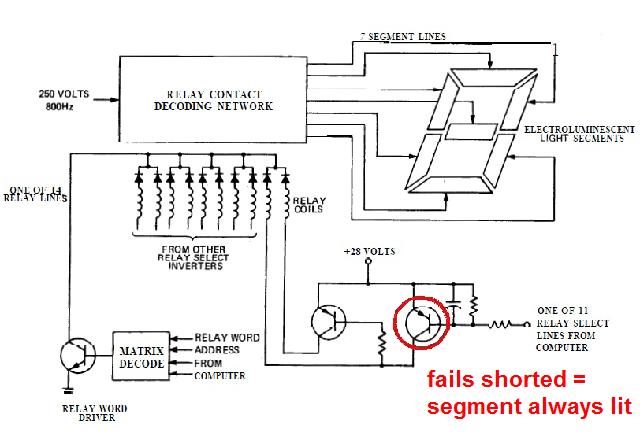 Now, if the transistor fails shorted, it will permanently activate the relay, even when the line command is not activated (but the word command is), even if the next transistor works correctly. Once again, the redundancy does not play its role.  And, if the second transistor of the pair, the one I have circled in red, fails shorted, it will also permanently activate the relay, even if the line command is not activated, even if the first transistor works correctly. Not only the redundancy does not play its role, but it even makes things worse, for there is more chance that one transistor in two would get shorted than a transistor alone. 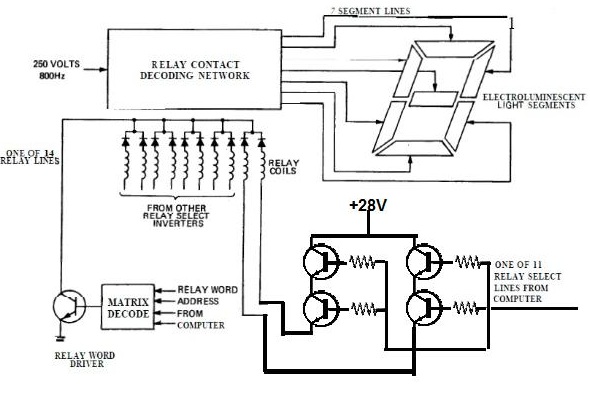 If they had wanted to make a true redundancy, they would have made it the way I show here: - If any transistor fails open, the other transistor of the pair can still correctly activate the relay, when the line command is activated. - And, if a transistor gets shorted, the other transistor of the pair, which still works correctly, will prevent it from permanently activating the relay. Now we have a true redundancy which makes that, if a transistor fails (but only one), the relay can still be correctly commanded, i.e. activated if the line command is activated, and not in the converse case.  Here, on the schema, they use 5 line selections which go into the relay matrix to light the segments of the digit corresponding to the value to be displayed. In reality, only 4 line selections would be necessary to display all the possible values of the digit (10 values for a numerical digit, and 16 values for a hexadecimal digit). So, only 4 bits are really necessary for the display of a digit, and also for all the digits, for it is the word selection which determines for which digit the current line selections apply. And, as there are 24 word selections to command (for the 21 digits and 3 +/- signs), it can be made with a command of 5 bits (the 5 bits are entered into a diode matrix which allows to produce the 24 word selections). 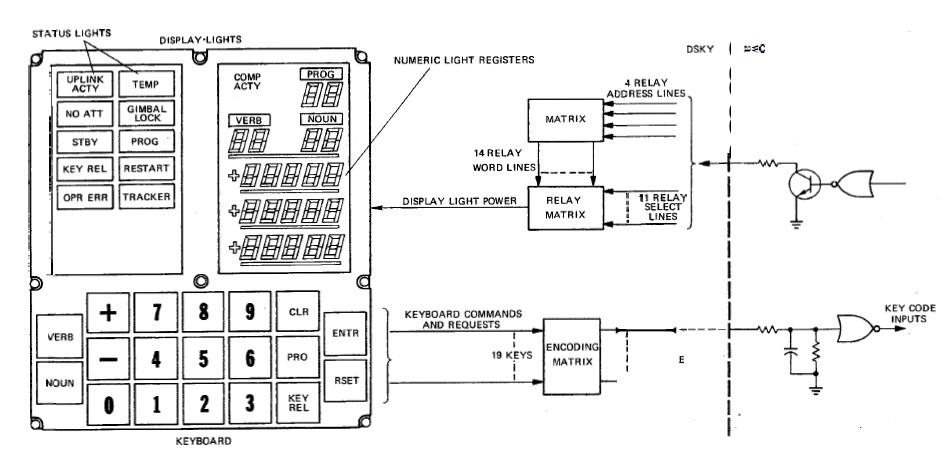 This schema shows how the DSKY unit was connected. 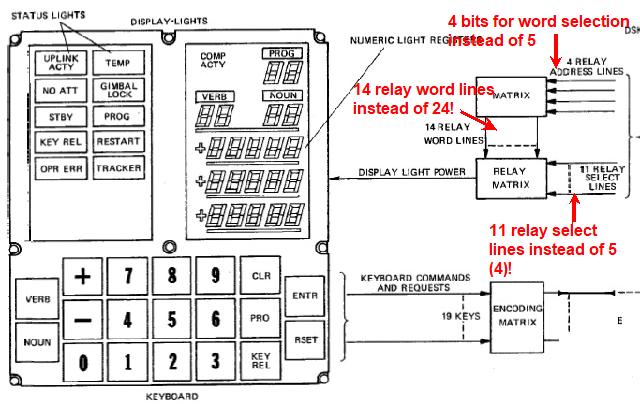 The word selections are commanded with 4 bits only, while 5 would be necessary, and the diode matrix outputs only 14 relay word lines, while 24 would be necessary (for the 21 digits and the 3 +/- signs). And there are 11 relay select lines, while only 5 would be necessary (In reality, only 4 would really be necessary). We here have a total incoherence.  But there are several problems in what is shown. First the collector of the transistor I have circled in red is not connected to a plus reference. So the relay matrix which follows will not be able to work correctly. And second, on the input of the inverter gate of the key code inputs, there is a feedthrough capacitor that we might wonder what it is doing here! If the user presses too fast the key, this capacitor could make that the input would be missed.  I have added a connection to a plus reference on the transistor connected to the word selection diode matrix input so that the selection can work correctly. But the problems of connection of the keyboard are not the only problems. The AGC was using an electroluminescent display on a dark background.  Your modern computers use modern displays like the one I show; in fact the displays you currently use are even more advanced than the one I show, for they are extra-flat, but I'll use this one which is more demonstrative. On this type of display, a beam sweeps a screen; the width and the height of the sweeping can be adjusted, and also its intensity; consequently, the size and the luminosity of the digits which appear on the display may vary.  But the the computer of Apollo was not using this technology at all for its display. It was using instead a much simpler technology, which had the advantage of being easier to command and much faster, which was important given its feeble power. The display was constituted of a series of "7-Segment" which could represent the digits to display.  This animation shows how a 7-Segment works: A 7-Segment is contituted of seven luminous segments (Hence its name); when a digit must appear, the segments which represent it at best are lit.  There is a special circuit which makes the conversion between a binary digit and the corresponding commands which must be sent to the 7-Segment to light the segments which represent it; this animation shows how this converter works.  A digit represented by a 7-Segment may be On...  ...Or it may be off...  ...But it can't be half on. A segment is either lit or off, but it can't be half lit. So a 7-Segment has two particularities that it is important to note for what follows: - Its size is physically determined, and absolutely cannot change - Its luminosity is also unique and cannot change (i.e. cannot become dimmer).  An electroluminescent display always uses a dark background, otherwise the symbols would not be clearly visible when they are lit; the symbols are faintly visible even when they are not lit.  This is the program of the AGC which displays on the DSKY.  In order to display on the DSKY, it should write into the channel 10. 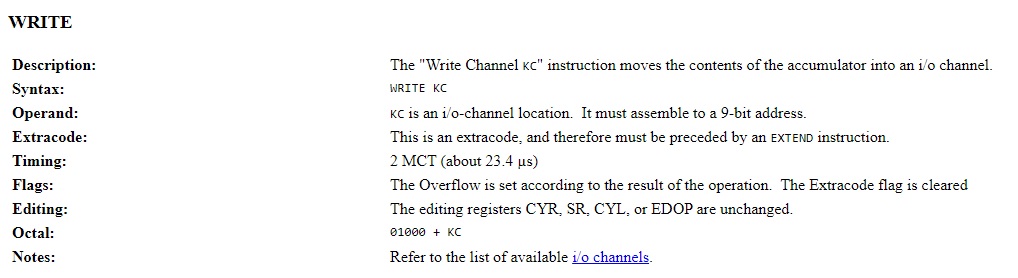 And, to write into an I/O channel, the instruction "WRITE" must be used.  But, in the display program, there is no access to any channel, and in particular to the channel 10. This means that the program does not even try to display on the DSKY.  So, as much as in the hardware as in the software, there are serious problems which make that the AGC cannot display anything on the DSKY. |
 In the mission Apollo 11, "Buzz Aldrin" (or rather the actor who pretends to be him) makes a demonstration of the AGC in the command module. Everybody has admired this sequence, supposedly showing that the AGC was perfectly working. Yet, it contains plenty of hints that it is fake.  In this sequence, we can see the electroluminescent segments all, or almost all, become suddenly lit. the verb 35 allows to make the light test which allows to temporarily all the light indicators and the electromuninescent segments.  In the virtual AGC, before the light test is started, the display looks like this; this is what we see in the sequence of the command module before the astronauts type "ENTR".  And, in the virtual AGC, after the light test has been started, the display looks like this; this might be what we see in the sequence of the command module after the astronaut has pressed "ENTR", though we cannot clearly read the display, because it is too blurry.  Before the astronaut presses the "ENTR" key, at the beginning of the video, the verb seems to display the value "35" which must have been typed by the astronaut before the video starts. So, it is logical that, when he presses the "ENTR" key, the light test starts and displays something which looks like what we see. Yet, there are some problems.  First, when the segments appear lit, instead of appearing all lit in the same time like they should, they appear progressively instead like this slowed animation shows; this whole sequence spans over a half second; it may not seem much, but, for a computer, even a slow computer like the AGC, it is enormous. If the AGC needs a half second to light some digits, then we may wonder about its capacity to guide the spaceship! Furthermore, whereas the buttons appear all lit on the left, during this sequence half of them go off to go on again a little later; where is the coherence in this?  Likewise, when the light test is stopped, the electroluminescent segments should go off all in the same time; but they also go off progressively instead, in a span of a half second too like it is visible on this slowed down animation.  And there is also another problem. On the keyboard of the unit, there was a key labeled "STBY" (for "StandBy", circled in red). Out of the standby mode, this key allows to proceed when an internal routine requests data, and tell it to continue its process, either with the entered data, or eventually no provided data at all. During the light test, there currently is no command to proceed with, since the "PROG" light is not on, and it goes on when an internal routine wants to take control fo the unit. So the astronaut has no reason to type the STBY key at that moment.  Yet, just before typing the next command sequence, I have caught the astronaut needlessly typing the "STBY" key. Here is the image I captured on which he types this key.  Now, we are going to get interested in the final sequence of the demonstration. This is an excerpt of this sequence. We see the astronaut type a command, and then data for this command. What is this command exactly?  The astronaut first presses the "Verb" key.  Then the astronaut pressed the "3" key.  Then the astronaut pressed the "7" key.  Finally the astronaut presses the "Entr" key, to finish the command, and take it into account.  What is this sequence exactly? According to the documentation of the DSKY, the sequence, Verb, 3, 7, and Enter corresponds to a change Major Mode sequence: its effect is to blank the noun display register, and to make the Verb display register flash; a two character major mode has then to be typed and the Enter key to be typed again. As the two digits of the new major code are typed, they successively appear in the noun display register.  I have circled in red the verb display register, and in green the noun display register.  Then the astronaut presses the 0 key, which corresponds to the first digit of the new major code; after having been typed, it appears in the leftmost digit of the noun display register.  Then the astronaut presses the 1 key, which corresponds to the second digit of the new major code; after having been typed, it appears in the rightmost digit of the noun display register.  Finally the astronaut presses the "Entr" key to take into account the new major code; you can see that the two digits of the new major mode appear in the noun display register, which shows they have been correctly typed.  When the computer activity indicator (circled in red) turns off, it means the computer has finished handling the command; at that moment, the documentation says that the new major code should be displayed in the Major Mode display register, that is the first data register (circled in green); but you can see that there is nothing in this data register, it is blank! A new hint that this demonstration is fake.  And there is a last hint that the sequence is fake. At the start of the light test, a lamp, on the left of the AGC (circled with red), goes on. At the end of the sequence, the astronaut lifts up his hand to press a button to switch this lamp off.  Yet, even before the astronaut lifts up this hand, as this slowed animation shows, the lamp automatically goes off, which means that the astronaut does not need to switch it off any more. Yet, he does not stop lifting up his hand, and uselessly presses the button to switch the lamp off. However, unlike the previous hints, this one does not show an incorrect behavior of the AGC, but just an illogical maneuver of the astronaut. So, this demonstration contains a succession of hints which proves it fake. You can notice that, in this demonstration, the background of the display appears dark.  Yet, on this photo of Eldon Hall typing on the AGC's keyboard, we can see that the background of the display of the AGC is unexpectedly clear, clearer than the rest of the DSKY unit; and we can see dark symbols on it.  Then someone showed me this photo of the AGC shown in the computer history museum which looks like the one shown on the previous photo.  But, the background of the display is light instead of being dark. And we can see no 7-Segment symbols on it, even faintly.  If it was an electroluminescent display, the display's background would be darker, and we could faintly guess the symbols on it. It rather looks like a liquid crystal display.  The liquid crystal displays started to appear only in 1971. In the start of the Apollo missions, they were still not existing, but, at the end of the missions, they were starting to appear, though their technology was not still ripe. This first version of LCD was displaying white digits on a black background.  Later versions of LCD display displayed black digits on a clear background. The first clear backgrounds were yellow, for the yellow was actually a filter in front of the display to absorb damaging Ultra Violet light and prolong the life of the liquid crystal material. However the technology of the LCD was not still well mastered in the beginning of the seventies. The slow response speed of early liquid crystals, and concerns about the life and temperature stability of the liquid crystal material held up its wide acceptance till the mid 1970s. That means that, if they had used a LCD display in the final missions, there was a high risk that symbols of the display could disappear, or become illegible; this was not acceptable in the Apollo missions, in which the safety of the display was so vital. In fact, the only advantage of the LCD display over the electroluminescent one at that time was its lesser power consumption; but it was at the price of safety!  The documentation of the AGC written by Eldon Hall, and dated 1972, clearly states that the AGC was using an electroluminescent display; nowhere it is made mention of a LCD display.  When I said to the Apollo believers that I was doubting that the displays shown on these photos had ever displayed anything, they showed me a photo and an animated demonstration with this type of display actually displaying something, and it is then that I understood the trick.  I was first shown this photo with a display which looks like the one which is exposed at the museum. It has intrigued me at first, and then I have found interesting things on it, that I going to explain.  First, if we compare this DSKY with the one of the video in the command module, it is absolutely obvious that the displays are very different: On the video of the command module, the background is definitively much darker than the rest of the AGC, and, on the photo the Apollo believers showed me, it is the converse. So what? Would have they changed the technology of the DSKY meanwhile? Now, the lit segments could be fake, they could be pasted over the display. Of course, you are going to tell me: Prove it! There are several clues which show that this photo is staged, and I am going to give them.  First clue: Let's focus on the part of the display I have circled.  See the horizontal bar of the '+' sign: It touches the '0' digit on its right; On an electroluminescent display, the digits are well separated and don't touch each other!  Second clue: On the left of the DSKY, we see the cable which connects it to the computer. Let's focus on the part I have circled.  The cable should go to the connector of the DSKY on its back; instead it goes to its front, and gets narrower; the way it is connected is totally abnormal.  Third, and most interesting clue: See the indicator I have circled.  This indicator is the "TEMP" indicator, and is the indicator which indicates that the temperature of the stable member of the IMU (the gyros) is out of bounds.  The IMU is essential to the spaceship, for it allows its guidance; if it was stopping working, the spaceship would be left without guidance. And don't think that the ground could guide the spaceship instead, for the ground also needs the informations of the IMU to calculate the position and orientation of the spaceship, which informations are transmitted via the MSFN. You might say: It does not prove that it could also happen during a lunar mission, for the AGC could have been running for a long time when this photo has been taken; I can't know how long it has been running when this photo has been taken. Oh yes, I know, and I am going to explain how I know it! The AGC had two timers counting the time, called TIME1 and TIME2; both were 14 bits counters. The first one, TIME1, was triggered by a 10ms clock signal, and so was counting hundredths of second. As it had 14 bits, it could count up to 2^14-1=16383; at the next clock pulse after it had reached its maximum, it was reset to zero and, in the same time, was triggering the timer TIME2; so the timer TIME2 was triggered every 16384 hundredths of second, or 163.84 seconds; it was also counting up to 16383. The two timers were equivalent to a 28 bits timer which could count up to 16384*16384-1=268435455 hundredths of second, or 2684354.55 seconds. Expressed in hours, it was making : 2684354.55/3600=745.65 hours; and in days it was making: 745.65/24=31.07 days, so just a little more than a month. It is way over the longest of the lunar missions. There were two ways of displaying these timers. The verb 16 allows to monitor data, that is to display data which is selected by the noun. The nouns 36 and 65 correspond to the display of the timers.  The virtual AGC shows how the noun 36 was displaying the timers on three lines: - The first line displays the hours. - The second line displays the minutes - The third line displays the hundredths of second. The virtual AGC is not clear about the way the noun 65 displays the timers; by reading it, one could think that the noun 65 displays the timers the same way as the noun 36. But, in that case, what we see on the photo would be wrong, for we only see two data lines on the display. But, what we see on the display is not incorrect, for the noun 65 displays the timers differently from the noun 36, as I have checked in the original documentation of the AGC. - The first line displays the hours under the form XXX.XX; in fact it does not display the decimal point, it just displays the double timer as hundredths of hours; it represents the integer division of the double timer by 3600, and it can go up to 74565. - The second line displays the seconds under the form XXX.XX; in fact it does not display the decimal point either, it just displays the double timer as hundredths of second; but, as five digits are not enough to display the double timer, the second line displays the value of the double timer modulo 100000, that is the remainder of the division of the double timer by 100000. it can go up to 99999. So, what we see on the display is compatible with what I said. There is a correlation between the two displayed lines that I am going to explain, and that we can check. the value 133 displayed on the first line corresponds to a number of hundredths of hours; to obtain the corresponding value in hundredths of second, we multiply it by 3600, which gives: 133*3600=478800 hundredths of second; but, as it changes every 3600 hundredths of second, the current value of the double timer is comprised between this value, and this value+3599, so between 478800 and 478800+3599= 482399; expressed in modulo 100000, that would make for the second line a value comprised between 78800 and 82399; now the second line displays 78812, and is thus in the expected range; thence the two lines are compatible; I would have expected otherwise, but I have to admit the compatibility of the two displayed lines. But, it at least proves something: the AGC has been running for 1.33 hours; the fractional part 33 does not represent minutes, it represents 0.33 hour; in order to know how much it represents in minutes, we must multiply the fractional part by the number of minutes in a hour, so 60*0.33=19.8 minutes, we can round it up to 20 minutes. So, we now have the proof that the AGC has been running for only one hour and twenty minutes when this photo was taken, and, in a so short time, the IMU already has temperature problems. So, now think: if the IMU already overheats after having worked for only a little more than a hour in an environment which is more open than in the spaceship, what will it give when it has to work for several days continuously in the more closed environment of the spaceship?  We have every reason to think that it has much chance to get out of order and to leave the spaceship without guidance!  The Apollo fans have also shown me an animated demonstration of this special DSKY unit. On it, we can see the digits change, so it cannot be, like I have suggested, something (like fluorescent tape) just pasted over the screen.  However, if we compare the display on this animation with the display in the video of the command module, we can see that the legibility of the digits is much much better in the video of the command module, because of a better contrast provided by a dark screen instead of a light one.  In fact, if we look close, the display on this DSKY unit does not look like electroluminescent segments at all; the contrast is very bad (it is always very good for an electroluminescent display), the segments are not clean, and, like on the photo. the horizontal bars of the '+' signs touch the next digit. It absolutely does not look like an electroluminescent display. But, on the other side, it looks like an image projected from a projector.  The animation was projected from a projector aiming at the display of the DSKY. Of course, I don't say it was this projector, and it certainly was not. And if the display does not have the good quality for an electroluminescent display (i.e. not dark enough)...  ...It had good reflective properties like a projector screen. These reflective properties were allowing it to reflect the image projected from a projector, what a black screen could not have done (you have never seen a black projector screen, have you?). Now, what elements do I have to support this theory?  At a given moment, during the sequence, we see them move back the DSKY unit a little. This stereoscopic view shows on the left the unit before they moved it back, and on the right the unit after they moved it back. (You can also see that the unit has moved back if you consider the holes on the top of the device which is on the right of the unit). But why did they move it back for? It was not to put the unit more into evidence, because, before, it was closer and entirely visible, so better placed for the demo at the beginning of the sequence than in the end. So there had to be another reason, and I looked for that reason.  Finally I found that reason when I noticed a flare which appears on the bottom of the image at the beginning of the demonstration. This flare is obviously created by the projector's beam, which allows us to know that the projector was placed under the image.  And so that there is no ambiguity, that this flare is not just a white spot, we can see this flare move on the image during the demonstration.  So, they moved back the unit a little so to obtain a better orientation for the projector's beam which would avoid this flare; and effectively we don't see this flare any more after they moved back the unit.  The fact of moving back the unit also allows to avoid the reflection of the projector's beam on the operator's hand: the photo on the left shows an image of the demonstration before the unit is moved, and the photo on the right an image after the unit is moved. The hand has approximately the same orientation on both images.  On these close-ups, we can see that the ring that the operator wears is brighter on the first image (i.e. before the unit is moved) than on the second one (i.e. after the unit is moved), despite the fact that there is a finger over the ring which should shade it. On the first image we can't see the relief of the ring, whereas we can on the second one.  There are other elements of evidence that the display we see is projected from a projector. By examining the sampled images one by one, I noticed a variation of the display between two sampled images. This is not very visible on this global animation...  ...But it is much more visible on this animation made with two windows of the display of exactly the same size and the same top left position taken on the two consecutive sampled images. You can clearly see that the "35" floats (not only in position, but also in size) on the display (notice the variation of the top of the digits relatively to the window which is above); this could not happen with an electroluminescent display on which the segments always keep the same physical size which cannot vary, and it undeniably proves that the display is projected.  In the middle of the light test, the digits of the verb and the noun (the two pairs of digits over the three data lines) suddenly go dimmer to go bright again (while the luminosity of the other digits does not change); this also cannot happen on an electroluminescent display on which the segments of the digits can be on or off, but not half on. This also undeniably proves that the display is projected. You may say; OK, but the operator has to press on the keys at the good moment, because, if he was not synchronized with what is displayed, it would show! Yes, but the operator knew in advance what he had to type, the scenario was prepared in advance.  There could be a slight shift between what the operator types and the display, but this problem was solved like I explain it here on this slowed down animation: The operator has to type a '6' in the sequence; he is a little in advance over the projected display; so he puts his finger before the '6' and waits for the 6 to appear on the display, as soon as the projected '6' appears, he finishes pressing the key; it just takes some fractions of seconds, so the viewer notices nothing, and thinks that it is the fact that the operator pressed the '6' which made the '6' appear, when it simply was in the projected sequence.  In order to well catch what the operator does at the moment that the '6' appears on the display, I have sampled the video faster than I usually do, that is 20 images per second instead of 10 images per second. I show here on this stereoscopic view two consecutive images of the sampled sequence; on the first one (left), the '6' has already appeared on the display; the operator immediately reacts by actually pressing the '6' key; but, even if he is very fast, there is still a little lag in his reaction, and that is why we see him press the '6' key in the next image (right).  It is not very visible in the stereoscopic view I have shown, but it is much more visible on this animation alternating the image on which the '6' appears on the display (labeled "BEFORE" in green) with the image on which the operator presses the key (labeled "AFTER" in red). If it really was the AGC displaying the '6', it could not appear on the display before the operator has pressed the key.  On this image extracted from the sequence, the operator uses a special technique to improve the synchronization between what he types and the display. Instead of using just one finger like he normally should, he uses two crossed fingers; he starts typing with the finger which is under; if the display changes, he then removes his hand, like what we see on the image, so that we can see the finger he used to type the key; but, if he is a little early on the display, he then uses his second finger, the one above, and makes believe he used that one to press the key. In fact, it explains why the DSKY had this type of display. It was effectively not a liquid crystal display, it was a display which had good reflective properties to display an image projected from a projector, so that the DSKY unit did not have to be a living unit and anything displayed on it could be simulated by projecting an image on it!  Now, the fakers gave several clues that this sequence is staged. 1)There is the "TEMP" indicator which goes on, like on the photo, after the AGC has run for hardly more than a hour and a half (since the first timer line displays 152, which represents 1.52 hours, so in fact one hour and 31 minutes), leaving serious doubts on the viability of the IMU.  2) There is also the "KEY REL" indicator which briefly goes on and off when the operator presses the '3' key instead of the "KEY REL" key (which is just on the right of the '3' key) which is related to this indicator.  Notice that this indicator looks like a hand with the forefinger stretched up. 3) And there is even a new clue which was not even on the photo! At a moment, they make display the timers with the verb 16 and the noun 65, like I explained before. The upper data line (the hundredths of hours) displays "00152", and the lower data line (Hundredths of seconds module 100000) displays "45723". 152 hundredths of hours corresponds to 152*3600=547200 hundredths of seconds. That means that the lower data line should display at least 47200 (between 47200 and 47200+3599=50799)...And it displays only 45723, so less than the minimal value it should display! And don't invoke a problem of refresh time of this display, for the difference corresponds to almost 15 seconds!  So, this time, unlike in the photo, there is no correspondence between the two data lines of the timer, and we have a fakery clue we did not have in the photo!  And, since I make a comparison between the two displays, look at the impressive difference of contrast between the two displays! The contrast is way worse on the animated sequence than on the photo. It is absolutely obvious that it is not produced the same way on the photo as on the animated sequence. On the photo, the display is not projected, it very probably hard pasted on the screen (may be with some kind of fluorescent tape, or a special pen). |
|
link to the video "computer for Apollo A presentation of the Apollo Guidance Computer has been made in 1965 by the NASA: "A computer for Apollo". It seems a serious demonstration, but in surface only. If we scratch the surface, plenty of anomalies appear. This presentation successively features Eldon Hall, Ramon Alonso, Albert Hopkins, and an engineering manager of Raytheon.  Eldon Hall first makes a presentation of how the spacecraft is guided.  He explains how the alignment with one star allows to make the guidance of the spacecraft.  By moving his hands, he illustrates how the angle between the star and the earth decreases as the spacecraft gets away from the earth. But he omits to say that this angle also changes if the spacecraft moves laterally without getting away from the earth.  In fact it is not possible to make the guidance by using only one star; we are in a three-dimensional system, and, in a three dimensional system, three references are needed; one of them is the earth, and the two other ones must be two stars, and far enough from each other too. So, by showing a schema with only one star used for the guidance instead of two, Eldon Hall intentionally misleads the viewers of the demonstration, who are not, for the vast majority, aware enough of the way the guidance of a spacecraft guidance must be done to notice the problem.  It is then the turn of Ramon Alonso to make his presentation. Ramon Alonso explains how the AGC works.  Alonso is the co-author, with Albert Hopkins, of a 1963 document which already contains a delirious information, with the description of a memory which does not work. I have given this document as the proof that the fakery started in Kennedy's time, and not after he disappeared.  Alonso first makes a demonstration of timers display on the AGC. But there already is a little problem. Which one? The first data line displays the hundredths of hour and the second one the five first digits of the hundredths of second. Later, the display has been changed to display the hours, minutes and hundredths of second on three lines, but, at the time of this demonstration, the display was still on two lines only. In fact these two lines have a relationship: By multiplying the hundredths of hour by 3600, we obtain a count of hundredths of second modulo 3600; that means that the actual count of hundredths of second is comprised between the product of the count of hundredths of hour by 3600, and this product plus 3599; this allows to make the relationship between these two lines. The first data line displays 9856 and the second line 80275. If I multiply 9856 by 3600, I obtain 35481600, and if I keep the 5 first digits, it gives 81600; that means the second data line should display a count comprised bewteen 81600 and 81600+3599=85199; yet it displays only 80275 and is outside this range. To conclude, Alonso shows a display which is illogical, impossible, and he does it intentionally. Notice also that the background of the display of the AGC is pitch dark. Yet, on this photo dated 1962, Eldon Hall is keying on an AGC of which the display has a clear background. This is contradictory, and intended as an incoherence.  The background of an electroluminescent must always be dark for a question of contrast.  The background of a liquid crystal display can be clear, because the digits can be black, but this technology was not existing in the time of Apollo.  Then Alonso uses the noun 57 to input desired angles for the alignment of the telescope. He inputs the angles in X and Y (they are in hundredths of degree). He inputs 180 for the X angle, and 325 for the Y angle. Is there a problem? Yes, there is a problem, because, in the documentation, they say that the maximum angle for the Y angle is 179.99�, and here Alonso has inputted 325� for this angle!  Then Alonso changes the direction of the telescope, from the initial orientation he has defined, by maneuvering it. At the end, we can see that he turns the reticle around the Z axis.  In fact, there are not only two angles for orienting the telescope, but three angles. There are the translation angles (X and Y) , but also the rotation angle of the reticle (Z), and this one should also have been provided for  Then, Alonso says that, by pressing a button, he can tell the computer to take into account the manual adjustment he just made.  Then, Alonso makes display the actual optics angles with the noun 56, and he says that observed angles are very close to the angles he has previously inputted. But, precisely, they should not be close! Alonso has maneuvered the telescope, and in doing so he has consistently changed the optics angles! So, they should show a consistent difference from the ones Alonso had inputted, and not be close to them!! Furthermore, the third line displays the time of the adjustment, and not an angle; it should rather have been reserved to display the third missing angle, the one in Z, the roll angle. In short, Alonso has just made a demonstration in which he has intentionally stacked absurdities!  It is then the turn of Albert Hopkins to make his demonstration.  Hopkins makes a brief presentation of the computer.  He makes a presentation of the arithmetic unic that he presents as an unit which takes operands from the erasable memory, performs an operation on them and places the computed result into the erasable memory.  But, if the operators I have circled in green effectively produce a result which can be placed into memory, the operators '>' and '#' ("greater than" and "different from") are comparison operators and do not produce word results like the arithmetic operators, but simply update status bits which are used to make conditional branches. They have nothing to do in the arithmetic unit. And, in what concerns the operator I have circled in yellow, it is a fantasy operator which does not exist.  Hopkins also explains that the inputs from other devices are directly stored into the erasable memory by a direct connection, and that words from the erasable memory are directly outputted to other devices.  But in reality there is no direct connection between the inputs&outputs and the erasable memory. The inputs and outputs should go into and from the central unit which manages them. The central unit reads an input into an internal register, but it is not obliged to put it into the erasable memory; it can directly perform an operation on this input without storing the original input and only store the result of the operation into the erasable memory. It can also directly output an input it has read without using the erasable memory. The central unit can also output a data it has computed in an internal register. To conclude, the presentation that Hopkins is making of the computer is incorrect, but he is making it intentionally incorrect. He could make a correct presentation if he wanted, but he does not want. The purpose is to show to the future generations that they have been taken as hostages in the fakery, and did not appprove it.  Then a Raytheon engineer makes a presentation of the way the AGC units are produced.  He shows a core of the core rope memory. Through this core, up to 192 sense wires can go through. It is absolutely impossible that all these sense wires could get a detectable current, even if they could go through the core. Furthermore, the way that the cores are activated, according to the documentation, does not make the least sense, for, instead of directly activating a core with a command line (or eventually two command lines bearing a half current each, like in the conventional core memories, which eases the selection of a core), they activate all the cores with a common activate line, and disactivate all the cores with inhibit lines, save the one which is currently tested. The result is not only an insane waste of energy, but also that plenty of inhibit wires must go through the cores; and these inhibit wires have a more important section than the sense wires, because they receive a more important current. It is just physically impossible all these wires could pass through a core, not counting the fact that it also does not electrically work. Add to this that the wires must not be naked, but sheathed!  Then the Raytheon engineer shows the backside of the computer, and we see a total anarchic mess of wires.  Furthermore, we don't have even the normal count of wires, for each memory card had 512 command wires and 192 sense wires!  Then the Raytheon engineer shows the workers making the sense wires pass through the cores or bypass them, according to instructions they have received. Thinking that a memory can be conceived that way is pure fantasy: 512*192=98304 occasions to make an error for each memory card. And making an error implies completely removing a sense wire to weave it again! If at least it could work! But not even! This memory had been nicknamed by the MIT engineers: LOL. And if, officially, it was meaning "Little Old Lady", it was privately meaning what it does mean for all of you.  Then the connections on the back of the computer were made with a rudimentary machine. When we see it work, we can have serious doubts on its capacities to perform a task as complicated as to make all the very numerous and precise connections which had to be made (on each memory card, there normally are some seven hundred connections - if we add the sense lines with the command lines!)  The informations for making a connection were stored on a punch card, one per connection. Given the huge number of connections which should normally have been done, it was representing a very important number of punch cards.  When we see how slow the punch cards were processed, it must have represented a hell of a time to make all the connections. We can wonder why the connection instructions were not rather stored on a tape.  Then the Raytheon engineer makes a demonstration of the way the AGC could be tested.  To start the test, he types the verb 50. But, in the documentation, they say this about the verb 50: "This verb is used only by internal routines that wish the operator to perform a certain task. It should never be keyed in by the operator" So, how could the engineer start this test with this verb when the NASA documentation says he should not use it? |
