
COMPARISON OF EFFICIENCY
Assumptions:
Note that we ignore any difference in efficiency between a nested
loops join and a merge join. The discussion also does not take
into account any overheads incurred because the indices
themselves need space.
Query 3:
Query 3 selects the names of those who've put in the highest bid
for an item.
The SQL for this query is:
Select T.name
From Transactor T, Item_offers I, Bid B
Where T.EbayID = B.EbayIDBuyer AND
B.LotNumber = I.LotNumber AND
B.Value = I.HighestBid;
We chose several combinations of indices, but in the end we found
that the most interesting plans generated was for a composite
index on Item_offers:
create index number2_idx on
Item_offers(HighestBid, LotNumber);
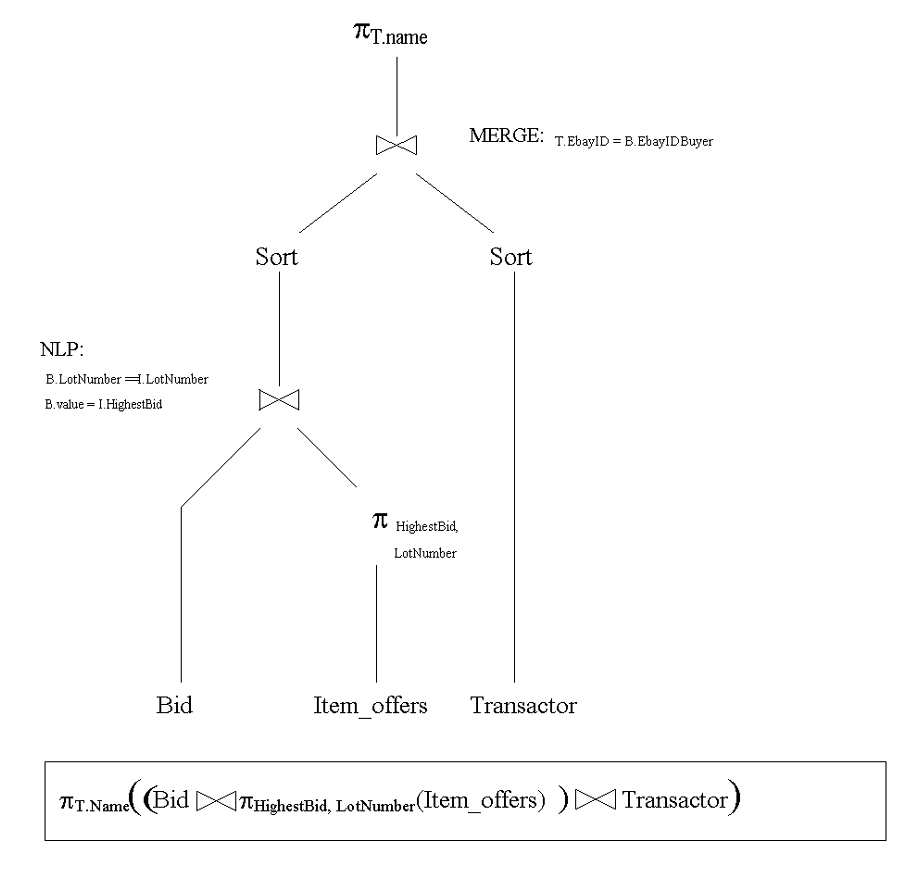
The execution plan is:

The relational Algebra:
and the second option, creating an index on Item_offers and
another index on Transactor:
create index comp1 on
Item_offers(HighestBid)
create index comp2 on Transactor(EbayID)
The execution plan is:

The relational Algebra:

The plan using the composite index makes a projection on
Item_offers.HighestBid before the join with the Bid table. It
then performs a full scan of the Bid table, performs the join on
Bid and Item_offers and finally joins that result with the
Transactor table. The Transactor table is also accessed using a
full scan.
The other plan utilises two indices to get to the correct values
for Item_offers.HighestBid and Transactor.EbayID. The index for
Item_offers is used in the join between Item_offers and Bid, and
the index on Transactor is used in the final join.
It is not immediately obvious which method is the fastest. The
first plan succeeds in eliminating a big part of the Item_offers
table very quickly, through the projection. But it then has to
perform table scans of the other two tables. A full scan is only
performed once in the second alternative. However, the pushed
down projection in the first alternative ensures that only the
interesting data is taken into the join, eliminating the
redundant information at a very early stage, which speeds up the
execution of the query. The second alternative makes no attempt
on eliminating such columns, but gains an advantage in that it
only performs one full scan.
The difference in performance would probably depend on the sizes
of the tables. If the Item_offers table was a lot bigger than the
other two, then it is likely that using a composite index on
Item_offers will speed up execution more than the second
alternative. However, for tables that are of a similar size, the
latter alternative would probably be preferable.
Query 13:
Query 13 finds the addresses of transactors who have bid for
kitchenware but not books.
The SQL for this query is:
Select T.Address
From Transactor T, Bid B, Item_offers I
Where T.EbayID = B.EbayIDBuyer AND
B.LotNumber = I.LotNumber
AND I.Category = 'kitchen'
MINUS
Select T2.Address
From Transactor T2, Bid B2, Item_offers I2
Where T2.EbayID = B2.EbayIDBuyer AND
B2.LotNumber = I2.LotNumber AND
I2.Category = 'books';
Plan 1: create index number3_idx on
Item_offers(Category)
The execution plan is:
:

The relational Algebra:

Plan 2: create index number4_idx on Item_offers(Category,
LotNumber)
The execution plan is:
:

The relational Algebra:

Plan 3: create index number7_idx on Item_offers(Category)
111111create index number8_idx on Bid(LotNumber)
111111create index number9_idx on
Transactor(EbayID)
The execution plan is:
:

The relational Algebra:

All the plans involve an early selection on the Category
attribute of Item_offers. The first alternative only involves
using a single index on Item_offers.Category, whereas the third
option utilises 3 indices - one on Item_offers.Category, one on
Bid.LotNumber and one on Transactor.EbayID. So the third plan is
certainly faster than the first because it avoids any full table
scans.
The second alternative employs a single composite index on
Item_offers(Category, LotNumber). So we have a situation similar
to that for query 3, only that now the alternative to the
composite index is to use indices for all tables - thus avoiding
any full table accesses. This advantage of the second plan is
probably so great that the two other plans will be slower in
almost all cases.
