|
|

|
|
|
October 1994 |
|
|
|
|
|
|
|
World Geotherapy Foundation Objects To further the transition to a benign technology for a Permanent Economy 1. Encourage the establishment of benign energy investment
both as demonstration centres and as commercial schemes. 2. Encourage the adoption of living on income (rather than capital) as an important
goal of economic policy. 3. Encourage the control of climate altering substances by:
Close the shop of argument and mystery; open the teahouse of experience.(2) # |
Introduction It is becoming a commonplace that the dominant world civilisation - the current complex of beliefs, assumptions and techniques - is based on unsound premises: capital can be used as income; oil and coal are infinite; the environment can be ignored when we put out gases and other compounds; when we throw something away it has gone. (see below - fossil customs)
By unsound the writer means that if it was a building we should say the foundations are weak and therefore it will fall down, especially after an earthquake. Since the publication of The Limits to Growth in 1972 there has been a flood of studies which imply that drastic changes to the western way of life are needed in order to avoid several kinds of catastrophe. It can be said that the human activities are destabilising the world's ecological system, to the extent of causing a planetary sickness. The remedies for this might be labelled Geotherapy(3)#.Probably the most urgent of the damaged systems is climate regulation for which there is now direct evidence of change(4)#, despite the disbelief of politicians such as George Bush (Senior, when written, Junior, now). A second important system is the Ozone Layer whose impairment can affect human health directly. More subtly the whole relationship between human activities and the energy and material resources of the planet is in need of correction if it is not to result in consequences we would prefer not to occur.
It is a major fault of human beings that we can compartmentalise ideas like this. One set of thinking processes can be well aware of the dangers, while the habits of living and thinking likely to lead to damage go on as though nothing was wrong. Tell someone they are going to die soon, and the news doesn't always reach every part of the person immediately. He goes on making plans for a later future. Perhaps this is how we should account for the administrative paralysis in the world. The politicians go on with plans that ignore the environmental evidence which has been building up for the last twenty or thirty years. The Free Market enthusiasts persist in building roads on the grounds that if people want to drive motor cars, they must have every facility to do so despite what it does to the world's climate system or the health of those who have to breathe the results. Perhaps it is because today's politicians have never learned the art and science of computer modelling which enables us to grasp the larger truths about the way the world works in a way not available to the ordinary experience. Many of them are operating according to the eighteenth century model of Adam Smith, which implicitly assumed resources were infinite. It is almost as though they are deliberately choosing to ignore modern models and preferring an out of date model, devised for a world very different from our own (about one fifth of the modern population, no use of mechanical devices or fossil fuels).
The official economists who advise these politicians don't use costing methods which will allow the environmental signals into the market. Al Gore observes(5)# that when calculating GNP the United Nations' economists still haven't got round to factoring in the value of topsoil lost by bad farming practices or the value of tropical rain forest lost, even though the same GNP figures include the value of the crops and timber produced. When he queried this, he was told that they might include environmental factors when they next reviewed the methods of calculation - in twenty years. Actually, as we are becoming aware, we haven't got twenty years to respond because the speed at which developments are occurring requires action as early as possible.
In fact there are some indications that several systems may have already overshot the limits(6)# - that is, there has to be a contraction rather than a slowdown of growth. This may be the case with the size of the human population, if it means that the present numbers are already greater than can be maintained without running the rest of the system down. "Overshooting the limits" of a system means that one or more factors of a total complex may outrun the other factors and result in general collapse of the whole system. If the human population is already larger than can be supported on the income resources of the earth many would die when the limits become effective, after the stored resources have been used up. One of the Club of Rome's modellers has stated a rule of thumb about the behaviour of complex systems with many interrelated components:
In any complex system, attack - however apparently intelligent - on a single element or symptom generally leads to a deterioration of the system as a whole.Forrester's First Law(7)# The Free Market advocated by such economists as Milton Friedman and his followers could only work efficiently without gross errors, even in their own terms, if the true costs(8)# of everything are paid by the user of resources. The Market Theory assumes that the desires of humans are the only sovereign basis for managing economic affairs. But if the desires are not modified by the possibilities and limitations of the physical world they can lead to trouble (sometimes the desires seem to be those of indulged children, who are not aware of the need to pay the bill - the actual level of consumption in some countries must be questioned and probably reduced.).
The signals of predictable resource depletion, or pollution build up do not at present influence the market. The "externalities" which economists have been in the habit of ignoring must now be paid for. The gases containing carbon and sulphur oxides which go up the chimney have a cost which results in crumbling buildings from acid rain, poisoned water supplies from metals dissolved into the lakes and rivers of northern Europe and the change in world climate which will cause immense social disruption and movements of population. The oil which is pumped out of the ground will not be available to future generations. The people burning it now do not pay anything to our descendants. This is important because if these things were labelled as Capital rather than Income even accountants, who have gained great influence over governments, would learn to treat them with some respect.
The results of our activities under "business-as-usual"(9) # may be rather horrific(10)#. Most of us know there is a problem, if only in the backs of our minds. Probably most people and politicians hope that the bad effects can be put off until after we are all dead(11)#. The disturbances of changing our activities may be quite extensive too, but if we were to adopt the necessary changes with a steady eye on what is needed, many of the changes can be foreseeable and can be dealt with by planning (but not by laisser faire). At the least what is needed is leadership of the kind which is conspicuously absent in such crises as the former Yugoslavia.
If we treated fossil fuels as capital, the price at the pump would have to be very high and we should stop using them for trivial purposes. Any fuel derived from any income(12) # process would then become cheaper. This implies a transition period during which the carbon taxes and capital asset fees would steadily increase year by year to allow the fuels to be phased out.
Could it be done? At present there are few signs that even a government composed entirely of Al Gores could introduce taxes of this kind at a rate sufficient to make a difference. However, taxation is not the only way of influencing people's behaviour. Nor are rising carbon taxes the only thing which has to be done; they are necessary but not enough. Some of the change must come from below by personal and collective changes of lifestyle. One problem with raising taxes on fuel is that it would only be effective in modifying behaviour if there are alternative fuels to use. These must be demonstrated before fuel taxes are imposed (unless they are of the form of the 1973 "Oil Shock" which had a useful, though unpleasant, effect, now wearing off after prices have fallen).
If petrol tax doubled now all that would happen is that people would go on using approximately the same amount but the cost of living would go up (even if other taxes were reduced to maintain fiscal neutrality - the government getting no more money over-all). People would use less of other things. What is needed is the possibility of doing something else than using fossil fuels.
One of these might be to encourage people to use public transport, preferably powered by hydroelectricity or some other non carbon-emitting fuel. Thus part of a motor fuel tax ought to be put into public transport to increase investment in non-polluting transport. The same is true of household energy. In Britain it was announced in the 1993 April Budget that VAT is to be put on gas and electricity. Most people will just pay the extra (spending less on other things) or suffer from cold houses. Some of the money ought to go on insulation grants. Some of it should go on investment into non-carbon fuels, including solar water heating. The tax, which in fact is merely a revenue earning device, ought to discriminate between fuels which deplete the world's capital and cause environmental problems, and those which don't. Thus income fuels should be exempt. At present the devices for solar and wind power are also taxed at the usual VAT rate (17.5% at the time of writing).
If we are to be faced with radically more expensive carbon fuels there has to be an alternative for people to escape into. Except for solar water heating and house insulation there seem to be no alternatives at present (even here the Free Market enthusiasts are advocating relaxing building standards so that insulation standards are no longer mandatory). How to change this so that the ordinary person can start getting out of a harmful energy structure? One suggestion is the building of actual examples of ordinary houses and living arrangements using sensible techniques based on sound assumptions (using no carbon fuels). Some of these have been built in Wales (NCAT(13)#) and other areas, where wind and solar energy combined with efficient design reduce fuel consumption.
The most important principle we need to adopt as the basis of a permanent human way of life is to use only energy which comes from current input: solar, wind, biomass, and the others. By now these need no introduction to most people. We have reached the stage at which most people know they exist, though people have the feeling that we can't afford them, or that they are the "energy of the future" - but a future which can be put off indefinitely(14)#. We need to reach the next stage at which everyone has to admit that on the contrary we can't afford the oil and coal-based system we are using now. If not now, when(15)#?
To change this perception what we need is some working examples of ordinary houses and settlements which use only income energy. We could call them Geotherapeutic Centres - a name to concentrate people's attention on the overall reason for behaving in this way.
The purpose of the Geotherapy Foundation is first to set up a number of of these Centres, as examples, and then to encourage their expansion so that the future world economy will be based on income resources. It can start implementing useful policies promoting geotherapy without waiting for legal compulsion. However, the aim is to make compulsion possible by demonstrating that ordinary life under a geotherapeutic energy regime(16)# is possible.
Technologies to be Demonstrated
1. Wind
By exploiting wind power first this activity can be self-financing as there are many areas where wind power is already profitable(17)# in competition with coal and other "conventional" fuels, even without carbon taxes. Geotherapy centres should be located in regions where there is plenty of wind. Among these are areas with convection wind systems - usually the most reliable. An example is the Rusinga area of western Kenya, and others around Lake Victoria; the California Altamont Pass is a successful example already developed. Other windy areas are those on the west coasts of Europe, such as western Ireland where wind power is as yet undeveloped. Wind has the advantage that developments in California have made it a conventional technology, with apparatus available off the shelf. It is not meant to imply here that wind power could supply all the energy needs of modern civilisation. It is probable that those needs must be reduced.
A useful feature of wind farms is that extra units can be added at different time. Unlike a nuclear station for example, there is no long period (up to ten years in the case of many nuclear stations) when money borrowed is not earning its keep. The actual construction time of each unit is very short. Each machine can start producing a saleable output as soon as it is erected and connected to the grid. Not all the units need to be owned by the same company.
2. Solar
Solar power from photovoltaics might be a major source of energy in the future. At present it cannot compete with carbon fuels when capital is treated as income. If coal and oil had to be priced as capital, and if their price also had to include the cost of climatic change, photovoltaics could probably compete already. Almost certainly there are reductions in costs available through research. So far, research into photovoltaics has been prompted by the space research program, where watts per kilogram is the main interest. For terrestrial use, research needs to be aimed at dollars per watt. Even so, the cost per watt has been greatly reduced in the last twenty years (1970 - $150 per watt; 1990 $4.50)(18)#.
Solar energy can also be used for water and space heating in areas surprisingly far from the Equator. (Even in Stockholm solar water heating can make a useful contribution to domestic energy.)
3. Biomass
In tropical areas biomass is an especially important source of income energy. It is a store of converted solar energy captured by plants through photosynthesis. It can be released through anaerobic digestion to produce biogas and fertiliser. Alcohol systems have also been advocated, though when the process is analysed as a whole its efficiency is seen to be rather less than in biogas because the energy used in distillation tends to exceed that of the final product.
The traditional biomass energy system has been firewood and charcoal. While the human population taking these fuels was small this was an acceptable system and could be managed so that no more was taken than the forest produced. At present there are many areas where humans are taking wood faster than it grows. The forests disappear. Pressure to use the land for growing food also competes with firewood. This is an example of overshooting the Limits. There are parts of India where there have been reports of people eating raw food because of there being no fuel to cook with. The use of biogas as a fuel is not the complete cure for this: in India there is a tendency for the owners of biogas plants to take the kind of fuel which the poor would otherwise use. This tends to suggest the need for social as well as technological change.In densely populated areas there are temptations to burn cow dung as fuel, which means that soil nutrients are interrupted in the cycle. Nitrogen and other plant requirements go into the air and are lost. Can extensive use of biogas make better use of this useful substance? Yes. Can it prevent people going without fuel? No. Only better social arrangements can do that.
Other biomass energy systems have been proposed. The growing of oil seeds may have a future, as well as some arid area plants which have a hydrocarbon sap. However, whereas biogas can be used to treat the waste stalks which have already provided food, oil seed plants tend to replace food. In an increasingly overcrowded world it is unwise to use energy systems which might deprive people of food. In Brazil alcohol crops (cassava and sugar cane) have had priority over food. Many are hungry.
Fossil customs
The need for legal and social change
One of our major human problems is that many of our customs and laws were developed during periods when the world population was a fifth of what it is now. Our habit of throwing things away was developed when most of what we used was either compostable or could otherwise blend with the natural world. Wood, clay, leather and bone implements could be thrown away safely; plastics and other complex chemicals can't. In places where these have been introduced recently they can be seen littering the countryside. Even in the industrialised world plastic waste is a serious problem. Attempts at making manufacturers responsible for the disposal or re-use of all non-compostable products are at an early stage.The habit of using firewood was fine when the woods were vast and the people were few. The use of carbon fuels at a small rate would be acceptable if the output of gases were no greater than can be absorbed by biology.
Even the prized habits of individual enterprise and completely autonomous companies were developed in a different society from the one we have now. Can they cope with a world of limits? Even in the United States there are signs that the economic structure - autonomous corporations with anonymous ownership - adopted to develop what seemed to be an empty country with unlimited resources no longer suits a densely populated country which is pressing up against the limits of several key resources. But managers and owners of large industries still resist legislation to control their outputs of non-biogenic substances, usually arguing that these regulations will interfere with the rights of free enterprise. The industrial states as a whole have not yet recognised that the power of industry to affect the world's climate requires a whole new layer of regulations reflecting the ecological obligations of industrial activities. Better than regulation might be a sense of ethical responsibility to the condition of the world as a whole.
The advocates of the Free Market often seem to be the people who deny the need to do anything about global problems, or assert that the Market will solve the problems, or even that there are no problems to be solved. This is probably a mixture of rationalisation and self-interest. Rationalisation usually occurs when people are aware of some problem but are afraid of facing it. Self-interest is the result of lack of perspective. It is in the interest of the human community as a whole to tackle the problems of climate change and biological degradation. If a company is making money by failing to deal with its waste products appropriately, they will often react by PR campaigns to try to persuade government that either nothing needs doing, or that the wastes are not harmful or that the wastes come from somewhere else. That is, the owners and managers of industries behave as though they are detached from the rest of the world. This seems to show that the radical application of market competition may not be appropriate when dealing with such large world problems as we are facing. The failure of the market economy to provide work for all members of the community is another weakness, which is seldom faced honestly. Does the Japanese type of economy show more sensitivity? Judged by Japanese businesses' behaviour in the rain forests of south east Asia and their style of fishing - hoover everything up - they are as limited as western businesses.
In the non-industrialised world many of the habits are also appropriate to a time when populations were much smaller. Thus in Kenya a large scale charcoal industry is supplying fuel to people in urban areas, at a cost of rapidly removing the forests.
Token obligations accepted by the industrial countries at the Rio Conference have not yet been implemented in the form of real changes in policy.
Legal frameworks
The Foundation should campaign for a legal framework similar to that in California(19)#, where income energies have privileged access to the national energy network. Specifically, suppliers of wind and solar energies, and from efficient sources using Natural Gas (Co-generation or Combined Heat and Power) can offer electricity to the public utilities owners, who must accept the supply, subject to technical safety and reliability. It can be shown that this policy in California has brought into being a large supply (several thousand megawatts) of wind and other income resources. This combines a legal policy of encouraging income energy with the market. This approach could be applied to many other environmental aspects of the economy.
Note on Nuclear Fission and Fusion
1. Fission
The Foundation will not encourage power from nuclear fission, on the grounds that it can't be a permanent source of energy, as fissionable minerals are limited in supply, but especially because the radioactive products of this industry are inescapable and affect the genetic material of all living things, including the humans. Moreover the industry cannot be separated from the danger of spread of nuclear weapons and the dangers of nuclear terrorism.
2. Fusion
The world already possesses a fusion generator in the form of the Sun. Research into making use of this well-shielded reactor should continue and seems more likely to produce usable power than the attempt to build fusion power reactors on earth.
Sites for Demonstration Projects
Wind sites.
There are numerous unexploited wind sites in the world. Lake Victoria in East Africa has several, including the Rusinga area of Kenya and Bukoba, Tanzania. Provided the financial arrangements are right and there is an electric grid system, wind power is already profitable and thus could be self-supporting. If carbon fuels were taxed with a world climate tax and a capital user fee, wind would become very profitable. It would spread more or less spontaneously as investors rushed to invest.Solar sites
Arid regions with frequent clear skies are also very common. At present photovoltaics are good value for small uses, such as irrigation pumps or pumps on remote pipelines. If the alternative is a diesel engine, solar photovoltaic generators are effective when the cost of bringing in diesel fuel or the cost of building a power line from the grid system is high. Examples are motorway signs in Saudi Arabia and irrigation pumps in Australia. At present photovoltaics cannot usually compete against grid power or diesel engines where diesel is easily available.Reductions in the price of photovoltaic panels have been occurring steadily in the last decade. Research into the techniques of building them may result in considerable reduction in the future. It is possible to imagine a time when photovoltaic power could compete against fossil fuels even without special taxes. In this case much of the world's climate problem might solve itself, and the sunny areas would become the world's power houses. (The Foundation might then be dissolved).
The main storage form of solar energy would probably be hydrogen. The Foundation will encourage research into making hydrogen a practical part of the world's energy system. At present experimental hydrogen vehicles are being tested in various countries(20)# and hydrogen can also be used to replace Natural Gas for some purposes. Hydrogen vehicles do not produce poisonous air pollution, so that they would be encouraged in California and other highly polluted areas.
Possible Energy Projects
1. Rusinga Island and Winam Gulf
Rusinga wind system
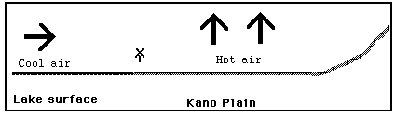
Fig.1 Rusinga is at the mouth of the Gulf of Winam (formerly Kavirondo).
Rusinga is an island in Lake Victoria off the coast of Kenya (now attached by causeway to Mbita on the mainland). It may be a good site for setting up a demonstration because it has one of the world's most reliable wind systems which in fact acts as a giant natural heat engine. The sun heats the Kano Plains, east of Kisumu, the air rises and pulls in cool air off the waters of Lake Victoria. This wind can power turbines. Potentially the area could have a wind industry as important as California's.
Fig.2 The Kano plains area is like a bowl. The flat plain is surrounded by an escarpment which undoubtedly has an effect on the wind direction.
A proposed training centre for the blind on Rusinga should have as one of its aims the use of local income energy sources for as many energy needs as possible. At the beginning these should be: lighting, cooking and water pumping. Income sources have the advantage that once a capital outlay has been made there are low expenses afterwards. This is the opposite to diesel engines where the initial cost is followed by a continuing cost for fuel and maintenance. Connection to the grid also entails continuing monthly bills.
There are three reasons for pursuing this policy. The first is that it is best for the Project to keep running costs low by using capital to invest in equipment. The second is the general world ecological problem which will require all areas to shift their energy consumption from capital (oil; coal) to income (renewables). We have to begin this process somewhere. All new projects in countries without indigenous fossil fuels ought to use income sources and so produce no burden on import bills, after the initial investment period. If they can be demonstrated as reliable others may adopt them. A third reason is the local environment. Increasing population pressure on firewood and charcoal is causing deforestation in many parts of Kenya. These must be replaced by other fuels if possible. In the possibly near future this shift may be forced on consumers by rising prices of carbon fuels from such devices as carbon taxes, or simply that the forests have been cut down. Oil products cannot be a permanent solution to the charcoal problem.
The Rusinga area has one of the best wind regimes in the world: a predictable convection wind - more predictable than the well-known Altamont Pass wind system where much of California's wind power is situated. There is solar energy as well. Even on cloudy days there is solar energy for both heating and electricity. These ought to be put to economic use as a demonstration of what can be done.
Mains electricity is available in parts of the area. If wind and solar power methods are adopted, connection to the grid would not be necessary, thus avoiding the need to pay a monthly bill. However, if a California(21)# energy regime could be established by which wind-derived power can be sold to the grid it might be worth having a connection, provided a wind generator could sell more power during the windy period (11.00-18.00) than is used at night, thus making a profit. (In principle, the energy supply of the centre would then be a mixture of wind power and hydroelectricity, as Kenya's main power source is the Tana river - at risk from droughts). The production of wind-powered electricity could become a major industry of the area and, under a California energy regime, could provide a useful income for landowners.
In the long run it is quite possible that industry and population will shift to those areas of the world where income energy is easiest to use. Such shifts have occurred many times in the past - admittedly in a world with far fewer people.
A Geotherapy plan on Rusinga should have two stages. The first is to demonstrate that a modern life, using modest amounts of energy (not at American level of consumption) can be devised using only income energy. The second is to encourage a major wind industry.
Demonstration Project
Energy for Domestic use and Blind Centre
1. Wind generator (size to be determined but at least 1 kilowatt)For all electricity needs wind would be suitable in this area. Wind blows regularly from approximately 11.00 to sunset all the year round. Calculations of likely needs should affect the decision on size of generator. Battery storage would be needed if there is no connection to the grid. The evening wind (reverse direction) is probably not strong enough to generate power.
e.g Bergey BWC 1500 watts. Cost: £2517 ($3775 imported from US to UK, therefore, better deal might be possible in US). Other costs for battery storage and control devices. (mentioned for comparison only).
This assumes that no wind energy will be sold to other users. If energy is to be sold a larger installation would be appropriate.
Battery storage
The capacity (and cost) of batteries for storage depends on the amount of electricity used when the wind is not blowing (night and early morning) or the sun is not shining. Thus, if it can be arranged to use such devices as power tools and washing machine only during time of maximum wind speed, storage need be only enough for evening lighting, TVs, computers and so on. For sites in Europe, storage must take account of days without wind and may have to store the power used on three or more days. In the Winam(22)# area this is not necessary as the wind blows every day.2. Wind pump. A standard wind pump can be used for pumping water from the lake. The writer is assuming that no part of the site is likely to be above the reach of a wind pump (10 metres). The water system, including a small purification plant, can be situated below a header tank supplied by the wind pump. There may be some scope for irrigation during the dry season, in which case a larger pump would be appropriate than would be needed for domestic needs alone.
3. Solar water heating. This is not as important as in Europe but would be useful for clothes washing and showers. A cheap system would be satisfactory. (A Gravity device without secondary cycle is adequate. Even a pipe painted black without glass or plastic cover might be sufficient.)
4. Solar electricity (smaller wattage as backup)
The wind doesn't blow for part of the day. There are uses for early morning power. Solar electricity probably remains more expensive than wind power but should be installed as an example for areas away from the main wind system and in anticipation of later developments (cheaper photovoltaics or possible carbon taxes).5. Biogas: A biogas project depends on the availability of suitable waste materials. Biogas is the ideal energy for cooking, if a supply of material can be found. Vegetable waste from the lake might be a source: reeds from sudd beds. Some animal waste is also necessary. If there is to be a chicken farm, a biogas plant is a natural adjunct. The chicken manure can produce gas, then be used as compost on a vegetable plot. If it is added to vegetable wastes such as reeds from the lake and crop wastes while digesting, there would be many advantages (lack of hydrogen sulphide; increased quantities of gas; soil conditioner). A biogas plant ought to be big enough to produce 10 cu metres/day. The temperature conditions on Rusinga are ideal for biogas - optimum temperature 25 - 30oc - so that the digesters are much cheaper than in Europe (no insulation or heating required). It would be necessary for the proposed Rusinga Agricultural Project and the Blind Training centre to be located on adjacent sites.
Training
Local people should be trained in maintenance of these technologies. In fact, there might be an occasion for running courses on energy at the practical level to encourage others to adopt these technologies. (Handbooks, audio tapes etc. in English and local languages).Using this power
6. Lighting: low voltage lights from batteries charged by wind and sun. Low voltage doesn't have to mean dim, but 12 and 24 volt DC equipment is convenient and available off the shelf. 24 volt is better, as cables can be thinner or longer. (1989. Now, 2002 I would recommend 240 volt apparatus, using an inverter, which is now cheaper and more efficient then then).7. Cooking: In Rusinga conditions cooking might be best done with biogas, but this depends on the availability of suitable material. If there is a large supply of biogas (10 + cu metres/day), all cooking can be done with it (provided the source is near enough to pipe the gas to the users).
An Electric Aga (as in NCAT Machynlleth). In a very windy area where wind varies in intensity the surplus electricity can be run into the Aga which is thus kept always warm. The capital cost of an Aga in Rusinga would probably not justify this method, so that electricity should probably not be used for cooking. In any case wind on Rusinga does not vary greatly.
Hydrogen
Hydrogen is potentially another system for cooking proposed for European projects, but the technology is still too expensive without a large grant from someone. Only when there are mass produced hydrogen generators will it be possible to use it for many of the purposes where gas and oil products are used today. When it becomes available cooking could be done with stored hydrogen. In the Rusinga area it is possible to imagine for the future that large scale wind projects might sell energy in the form of hydrogen for such purposes as road transport. (This depends on oil being taxed highly at the source, or unavailable).Charcoal
As far as possible firewood and charcoal should be avoided because of deforestation, unless a fuelwood plantation can be planted. However, population density rules this out in most parts of Kenya. Increased population density is making firewood an unacceptable fuel.8. Other Household machines
- Fridges designed to work off kerosene can be adapted for any heat source. Thermoelectric types (Peltier effect) are ideal to run off low voltage DC power. Neither type contains moving parts or CFCs. Kerosene fridges can be run off biogas. If there is a large enough supply, biogas would be the best source for refrigeration. Kerosene types may be available locally, new and second hand. Thermoelectric would have to be imported.- Vacuum cleaner, probably through an inverter, though low voltage types may be available.
- Washing machine This may be the largest power need and therefore the determining factor in the size of system. It would need inverter power and should probably be used only while the wind is blowing.
- tv & Computers can all be run off 12 or 24 volt supply either directly or with Inverter to 240v. The same is true of Power Tools.
Inverter
An inverter to run 240 volt AC apparatus wastes some of the energy in the process, so should be used only for those things which cannot be provided any other way. The size and frequency of use of the inverter might determine the number of batteries you need for storage. (now, 2002, they are much more efficient)In a large project it might be worth using 240 volts AC as standard and running all power through an inverter. An advantage is that standard wiring and sockets can be used in the buildings. However, the sockets are unlikely to be able to deliver all the power needs of a grid connected system. In Rusinga there is no danger of large heaters being connected, though electric kettles and toasters would also have to be excluded.
Batteries are an expensive part of the whole system, and must be protected# from going flat.
Transport
At present the capital required for running transport with income energy is probably beyond the scope of this project. Donkeys and sailing boats run on income sources. In the past sailing boats were an important transport means in this area. Probably only a high rise in oil prices would bring them back. Alternatives to motor fuel might be: alcohol, hydrogen, biogas. They would need to be the subject of a different project.Past Wind Work
There is a history of attempts to use wind in the Mbita area. They are described in the 1982 report of van Lierop & Veldhuizen. Despite a good deal of work throughout the 70s, by 1982 very little seems to have been achieved - in the sense that few wind machines had been installed. This makes one wonder whether this proposed project is likely to succeed any better. One of the purposes of an inspection trip is to discover whether any progress has been made since 1982.Failure, thinking about people
What are the actual reasons for the failure of wind projects so far? Is it that local people have seen no advantage in adopting the technology, or have had no opportunity to do so, that is, no access to capital? Or is it that even if one increases production with wind technology (with irrigation) there is no market for the increased production and so no increased sales? Or is it that people are still not interested in increasing sales? Van Lierop & Veldhuizen refer(24)#, obscurely, to "socio-economic" problems in the area south of Homa Bay as being prohibitive. The Nyanza area in general is classified as "of high potential"; however, the actual lakeside littoral is labelled as only of "moderate" potential for irrigation. This may reflect the fact that there is a rainy season so that non-irrigated agriculture is likely to be as important as irrigated (and perhaps people value the dry season as a time for other activities, which would be disturbed if they have to work through it).There is little mention of electricity in the report, perhaps because in actual competition with currently cheap diesel, and with grid power, wind was not seen as being competitive(25)#. But it may be that it is just that people have few needs for electricity, even if they make it themselves. The elite will use diesel engines anyway, if they are off the grid, as they have no other desire than convenience. An aim of developing wind electricity for geotherapeutic reasons may over-rule the current cost disadvantage(26)#, but it will not spread spontaneously until carbon fuels actually rise in price as a result of scarcity, or of world ecological policy, or if a California energy regime could be installed. There will always be a tendency for convenience to outweigh ecological desirability.
The failures tend to suggest that people's needs and desires are more important than technology. It is fairly easy to look at technology and see what is possible. It is much more difficult to find out what suits people.
Past efforts
The efforts seem to have concentrated on water pumping. During the colonial period the settlers imported standard American and Australian pumps and used them on boreholes in other parts of Kenya. These were mass produced and seem to have been quite satisfactory. A lot of the recent effort on wind power in the Mbita area seems to have been devoted to designing new types for Kenya. The writer wonders if this effort is justified? To attempt to design new types when the existing types are quite satisfactory is not a good industrial strategy and is rather like designing the wheel, when it has already been invented.Lessons for the Future
Now that in the 1990s there has been a lot of development in wind machines outside Kenya, both for pumping and for generating electricity, it would seem sensible to import tried and tested models and install them. Kenya needs to harness the wind much more than it needs a manufacturing industry. Only when a good base of installed capacity exists should a manufacturing industry be attempted. The signs are that the development of a new type of wind machine is not a job for village workshops but needs the sophisticated resources of aeronautical engineering. There is nothing wrong in leaving the design to those who can do it best. The situation is the same as for motor vehicles. No-one expects Kenya to develop a motor manufacturing industry at this time, but there is a huge amount of employment in servicing and repairing cars, lorries and buses which have been designed and built somewhere else. The writer recommends that if there are useful sites for wind the money be raised to import the machines, and people be trained to maintain them. The imports can be justified on the grounds that the energy they will produce is replacing imported oil fuels. (But will the government see it this way, even if they are paid for by aid money from outside?) This raises the question of the political stability of Kenya and the honesty of officials.
2. An Irish Project Why Ireland?
Ireland is the land from which civilisation spread back into Europe after the chaos which followed the fall of the Roman Empire. It is also the land with the best chance in Europe of living on income energy: it has a low population density, outside the two or three large cities (Dublin, Belfast and Cork). Its position on the edge of the Atlantic places it in the path of the westerlies, as well as the warm waters of the Gulf stream. The same ocean thumps huge waves on to the western coastline. If there were practical wave power devices much of western Ireland could generate an energy income. What if Ireland again(27)# developed the cultural resources needed by the rest of Europe, to save the world? In this case income energy could be saleable.
A Centre for Geotherapy There ought to be centres in every country to demonstrate that life is possible using only income energy. As in Kenya, the Geotherapy Centre should first provide a practical demonstration and then encourage large scale income energy projects.
Details
As energy resources are at the root of the general problem, there should be an analysis of the income energy resources of each country. Ireland, like Britain, has several potential income resources. Unlike in Britain they could be enough for all its needs, if they are developed. Wind and wave are likely to be the most important of these. Possibly some of the sea inlets or fiords might at some time in the future be used for tidal power.How likely is the Irish government to agree on an energy policy in which income resources have a privileged access? If it follows British example, not very. Britain under Mrs. Thatcher favoured nuclear power and short term market strategies which gave advantages to Natural Gas, or any other fuel which seemed cheap at the moment. Ireland has rejected nuclear power but otherwise depends on imported fuel: mainly oil. There have been tentative plans for a grid connection with Britain which would lead to the import of nuclear derived electricity. (If it came through Northern Ireland the terrorists may make it unreliable.) British wind power projects are a by-product of the high subsidy paid to the British nuclear industry.
At present the use of oil and LPG gas is increasing rapidly. Many of the modern bungalows spreading all over the countryside use LPG gas delivered by tanker. Oil for transport is also increasing. Except for the Natural Gas from the Kinsale offshore field all the hydrocarbon fuels are a burden on Ireland's balance of payments, and increase carbon dioxide outputs. A Green policy should certainly aim at making Ireland self-sufficient for energy and at the same time reduce carbon dioxide emissions to a minimum. This would be an example to the rest of Europe, which would admittedly find it harder to achieve.
A geotherapeutic strategy has to take into account the long term needs for energy and the effects on the world system as a whole. Thus only the income energies can be considered as benign in relation to the world's climate problems. In the case of Ireland, with few fossil fuels, there is the additional benefit of reducing imports by relying on locally based income energy.
Pollution
Reliance on wind, waves and tidal energy would reduce Ireland's output of carbon, sulphur and nitrogen dioxides, important components of the world's atmospheric pollution. Although Ireland still has some of the cleanest air in Europe, only if local emissions can be reduced will the air remain clean. At present Ireland's emissions are increasing, as the use of imported oil increases year by year. The cities already experience typical European air pollution.How to turn Ireland's energy policies towards income energies? A gradation of stages is possible.
1. Small demonstration projects to show that domestic size energy from income sources alone is possible. Some have already tried this(28)#. Domestic energy projects should include: wind generators, solar heating, high quality insulation; low consumption appliances, such as low wattage lamps, heat pumps,
2. Large scale industrial wind farms. Once ESB(29)# is convinced that wind is reliable, these should be profitable. Even without Britain's non-fossil fuel subsidy (intended to subsidise nuclear power) wind should be able to compete with carbon fuels, provided the price offered for wind power is fair, using the California rules (see appendix). Private participation in power generation is probably necessary. The west of Ireland is one of the best sites in Europe for wind power. So far the Irish government has done little to promote its wind energy. According to a 1990 book on energy policy(30)# Ireland has an even worse record than Britain with regard to energy conservation, controls on carbon emissions or environmental effects of the energy industry in general.
The same book indicates that Ireland could supply all its electricity needs from wind power and one day could even be an exporter(31)# of energy.
3. Wave power generators. The research and development into these will eventually produce reliable apparatus to harvest the waves beating on the west of Ireland coastline. How much power could these develop? It is still too soon to estimate but the amount may well be enough to export, perhaps in the form of hydrogen, if that becomes a serious proposition.
4. Hydro All the large scale hydro power sites are already developed (Ireland has few because the rivers are short and the mountains not very high). Small scale hydro is another matter as few sites have been developed.
5. Biomass
- Biogas may have some potential, but probably only on large farms. A monastery in the north has a large scale biogas installation(32)#.
- Firewood grown by quick growing trees has a scope too, especially as Ireland has less forested land than it should have - a legacy of past overpopulation.
Geotherapy Centre
The west of Ireland is the best area in which to start, as it is exposed to wind.
Tralee
The Tralee and Dingle peninsula area shows a good supply of wind (and rain). Other western areas are also suitable.
The quantity of wind suggests the possibility of a private project, certainly at domestic level. Options says that a few individuals (all in West Cork) have installed wind power.
Domestic Wind Project
Object: To demonstrate that in a windy area all domestic energy needs can be supplied from income sources of energy.
Property is cheaper in Ireland than in Britain (or was in 1990). A standard bungalow, rather larger than a £72,000 British model (more rooms, larger garden) seems to be costing about £52,000. Estate agents seldom display an asking price, usually putting "offers asked for". The figures the writer observed came from those few with a suggested asking price.Older property, presumably requiring extensive work can be had for lower prices. In the Tralee area a small cottage was asking £19,000, which might well have been in very poor condition and needing a great deal of work. But this suggests it might be possible to find a place not connected to the public services, as suitable sites for wind and solar power experiments. The writer was told that there is an aging population in the countryside. Most of the children have moved to the cities and when they inherit the property they usually sell it. This may tend to keep prices low. A society which relies on income energy may need to inhabit the countryside more and decentralise.
Solar water heating and other energy projects would be easier to install as part of a general refurbishment than in an existing modern house. (New Build of course is easiest, but the most expensive). Listed in the Yellow Pages there are companies who claim to install solar water heating. Whether there are local wind and solar electricity contractors is uncertain, but there are some names in Options of Architects in Cork and Dublin who use solar principles in design. Insulation suppliers in Dublin. Wind suppliers in Donegal, Heat pumps in Clonakilty (Cork), Biogas in Coleraine (N.I.). The list is rather thin.
The writer saw a shop selling organic produce in Tralee(33)# and asked about the supply of organic vegetables. As in Britain, the demand is greater than the supply and there are few local growers. Some has to be imported, probably not from Britain where there is the same problem. This may tentatively suggest a source of income. Another source may be in visitors, especially if they can be offered something different: all energy coming from wind and sun power, plus organic food. There are a few New Age establishments advertised in the area along these lines (though the writer didn't see any mention of solar or wind energy.
Earthwatch say a National Centre for Alternative Energy was proposed (1990) for the east coast at Slieve Bloom, County Meath. At that time the Electricity Supply Board had poor arrangements for buy back of wind power and there is no equivalent of the British non-Fossil Fuel Requirement (in the UK mainly a fiddle to pay for nuclear power). However, this may change as there were proposals in 1990 for an experimental wind farm. Even so, there may not yet be California type legislation allowing private owners to sell to the ESB at an economic price. If there were, wind sellers could make a profit. But in this case Ireland's rather lax planning rules might well allow eyesores as the politicians scrambled to fill the hillsides with nice little earners. Although people living near wind generators in Britain have so far accepted them as better than relying on nuclear generators, and despite a campaign by the nuclear industry to discredit them, planning of wind farms should still try to avoid gross intrusions on the landscape. They may not yet be as quiet as they can become.
Reconstruction of a House
1. Add insulation: walls, roof, windows, ?floor.
Good insulation can reduce the amount of conventional heating and fuel required to astonishingly small levels. Income energy requires capital investment. The more insulation there is, the smaller outlay on apparatus. Thus insulation should come first and should be as complete as possible.2. Install solar water heating (if there are to be paying visitors this must be larger than for a family). There is no need to be spartan (even though cold baths have apparently been proved to show some kind of good healthy quality. Must we all be healthy?)
3. Install wind generator (at least 1 kilowatt)
The writer once saw a wind-using family who made a virtue out of having as little power as possible and delighted in dim lights. No, it is better to have as much power as you can afford, especially as when the law changes you will be able to sell it to the grid (if you care to be connected).
4. Solar electricity (smaller wattage as backup)
The wind doesn't always blow, even in Dingle. However, when it doesn't the sun will probably be shining. In the summer solar power can do well.
Using this power
5. Lighting: low voltage lights from batteries charged by wind and sun. Low voltage doesn't have to mean dim, but 12 and 24 volt DC equipment is convenient and available off the shelf. 24 volt is better, as cables can be thinner or longer.
6. Cooking: perhaps through an Electric Aga (as in NCAT Machynlleth). In a very windy area the surplus electricity can be run into the Aga which is thus kept always warm. It can heat the hot water supply too. Do you eat raw food when there is a calm? Perhaps modern life is too independent of nature and we should be more aware of seasonal variations. Battery back-up can power a microwave. If one is feeding visitors a gas back-up would be best. One cylinder of gas would probably last a long time if it is only needed when there is no wind.Hydrogen is potentially another system for cooking, but hydrogen technology is still too expensive without a large grant from someone. Only when there are mass produced hydrogen generators will it be possible to use hydrogen for many of the purposes where gas and oil products are used today. When hydrogen becomes available cooking could be done with stored hydrogen.
Other Household machines
Fridges designed to work off kerosene can be adapted for any heat source. Thermo electric types (Peltier effect) are ideal to run off low voltage dc power. Neither type contains moving parts or CFCs.Vacuum cleaner, probably through an inverter, though low voltage types may be available.
Some windy people lack enough power to run a washing machine. That's something we should hang on to if we can. Banging clothes on a stone by the river looks romantic but is hard work which can be avoided if you have enough power.
tv & Computers can all be run off 12 or 24 volt supply either directly or with Inverter to 240v. The same is true of Power Tools. An inverter to run 240 volt AC apparatus wastes some of the energy in the process, so should be used only for those things which cannot be provided any other way. The size and frequency of use of the inverter might determine the number of batteries you need for storage.
Transport
There are still no affordable vehicles using income energy (other than horse powered carts). Hydrogen powered vehicles may have a future, but not yet a present. Battery powered vehicles are still very expensive and have a limited range.
Appendix 1
The (former) California System#The California Public Utilities Commission supervises a regime set up under a State Law which requires the Power Companies to accept any electricity generated by independent suppliers. This law was passed during the oil crisis of the early 1970s when there was an urgent need to find substitutes for the oil which had suddenly become more expensive and subject to the Arab oil embargo.
In the early period after the passing of this law there were tax advantages to people investing in wind and solar power schemes. People with large incomes could invest in wind and solar power and offset the losses against their income tax. These tax advantages have been withdrawn subsequently. However, the result of the tax breaks was to make it attractive to build wind power turbines. The great increase in demand for wind turbines reduced the capital cost as manufacturers improved the design and reduced the manufacturing cost. This reduction has benefited everyone as wind turbines are now much more affordable than before California started to encourage wind power. The other result of course is that the tax breaks are no longer needed because the reduced capital cost makes wind power cheaper than most other methods of generating electricity.
The power companies have responded to the requirements of the law by organising a department to make contracts with independent suppliers. This department must evaluate whether the supplier can supply power reliably and safely. These contracts are for 20-30 years of supply. (This should be contrasted with the inadequate 6 or 7 years being offered by the British Government(35)# apparently under European rules).
The result has been that electricity is being offered to the utility company from many different sources. These include: small hydroelectric schemes, from 100 kilowatts to as much as a megawatt; co-generation or combined heat and power schemes in which natural gas is used to produce electricity while the heat is used for space heating or industrial processes; biogas from large animal feedlots, garbage dumps or sewage works; electricity generated by burning wood waste from sawmills; wind turbines and solar schemes. So much new power was offered that the company complained(36)#. that they now have excess generating capacity. In a world where the production of Carbon-dioxide must be controlled this is not going to be a serious problem for long. (The main problem of the Company seems to be that they have some very expensive Nuclear Power stations which they have to use all out, even though the alternatives are cheaper. There would undoubtedly be financial problems if they closed any of their nuclear capacity. Probably they have issued bonds linked directly to the nuclear capacity.)
Since there is now no tax-loss allowable, all the schemes need to make money for the investor based on the price paid by the utility for the electricity produced.
This regime has encouraged the installation of 2 million kilowatts (2000 Megawatts) of wind power in the Pacific Gas area alone, as well as 4 million kilowatts of co-generation and 160,000 kilowatts of geothermal power. So far only 16,000 kilowatts of solar power have been installed which reflects the fact that solar power is still not competitive in costs with other methods. The installed solar power in fact represents experimental rather than commercial apparatus(37)#. The co-generation represents a great increase of efficiency of energy use since the gas is able to produce two types of energy. In conventional thermal power stations the waste heat is often not used so that the overall efficiency of thermal electricity systems is very low.
Prices paid for energy vary according to several factors: time of day and season are the most important, as energy supplied at peak demand period is the most valuable; reliability is another factor - wind in California is less reliable (day to day) than systems based on Natural Gas or hydro power. Public utilities have to supply electricity on demand and have to maintain generators which may only be needed for short periods. The capital cost has to be paid for whether they are operating or not. In California prices paid are higher in the summer when air conditioners increase the demand (but wind speed is greater then, too). The price paid to independent producers is not arbitrary. It is based on the cost to the company of providing the power itself from its own resources.
Application to Kenya and other undeveloped areas
Could this energy regime be adopted in other countries, and especially in the poorer countries? California is a wealthy state and has many people in it able to invest in these power projects. In Kenya, for example, it might be more suitable for companies and cooperatives to invest. The advantage would be that many small sources of power could be used. As well as wind resources there may be small hydroelectric sites on smaller rivers and streams which could produce power. National power companies would find it difficult to develop these small sites, but a village development cooperative or small company would be able to manage them, provided they were assisted by the necessary skilled organisations, such as construction companies and maintenance companies. The gains would be a large indigenous energy supply which could reduce reliance on imported energy. It would also be a contribution to preventing the world problem of increasing carbon dioxide in the atmosphere.As in California the national power company would have to set up a division to deal with these smaller power generators to ensure that they produce power safely and of the quality required. There would need to be legislation to incorporate the advantages of the California system, including a regulatory organisation to oversee the interests of the public and prevent the exploitation of small producers.
The main impediment to setting up a wind industry in west Kenya is not technical but legal and financial. The Kenya currency is not convertible and there are strong import controls. If electricity is paid for in Kenya shillings there is nothing to pay for spare parts which for some time would need to be paid for in dollars. This is an argument for opening up the economy in general, especially as the control of hard currency is, throughout the undeveloped world, a source of corruption and the power of the ruling elites.
Appendix 2 Skills Required
The Foundation needs as associates people with the following areas of expertise:
1. Energy engineering: wind power, photovoltaics, biogas and other biomass;
2. Business and Finance in undeveloped areas (unconvertible currencies);
3. Awareness of the proposed sites for demonstration projects (including tropical Africa: Lake Victoria wind systems) to include people's needs in the area;
4. Fund raising, including negotiation with international organisations controlling development money, such as European Community, UN agencies, voluntary organisations, private donors;
5. Publicist to popularise the concept of practical geotherapy.
Appendix 3 Two corporate structures
1. Winam Wind Power Company
Purpose: To Build, Own and Operate a Wind power system in the Kenya lakeside area for selling electricity to the National Grid.Tasks
a) To assess wind sites in the Kenya area of the Lake and profitability of using the wind for generating power. That is, to assess costs and values of power to be sold. (If profitability not assured, project to be deferred until energy prices rise). Cost of national profit taxes to be ascertained.
b) To raise capital
c) To acquire rights to use land, rented from farmers or public bodies.
d) To negotiate sales to National Power companies.
e) To acquire and import equipment - generators and other machinery
f) To hire qualified contractors to erect equipment.
g) To operate and maintain equipment
h) To expand on to other suitable wind sites.
Personnel required, includes:
a) Engineer, qualified in wind power to supervise design of system and installation.
b) Legal expert to negotiate land rights, power connection and relations with local and national government.
c) Accountant.
Ownership
Ownership to revert to people of the area. Initial ownership to be of the form of Design, Build and Operate Company, paying agreed amount to local people:
i. Rent for land used by generators
ii. Local business tax (possibly to be negotiated down in initial phase while project is beginning)
iii. Share of profit (after other profits remitted to pay off Hard Currency costs.)
Gradual transfer of ownership, building up a shareholding purchased from islanders' share of profits by a local body e.g. consisting of all residents, held by a trust elected by residents.
Local profits to invest in local business to expand the local economy.
Legal and financial experts will have to solve the problems of remitting profits to pay for hard currency investment, when income will be in local currency(38)#.
2. Energy Centre
Purposes
a) Local
A research and development institution to develop local sources of energy, to include photovoltaic and biomass (biogas, ethyl and methyl alcohol, high efficiency firewood and charcoal cooking, oil from agricultural crops).
b) National
To develop substitutes for Kenya's energy imports, thus strengthening the National economy
c) Global
To assist in the necessary transition from Carbon fossil fuels (capital) to income, solar-based fuels as part of a worldwide effort to prevent and reverse climate change caused by industrial activities.
Tasks
a) To achieve the adoption of biogas and other biomass fuels for local cooking, to replace charcoal and firewood (which present population densities are using up faster than they grow).
b) to popularise the concept of living on Income energies (those derived from solar energy): including wind for pumping and electricity, photovoltaics.
c) To find a use for the Water Hyacinth as a source of biogas and compost to be put on the soil (its arrival is an ecological disaster, but it can be harvested for compost and energy).
Funding
This centre should expect to spend money and is not likely to make a profit in itself. However, it should be assessed regularly and an estimate made of the value of energy produced as a result of its activities. e.g. assess the value of biogas produced by the plants installed by local farmers. Funding could be allotted according to success in getting people to use new sources of energy. Assessment to be made by independent body such as the proposed Geotherapy Foundation.
Personnel
There is a role for qualified overseas volunteers from VSO, Peace Corps etc. These must have practical engineering skills.
And similar local persons, including from other parts of Africa.
Education
The centre might be attached to local educational institutions. An aim might be eventually to provide higher educational qualifications in income energy techniques. (But there is a fundamental problem with educational enterprises in Africa: graduates often do not undertake practical work which benefits people. And actually, practical qualifications are more useful.)
At a later stage the centre might become a source of training for people working in other parts of Africa.
e.g. There are many similar sites around the Lake in Tanzania and Uganda.
What is the economic future of Rusinga?
1. Agriculture
Can the small subsistence farms on Rusinga make money? Probably not - from farming alone. As the population of the island increases there may be increasing difficulty in feeding the people. There may well be some future in intensifying agriculture, especially with irrigation during the dry season. Possibly there may be a future in growing higher value crops, but is there a market? Kisumu is a growing town but most of the inhabitants have little money. Could people grow high value crops for export? I don't know.
In early 1994 the rest of the country was reported to have a serious drought. Lakeside areas would be useful at such times.
2. Energy
A. Wind
Rusinga's only real asset is its wind. If a wind industry of the kind found in California could be started, a steady income might be possible.
How can it be financed? As it needs imported machinery to start, perhaps it ought to be a Joint Venture. However, because Kenya is a closed currency area, there is a large scope for corruption. It can be expected that officials, who have to permit foreign currency to be spent and imports allowed in, will demand kickbacks and bribes. This might remove the actual profitability, in which case the industry could not come into being. If the currency becomes convertible, removing the power of officials to control dollars, the situation might be greatly improved. The present government probably would not introduce convertibility.
However, even with convertibility there would need to be a contract with the main power distributor along the lines of those in California. But this may need a legal framework of the same kind: regulatory authority, privileged access for independent producers from wind and sun. Small producers in other parts of the United States do not always have such a favourable regulatory climate(39)#
If it could overcome these problems the question arises, how can the people on the island benefit from this industry?
1. Rent from the use of land. In Britain and America farmers rent land for wind generators. As the land around can be used for grazing and crops this is good value, and marginal hill land actually can make more from wind generators than from crops or animals.
2. Shares in the wind business.
Can a wind company be forced to assign shares to the locals, perhaps held in a trust by an association of all the islanders? Possibly. This needs an expert in company control. The real object here is to prevent the owners of the wind generators from getting rich without the local people gaining. The writer would particularly wish to prevent the present elite from taking the advantage for themselves and leaving the people with nothing. It might be better not to start such an industry at all rather than allow this to happen. That is in fact the main result of this common pattern in post-colonial Africa: development doesn't happen because it is choked by all the crooks who demand their share, so that there is no profit for reinvestment. The main reason why some areas such as Sicily and Northern Ireland fail to develop is the illegal exactions by Mafia-type organisations.
3. Maintenance of the wind machines.
Unfortunately there would probably be little work here. The skills required for the largest generators will be of higher engineering. The most likely pattern is a mobile unit able to service the whole area. Enquiries from California or British wind companies might produce an estimate of the amount and kind of employment likely to be created here.
Smaller wind devices are simpler and people could be trained at the level of motor mechanics for some, such as simple wind pumps.
B. Biogas
After the wind biogas is an important potential energy source. However, this is not an activity which could generate income from outside, as the gas cannot be sold. If the gas can be used in small manufacturing it might be an ingredient in money-making activities. But its main direct effect would be in making women's lives easier (which is why men so often undervalue it). To the extent that it substitutes for oil products, such as kerosene, its economic effect is seen in the money that is retained in the community. On the country as a whole no foreign exchange is needed for imports of oil products.
The indirect effect is at least as important: the maintenance and improvement of the soil productivity. It is not easy to decide from a distance whether large or small biogas generators should be encouraged. Small ones suitable for a single family (2 or 3 cu metres/day) are possible. The material would come from the farm itself: chicken and cow manure, crop wastes, weeds from hoeing. All the gas would be consumed by the family, mostly in cooking. A larger, industrial type might be possible if it uses the vegetable produce of the Lake: reeds from the Sudd beds. In this case there might be enough gas to feed larger uses, such as a bakery or for electricity to be sold to the grid. The fertiliser output might be saleable or might go to feed larger farms.
3. Services
These need more study.
History of Rusinga's Economy 1. Pre-colonial
-small population, growing food, fishing, trading with other lakeside communities (? is there evidence)
This is speculation to some extent and needs some research. However, a picture of a small community living on Rusinga, with some cattle, some cultivation, some fishing and some trading does not seem too unlikely. What did they trade? I'd like to know.
2. Arrival of Arabs to the lake area (early 19th century): new styles of sailing boats derived from coastal craft (lateen sails "dhow" design, more trading, perhaps even some with the coast via Mwanza and Tabora in Tanzania.
3. Colonial period (from 1900): poll tax (hut tax), migrant labour, increasing population, remittances.
The colonial government imposed a poll tax or hut tax to create a need for money and therefore for paid labour. People began to leave the area to work in the colonial economy. The money they sent back home began to pay for such things as school fees which replaced poll tax as the main need for money. This is a pattern that has continued ever since. The remittances from family members working in other parts of Kenya support a good deal of the consumption of people in Rusinga. How much? Research is needed. How much income came from the sale of agricultural produce and fishing? More research is needed. I would guess, not a lot. As late as 1968 the only access was by boat from Homa Bay and other ports.
4. Post independence: arrival of road and ferry; causeway; increasing population; increased need of remittances; lakeside trading now labelled smuggling (as frontiers went up).
The arrival of a road from Homa Bay to Mbita has linked the island more closely to the rest of Kenya (previously only boats to Homa Bay). At first there was a pontoon ferry; later the road was connected directly by a causeway. Phone and electric utilities arrived. However, income generating activities have not greatly increased. Subsistence has got worse as the fishing has completely changed with the introduction of Nile Perch, the disappearance of the traditional fish and all the drying activities which were associated. (Nile Perch is a much oilier fish and needs more firewood to cure). It would not surprise me if remittances are at present the larger income. As population has increased the pressure on the land and fishing grounds has increased. More people are trying to live on the same amount of land. Actually, the land area is decreasing because bad farming methods have created eroded areas.5. Present and near future:
Rusinga is now a peripheral area of Kenya near the artificial frontier with Uganda and Tanzania. As a result of the failure to maintain the free trading area after the breakdown of the East African Community, trading with the other lakeside countries is often illegal and has to take the form of smuggling.
Fishing has declined as a result both of overfishing and the introduction of the Nile perch (an ecological disaster). The waste water of Homa Bay and other towns are polluting the waters of the Lake. As yet Rusinga is probably outside the polluted area but it may well increase as the towns grow without installing proper treatment plants. The land has shown signs of misuse for many years (even in 1968 I remember seeing signs of erosion due to farming on slopes too steep. There is a need for intensified methods of farming (among these would be the use of biogas to generate a replacement for firewood which is no longer available), replanting of bad lands with forest, and some other industrial income. I suggest that the wind power is the best form of industrial income. However, Kenya's economy as a whole is doing badly, which reduces the possibilities of remittances. It is unrealistic to assume that Rusinga people can rely on earning money in other parts of Kenya: employment generation is not going well. A regular income from selling power might replace remittances. If the income can be invested in the capital equipment of new business the island people might have a chance of earning a living in the area, instead of going into the rest of Kenya.If ethnic conflict in the rest of the country grows, they will have to rely on their own area more in any case.
Kenya as a whole would benefit from development of the wind power by becoming more independent of imported energy.
The people of the area believe there are political reasons why development projects have not come their way. This seems likely to continue, as the local ethnic group is not represented in the government. How likely is this to lead to war? It is still possible to plan on the assumption that peace is possible, but if war breaks out, or escalates from the present rather sporadic fighting, the plan would be completely unrealistic.
Bibliography Meadows, Meadows, Randers, Behrens -Limits to Growth (Earth Island 1972)
Meadows, Meadows, Randers - Beyond the Limits (Earthscan 1992)
Al Gore - Earth in the Balance (Earthscan 1992)
Alexander King & Bertrand Schneider - The First Global Revolution (Simon & Schuster 1991)
Power Producers' Interconnection Handbook (Pacific Gas and Electric Company 1989)
The basic text for contractors wishing to offer electricity to the PE&G utility, containing the technical and financial conditions required to be fulfilled. (now out of date)
Kenya
W.E.Van Lierop & L.R. van Veldhuizen - Wind Energy development in Kenya (4 volumes Netherlands Development Cooperation Information Department 1982)
Ireland
Jim Wooldridge & Richard Hardwicke Options for the '90s (Earthwatch Bantry 1990)E.G.Matthews Wimborne Energy Consultancy
10/10/01
wimtalk AT compuserve.comLast revised 1/08/12
Notes
- (1) A nuclear Fast Breeder Reactor turns Uranium into Plutonium and thus increases the amount of available fission energy. A factory turning out photovoltaic cells, itself powered by solar power, is a Solar Breeder.
- (2) The Story of Tea in I. Shah Tales of the Dervishes.(London 1968) (Don't talk about it, show it).
- (3) Geotherapy: the process of correcting the world ecological problem. A term perhaps coined by Prof. Richard Grantham, Université Claude Bernard, Lyon. It is nothing to do with the various quack "therapies" which are fashionable in certain circles, but can be justified with rigorous scientific analysis. See This article and Thomas Goreau
- (4) Thomas Goreau on Coral Reef bleaching: references available
- (5) Earth in the Balance p 185
- (6) Meadows, Meadows, Randers - Beyond the Limits (Earthscan 1992)
- (7) Global Revolution p105
- (8) This raises the question of whether the true cost of pollution can be calculated and assigned to the creator: for example, acid rain is believed to come from power stations, but it is difficult to assign any particular fall of acid rain to a particular source, and therefore to make the owners pay or, better, desist.
- (9) Business-as-usual: Pejorative term used by Greens for those who deny the need to change basic economic policies, or even deny that there is a problem.
- (10) It would be wise to give some credence to the more lurid possible consequences: population crash, war, mass migrations. There is no reason to believe the western world would be exempt. Less developed areas are also at risk but, starting from a lower level of consumption, might have a better chance of adapting to new methods.
- (11) John Maynard Keynes's cynical definition of "the long run". But in many parts of the world the bad effects are already with us. And who is "we"? Surely, it is everybody, living and yet to be born.
- (12) It is better to use the term "income energy" than "renewable" as this will be understood by economists and accountants. Wind, solar, waves, tidal are some of the income energy sources. In tropical areas biogas is an important income source and is needed to replace firewood and charcoal, which though income fuels are being used faster than they form.
- (13) National Centre for Alternative Technology, Machynlleth Wales.
- (14) St. Augustine's prayer: Make me chaste, O Lord, but not yet.
- (15) Rabbi Hillel.
- (16) Minimising the use of carbon fuels.
- (17) Shown by Pacific Gas and Electricity Co. California
- (18) Beyond the Limits p76
- (19) See appendix 1
- (20) For example, the Swedish Welgas project: wind, electricity, hydrogen; and in West Berlin before the unification of Germany.
- (21) California power companies must accept wind and solar power and pay for it at a rate calculated according to the company's cost of generating by other means. In Kenya the rules might specify that wind should replace oil fired power stations (the most expensive). The law would need to be changed to allow this. Described in E.G.Matthews: Winam Wind Power.( see Appendix 1)
- (22) The Gulf of Lake Victoria, westward from Kisumu.
- (23) A hospital in Zimbabwe running on solar power ran the batteries down and could not afford to replace them. The author has done it too.
- (24) Van Lierop & L.R. van Veldhuizen - Executive Summary p15.
- (25) The California experience suggests that on a large enough scale wind is now competitive with "conventional" energy. The break even point may be in the half megawatt range. These developments have occurred since Van Lierop & Veldhuizen did their investigation.
- (26) For small installations (less than 0.5 megawatts).
- (27) John Scotus Erigena in 845 brought wisdom to the court of Charles the Bald, who was much in need of it.
- (28) Jim Wooldridge & Richard Hardwicke Options for the '90s
- (29) Electricity Supply Board: the state owned electricity industry.
- (30) Options
- (31) One day Hydrogen will be the transportable kind of energy. Ireland and Iceland could be important producers from wind and wave and geothermal sources.
- (32) Abbey Organics, 11 Ballymena Road, Portglenone, BT44 8BL N.I.
- (33) Seancara, pronounced Shankara, slightly hippyish.
- (34) Based on Power Producers' Interconnection Handbook (Pacific Gas and Electric Company 1989). From E.G.Matthews: Winam Wind Power 1990
- (35) The Non-Fossil Fuel Obligation: in reality a cover for subsidising the nuclear industry by offering a quota to wind suppliers. Not a market solution as British wind suppliers are actually paid more than the market price, in order to pay the same to the nuclear industry but are not allowed to expand beyond the quota.
- (36) Cogeneration and Small Power Production Program - an Overview, page 5
"In early 1988 the California Energy Commission and the California Public Utilities Commission issued a joint report to the state legislature on excess generating capacity in California. The report noted that there is currently an imbalance in the supply and demand for electricity.
After years of effort, the state's major electric utilities brought on line two nuclear power plants (San Onofre and Diablo Canyon), both of which are currently operating at high capacity. During these years (QFs - Alternative suppliers) also signed contracts to provide thousands of megawatts of power to utilities - a generous proportion of which is for long-term baseload power. At the same time, demand was increasing more slowly than expected as lifestyles and building and appliance designs adapted to the high energy prices and conservation programs of the last decade. In short, after billions of dollars of investment and the good faith efforts of all, California has more than enough capacity to meet the state's current needs."
- (37) Pacific Gas & Electric Company Cogeneration and Small Power Production Quarterly Report third quarter 1989. see E.G.Matthews Winam Wind Power.
- (38) Home Power #36 p 96 on New Hampshire, where pay back is at a rate too low to be worth doing.
Interesting reading Fred Pearce - The Last Generation
Scary book but he has met the main students of climate. Suppose he and they are right? Bad times ahead, quite soon.
Sir Nicholas Stern - Review of the economics of Climate Change
James Lovelock - Gaia
James Lovelock - Revenge of Gaia
Gaias Rache
See this page for more books
Geotherapy Index
Home