LA RESOLUTION DU PROBLEME D'ABORT DANS APOLLO 14 (ET L'ALARME 1202 DANS APOLLO 11)

 Dans Apollo 14, au dťbut de la descente du module lunaire sur la lune, les astronautes ont vu le bouton abort stage clignoter de maniŤre intermittente; un astronaute l'a gentiment tapotť, et il s'est ťteint. |
 Le problŤme viendrait d'un signal parasite dans l'interface logique de l'abort. |
 Le bouton Abort Stage est le bouton qui permet de se sťparer de l'ťtage de descente avant de retourner au module de commande, tandis que le bouton Abort avorte simplement la mission, et permet de revenir au module de commande avec l'ťtage de descente. Le bouton Abort Stage est ignorť avant la descente motorisťe, car il est alors encore temps de revenir au module de commande avec l'ťtage de descente. |
Mais, dans la descente motorisťe, le signal parasite d'abort pourrait ordonner la sťparation des deux ťtages du module lunaire sans qu'elle ait ťtť demandťe par les astronautes en appuyant sur le bouton Abort Stage. Cela signifie que, si une solution n'est pas trouvťe pour ce problŤme, la mission ne peut Ítre menťe ŗ terme, et doit Ítre immťdiatement avortťe. |
 Les astronautes ont donc rapportť ce problŤme ŗ Houston et demandť de l'aide pour rťsoudre ce problŤme. Houston a appelť les ingťnieurs du MIT pour qu'ils conÁoivent une solution pour ce problŤme, permettant de rťaliser la descente motorisťe sans qu'elle soit interrompue par un abort non dťsirť. |
 L'ťquipe du MIT a donc rapidement mis au point une modification pour rťsoudre ce problŤme, et l'a envoyťe ŗ Houston. |
 Houston a ensuite tťlťmťtrť cette solution magique au module lunaire, laquelle consistait en sťquences de touches que les astronautes devaient taper sur le clavier de l'AGC...mais pas immťdiatement, au moment adťquat, comme expliquť dans un lien. Lien vers l'explication de la rťsolution de l'abort dans Apollo 14 |
 Juste aprŤs la mise ŗ feu du moteur, un bit en mťmoire, appelť "LETABORT", est positionnť dans un dťlai rapide de 0,2 seconde; ŗ partir de ce moment, si rien n'est fait, le signal parasite d'abort peut ordonner la sťparation des deux ťtages du module lunaire. |
Si les astronautes attendent que le moteur soit mis ŗ feu, le bit LETABORT sera positionnť trŤs rapidement, et cela prendra du temps aux astronautes pour taper la sťquence pour razer le bit LETABORT, et, dans l'intervalle, le signal parasite pourrait commander la sťparation des ťtages. Donc, juste aprŤs le dťbut de la routine d'allumage, les astronautes doivent taper une commande pour changer le numťro de programme de P63 (qui est un programme de la descente motorisťe) en P71 (qui n'est pas un programme de la descente motorisťe), de sorte que la commande d'abort stage ne soit pas prise en compte lorsque le bit LETABORT sera positionnť. Selon la description du problŤme, la commande qu'Edgar Mitchell devait taper ťtait: VERB 21 NOUN 01 ENTER 1010 ENTER 107 ENTER |
 La description du problŤme ťtablit que, parce que le programme enregistrť dans MODREG a ťtť changť pour un programme qui n'appartient pas ŗ la descente motorisťe, la routine d'allumage ne va pas mettre le moteur ŗ pleine poussťe aprŤs 26 secondes comme elle le devrait normalement. En consťquence la procťdure a suivre est d'attendre 26 secondes aprŤs le dťbut de la routine d'allumage... |
 ... et de mettre manuellement la commande de poussťe au maximum afin de faire ce que la routine d'allumage aurait du faire normalement si le programme courant n'avait pas ťtť changť... |
 ...c'est ŗ dire mettre le moteur ŗ pleine poussťe. |
Puis Mitchell doit taper une commande pour positionner un bit ZOOMFLAG, ce qui aurait normalement dŻ Ítre fait par la routine d'allumage (si le programme courant ťtait restť P63), afin de commander logiquement la pleine poussťe. Cette commande est: VERB 25 NOUN 7 ENTER 101 ENTER 200 ENTER, 1 ENTER Notez que l'adresse "101" est spťcifiťe sous forme de trois chiffres en octal, alors que la documentation du DSKY spťcifie qu'une adresse machine doit obligatoirement Ítre spťcifiťe sous forme de 5 chiffres en octal. Le masque de bit "200" est aussi spťcifiť sous forme de 3 chiffres en octal, alors qu'un masque de bit doit normalement Ítre spťcifiť sous forme de 5 chiffres en octal, car il y a 15 bits dans un mot, et chaque chiffre octal code 3 bits du mot. Mitchell tape ensuite une commande pour remettre le bit LETABORT ŗ 0, qui est: VERB 25 NOUN 7 ENTER 105 ENTER 400 ENTER, 0 ENTER Finalement Mitchell doit encore rentrer une commande pour remettre le numťro de programme ŗ P63 (programme normal de la descente motorisťe), qui est: VERB 21 NOUN 01 ENTER 1010 ENTER 77 ENTER AprŤs que le programme d'allumage normal ait ťtť restaurť, le LGC est sensť avoir ŗ nouveau le contrŰle de la poussťe. |
 Finalement la description du problŤme dit que Shepard remet la manette de contrŰle du contrŰle de poussťe au minimum, de maniŤre ŗ laisser le programme de guidage reprendre le contrŰle de la poussťe, disent-ils (aprŤs la phase de ralentissement, le programme de guidage doit diminuer la poussťe). Mais c'est complŤtement absurde, ce n'est pas ce qu'il doit faire, car le contrŰle manuel de la poussťe et le contrŰle automatique par le LGC ne sont pas cumulatifs, mais exclusifs; ce n'est pas l'un et l'autre, mais l'un ou l'autre. |
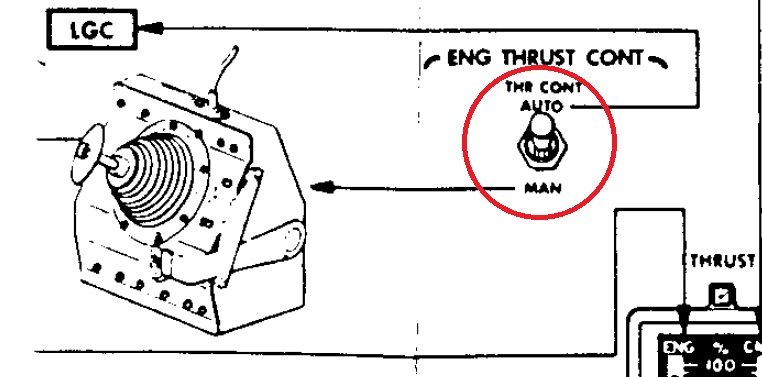 La poussťe est contrŰlťe par soit la manette de contrŰle, soit le LGC, mais pas les deux en mÍme temps. Quand la manette de contrŰle a le contrŰle de la poussťe, le LGC n'a aucun contrŰle dessus (interrupteur de contrŰle de mode de la poussťe sur la position "MAN"), et, quand le LGC a le contrŰle de la poussťe, la manette de contrŰle n'a aucune action dessus (interrupteur de contrŰle de mode de la poussťe sur la position "AUTO"). |
 Shepard ne doit absolument pas mettre le contrŰle manuel de poussťe au minimum, mais simplement changer l'interrupteur de mode de contrŰle de la poussťe de Manuel vers Auto, de maniŤre ŗ redonner le contrŰle de la poussťe au LGC (auquel cas la manette de contrŰle n'est pas du tout prise en compte). |
S'il se contente de mettre le contrŰle manuel de poussťe au minimum, la poussťe restera au minimum, car le LGC n'aura pas le contrŰle de la poussťe, comme l'interrupteur de mode de contrŰle de la poussťe reste sur la position "MAN", ce qui signifie que la descente motorisťe ne pourra pas se produire normalement. |
 En rťalitť, c'est complŤtement absurde. En effet, le fait que la routine d'allumage positionne le bit LETABORT, qui fait partie de son traitement, montre qu'elle tourne normalement. Une fois que la routine d'allumage est lancťe, il est ťvident qu'elle va faire son traitement normal complet, et qu'elle ne va pas tester le numťro de programme courant pour ne pas faire une partie de son traitement. Ce que les astronautes auraient donc dŻ faire est d'attendre que le moteur dťmarre, et ils auraient alors su ŗ ce moment que le bit LETABORT avait ťtť positionnť, et puis simplement taper la commande pour razer le bit LETABORT, suivie de la commande pour restaurer le numťro de programme ŗ P63. Cela aurait fait trois sťquences de touches au total, au lieu de quatre, et Shepard n'aurait pas eu ŗ contrŰler manuellement la poussťe, ce qui aurait ťtť fait automatiquement par la routine de guidage. Le fait que la routine d'allumage n'aurait pas automatiquement contrŰlť la poussťe est une excuse que les ingťnieurs ont inventťe pour justifier le fait que Shepard aurait dŻ contrŰler manuellement la poussťe, ce qui a permis de crťer une anomalie avec Shepard ne redonnant pas le contrŰle de la poussťe au LGC ŗ la fin de la maneuvre, avec la consťquence que la descente motorisťe ne pourrait pas se produire normalement. |
 Cette complication inutile est donc une bonne blague de la part des ingťnieurs. |
 Si les astronautes avaient ťtť capables de modifier le programme dans la core rope memory, ils auraient empÍchť la routine d'allumage de positionner le bit LETABORT, et, de cette maniŤre, le module lunaire aurait ťtť protťgť contre un abort stage non dťsirť commandť par le signal parasite aprŤs le dťbut de la routine d'allumage, sans que les astronautes aient ŗ faire cette procťdure compliquťe (qui en plus se termine anormalement). |
 Mais cela aurait supposť que les astronautes soient capables de modifier le programme dans la core rope memory. La core rope memory ťtait programmťe par des ouvriŤres qui faisaient passer des fils ŗ travers des tores de ferrite ou les faisaient contourner, suivant des instructions qui leur ťtaient donnťes. Chaque fil reprťsentait un bit. AprŤs leur travail, la core rope memory ťtait testťe pour voir si elle avait ťtť correctement tissťe. S'il y avait ne serait-ce qu'une seule erreur dans un fil de bit, ce fil devait Ítre complŤtement retirť et retissť. |
 Nous imaginons mal les astronautes faire ce travail dans le module lunaire. La seule ressource qui leur restait ťtait d'appliquer une procťdure qui n'ťtait pas parfaite, n'offrait pas une garantie totale de succŤs, et qui de plus ťtait inutilement compliquťe, telle que dťcrite. |
 Et ce n'est pas tout, car la description du problŤme donne d'autres dťtails qui sont totalement dťlirants. Ils disent que la routine a corrigť la hauteur calculťe avec seulement une portion de la diffťrence entre la hauteur mesurťe par le radar et celle mesurťe par les accťlťromŤtres, qu'ils appellent "DeltaH". |
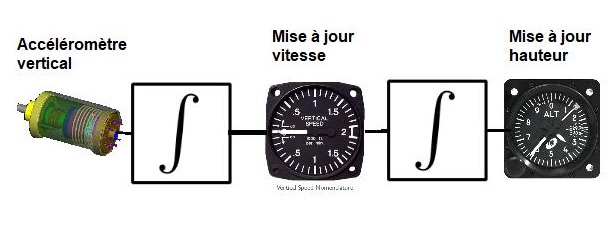 Mais il n'y a rien de tel que la hauteur mesurťe par les accťlťromŤtres. Les accťlťromŤtres ne donnent pas directement la hauteur courante. La hauteur calculťe est prťcisťment mise ŗ jour ŗ partir de la lecture des accťlťromŤtres (une premiŤre intťgration pour mettre ŗ jour la vitesse verticale ŗ partir de la lecture de l'accťlťromŤtre vertical, et une seconde pour mettre ŗ jour la hauteur courante ŗ partir de la vitesse verticale). |
Ils disent ensuite qu'ŗ 50000 pieds, ils ajoutent 0% de cette portion, et 35% de cette portion ŗ 10000 pieds. Vous m'expliquerez comment on peut augmenter de 0%! Et combien de cette portion ajoutent-ils entre ces deux hauteurs? |
Je vais maintenant expliquer pourquoi cela n'a pas de sens de corriger la hauteur calculťe avec seulement 35% de la diffťrence avec la hauteur obtenue ŗ partir du radar. Un accťlťromŤtre n'est pas parfait, il y a toujours une lťgŤre erreur de biais. Pour mettre ŗ jour la hauteur calculťe, cette erreur passe ŗ travers une double intťgration, et cette double intťgration tend ŗ faire diverger cette erreur. Si la hauteur calculťe est corrigťe avec seulement 35% de la diffťrence avec la hauteur obtenue par le radar, qui est plus prťcise, seulement 35% de cette erreur est compensť, il en reste 65% dans la hauteur calculťe. |
Ensuite, ils disent que, si le registre de programme ne contenait pas P63, la routine de mise ŗ jour penserait que le programme courant ťtait P66 et incorporerait les 35% du DeltaH; alors la routine ne vťrifie mÍme pas la hauteur courante? Ils disent que le problŤme sur le radar d'alunissage aurait ťtť provoquť par un bit d'ťchelle qui aurait changť 38 secondes avant que l'une des procťdures de masquage d'abort soit entrťe; vous m'expliquerez le rapport entre un problŤme avec le radar d'alunissage et l'entrťe d'une procťdure de masquage d'abort! Tout ceci n'est qu'une suite d'absurditťs! |
 Je me suis intťressť ŗ la maniŤre dont l'abort ťtait traitť dans le programme de l'AGC, et comment le bit LETABORT ťtait pris en compte, quelle diffťrence cela faisait entre ce bit mis ŗ 1 ou ŗ 0 lorsqu'un abort ťtait demandť. Dans le programme entier de l'AGC, il n'y a qu'un programme unique ou ce bit est pris en compte (ŗ part sa mise ŗ zťro au dťbut du programme de descente), c'est ŗ dire dans le traitement des programmes P70 et P71 (LEM LM DPS Abort, and LEM LM DPS abort). Et je montre ici l'unique sťquence dans laquelle ce bit est testť. Je vais dťtailler cette sťquence, pas ŗ pas. |
 Cette sťquence teste si le bit LETABORT (correspondant ŗ LETABBIT) est positionnť. S'il l'est, le rťsultat ne sera pas nul, sinon l'instruction BZF LANDISP (branchement si l'accumulateur est nul) fait un branchement ŗ LANDISP, ce qui correspond au traitement de R10, selon le commentaire. |
 Donc, si le bit LETABORT est mis, nous continuons en sťquence. MODREG contient le numťro de programme courant; l'instruction "CS MODREG" place le contenu nťgatif de MODREG dans l'accumulateur, ce qui signifie que, si le programme courant est P71, l'accumulateur contient ŗ prťsent -71. L'instruction "AD 1DEC71" ajoute 71 ŗ l'accumulateur, ce qui signifie que, si le programme courant est P71, l'accumulateur contient ŗ prťsent 0. L'instruction "BZF LANDISP" fait un branchement ŗ LANDISP si l'accumulateur est nul, autrement dit si le programme courant est P71, selon ce qui a ťtť dit. |
 Donc, si le programme courant n'est pas P71, le programme continue en sťquence. L'instruction "READ CHAN30" lit le contenu du canal 30. |
 Le canal 30 est dťcrit dans le manuel technique du module lunaire. Les deux bits intťressants sont le premier bit, qui est positionnť si un abort utilisant le moteur de descente a ťtť demandť (en appuyant sur le bouton ABORT), et le quatriŤme bit, qui est positionnť si un abort utilisant le moteur de remontťe a ťtť demandť (en appuyant sur le bouton ABORT STAGE). |
 L'instruction "COM" complťmente tous les bits de la valeur lue dans le canal 30 (c'est ŗ dire que les bits ŗ 1 sont mis ŗ 0, et vice versa); le rťsultat est mis dans le registre L par l'instruction "TS L". A prťsent le premier bit de l'accumulateur est ŗ 0 si un abort a ťtť demandť, et le quatriŤme bit est ŗ 0 si la demande a ťtť faite avec le bouton ABORT STAGE. L'instruction "MASK BIT4" ne garde que le quatriŤme bit de l'accumulateur, et met les autres bits ŗ 0, et donc, l'accumulateur est ŗ prťsent nul si une demande d'abort a ťtť faite avec le bouton ABORT STAGE. L'instruction "CCS A" teste l'accumulateur, et exťcute la premiŤre instruction suivante si l'accumulateur est positif, et la seconde instruction suivante si l'accumulateur est nul. Donc, si un abort a ťtť demandť avec le bouton ABORT STAGE, c'est la seconde instruction suivante "CS MODREG" qui est exťcutťe, l'instruction suivante est sautťe. |
 Le programme continue donc en sťquence. MODREG contient le numťro de programme courant; l'instruction "CS MODREG" place le contenu nťgatif de MODREG dans l'accumulateur, ce qui signifie que, si le programme courant est P70, l'accumulateur contient ŗ prťsent -70. L'instruction "AD 1DEC70" ajoute 70 ŗ l'accumulateur, ce qui signifie que, si le programme courant est P70, l'accumulateur contient ŗ prťsent 0. L'instruction "BZF LANDISP" fait un branchement ŗ LANDISP si l'accumulateur est nul, autrement dit si le programme courant est P70, selon ce qui a ťtť dit. |
 Le programme continue donc en sťquence si le programme courant n'ťtait pas P70. Le contenu du canal 30 a ťtť mis dans le registre L APRES avoit ťtť complťmentť (c'est ŗ dire les bits ŗ 1 mis ŗ 0, et vice versa). Cela signifie que le premier bit de L contient 0 si un abort a ťtť demandť. L'instruction "CA L" place le contenu de L dans l'accumulateur; cela signifie que le premier bit de l'accumulateur est 0 si un abort a ťtť demandť. L'instruction "MASK BIT1" ne garde que le premier bit dans l'accumulateur, et met les autres bits ŗ zťro; comme le premier bit ťtait ŗ 0 en cas de demande d'abort, cela signifie que l'accumulateur est nul aprŤs cette instruction dans ce cas. |
 L'instruction "CCS A" teste l'accumulateur, et exťcute la premiŤre instruction suivante si l'accumulateur est positif, et la seconde instruction suivante s'il est nul. Cela signifie que, si un abort a ťtť demandť, c'est la seconde instruction suivante "TCF LANDISP" qui est exťcutťe, comme l'accumulateur est nul couramment (contrairement ŗ ce que dit le commentaire). En d'autres termes, si un abort a ťtť demandť avec le bouton ABORT, Le programme fera le traitement de R10 (LANDISP). Donc, si les boutons ABORT et ABORT STAGE sont simultanťment appuyťs (et le bit LETABORT positionnť), il n'y aura pas d'abort de fait. |
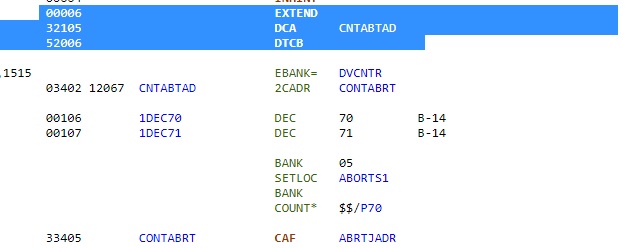 Donc, si le bouton ABORT STAGE a ťtť appuyť, et le bit LETABORT est positionnť, le programme continue ŗ l'ťtiquette P70A. Dedans nous trouvons cette sťquence d'instructions. L'instruction "DCA CNTABTAD" charge le contenu de CNTABTAD, c'est ŗ dire la double adresse de CONTABRT, dans la paire de registres A,L. La double adresse de CONTABRT signifie son adresse dans sa banque de mťmoire, et sa banque de mťmoire. L'instruction DTCB ťchange la paire de registres A,L avec la paire de registres Z,BB. Donc, aprŤs cette instruction, Z contient l'adresse de CONTABRT, et BB sa banque de mťmoire. Z est le compteur de programme, c'est ŗ dire l'adresse de l'instruction courante ŗ exťcuter, et BB est le registre de banque de mťmoire; cela signifie que la prochaine instruction qui est exťcutťe aprŤs DTCB est l'instruction ŗ l'ťtiquette CONTABRT. Mais, comme CONTABRT est dans la mÍme banque de mťmoire, cela aurait ťtť nettement plus simple de remplacer cette sťquence avec la seule instruction "TCF CONTABRT". Une complication inutile qui gaspille de l'espace mťmoire. La sťquence entre DTCB et CONTABRT est sautťe; elle contient deux dťclarations de valeurs (1DEC70 and 1DEC71) qui ne sont pas nťcessaires, car ces valeurs auraient pu Ítre directement utilisťes sans ces dťclarations. |
 Dans cette sťquence, que nous trouvons plus loin dans le programme, l'instruction "CAF ABRTJADR" charge le contenu de ABRTJADR, c'est ŗ dire l'instruction "TCF ABRTJASK", dans l'accumulateur. L'instruction "TS BRUPT" place l'accumulateur dans le registre BRUPT, ce qui signifie que BRUPT contient maintenant l'instruction "TCF ABRTJASK". L'instruction "RESUME" fait un retour d'une interruption; la documentation dit que l'instruction mise dans BRUPT est alors exťcutťe, ce qui signifie que l'instruction "TCF ABRTJASK" est exťcutťe, et cette instruction fait un saut ŗ ABRTJASK. Mais ABRTJASK suit immťdiatement cette sťquence, ce qui signifie que cette sťquence est inutile; une fois de plus un gaspillage d'instructions. |
 Puis suit une sťquence d'instructions jouant avec des variables, faisant manifestement un travail inutile. Nous trouvons cette sťquence d'instructions; cette sťquence est aussi utilisťe dans le programme d'allumage du moteur, "burn baby burn", (je la dťtaillerai quand je parlerai de ce programme), et elle permet d'allumer le moteur de descente. Mais le moteur de descente est dťjŗ couramment allumť, et donc cette sťquence est inutile, et une fois de plus un gaspillage d'instructions. |
 Puis nous trouvons cette sťquence d'instructions. Cette sťquence permet de faire un redťmarrage de l'ordinateur. Mais c'est seulement ŗ faire en cas de situation bloquťe, et l'AGC n'est pas couramment bloquť, et cette sťquence est donc inutile (une fois de plus). |
 Puis nous trouvons une sťquence d'instructions utilisant des macro-instructions, et nous y trouvons ce que nous trouvons aussi dans d'autres programmes: Des lignes avec deux macro-instructions sur la mÍme ligne, ce qui est illťgal, et aurait du Ítre rejetť par le compilateur. |
 Finalement le programme finit par basculer dans le programme de remontťe, mais aprŤs avoir fait plein d'instructions inutiles, et mÍme utilisť des instructions illťgales. |
 Mais le problŤme est que le bouton Abort Stage ne marchera pas dans la descente, ce qui signifie que, s'il n'est pas possible de se poser sur la lune (des cratŤres partout), le module lunaire s'ťcrasera sur la lune lorsque le carburant sera ťpuisť, comme le retour au module de commande est impossible. |
 Certains pensent que, puisqu'il n'ťtait pas possible de faire un abort avec l'AGC, l'AGS (Abort Guidance System), l'ordinateur secondaire, plus simple que l'AGC, pouvait Ítre utilisť ŗ cette fin. Mais l'AGS ťtait seulement prťvu d'Ítre utilisť pour la remontťe, pas pour la descente. Et l'AGS utilise aussi le bouton ABORT STAGE pour la sťparation des ťtages, et il a donc le mÍme problŤme avec le signal parasite dans l'interface d'abort. |
 Et aussi l'AGS n'est pas immťdiatement prÍt ŗ Ítre utiliser aprŤs qu'il ait pris la main, il a besoin de prťparation. Sa documentation dit qu'il a besoin d'au moins 30 minutes de prťparation avant le dťcollage, ce qui exclut de l'utiliser pour faire l'abort lorsque le LEM vole au-dessus de la surface lunaire pour trouver un endroit sŻr oý poser le LEM. |
 Mais le meilleur est que le bouton ABORT STAGE ťtait directement une entrťe du LGC. |
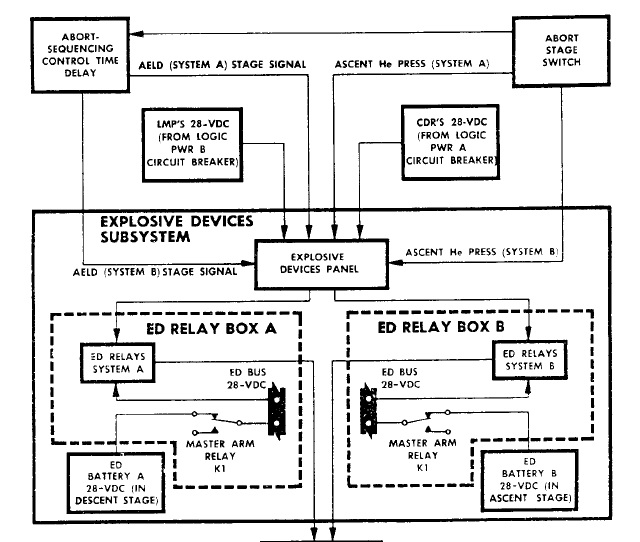 Et le bouton ABORT STAGE dťclenchait directement le systŤme explosif, l'AGC ne pouvait pas l'empÍcher de le faire. Dans les canaux qui permettaient ŗ l'AGC de communiquer avec le LGC, il n'y avait pas de bit qui permettait ŗ l'AGC d'autoriser ou d'empÍcher la sťparation des ťtages. En fait, tout ce que le bit LETABORT faisait ťtait de permettre au programme de descente d'Ítre remplacť par le programme de remontťe. |
Mais, si le bouton ABORT STAGE sťparait les deux ťtages, et l'AGC restait dans le programme de descente parce que la remise ŗ zťro de LETABORT empÍchait l'AGC de passer au programme de remontťe, c'ťtait pire que si l'AGC ťtait passť au programme de remontťe, car le programme de remontťe aurait au moins permis de retourner au module de commande. |
 Alors que, si l'AGC continue de contrŰler le moteur de descente alors qu'en fait celui-ci s'est sťparť du module lunaire, sŻr que le module lunaire va faire la descente sur la lune...mais l'alunissage va Ítre un peu brutal! |
Il est plus qu'ťvident que cette rťsolution du problŤme de l'abort n'ťtait rien d'autre qu'un bon gag de la part des ingťnieurs de la NASA. |
 Il y a une autre mission dans laquelle les ingťnieurs de la NASA ont crťť un problŤme absurde. C'est la mission Apollo 11, dans laquelle la fameuse alarme 1202 s'est produite. |
 Initialement le commutateur radar est sur la position LGC, et, dans cette position, tout se passe bien, l'AGC recevait des impulsions radar normales. |
 Mais Buzz Aldrin aurait mis ce commutateur radar sur la position "SLEW". Le dialogue dit que ce serait ŗ cause d'une indication erronťe de la check list, mais il aurait donnť une autre explication, suggťrant ce que cela aurait ťtť de sa propre initiative. |
 Dans cette position, le rapport de mission dit que deux signaux dťphasťs ŗ haute frťquence auraient crťť des impulsions rapides artificielles, lesquelles n'avaient rien ŗ voir avec l'entrťe radar normale; comme la crťation de ces impulsions rapides ťtait interne, et non externe, cela aurait pu Ítre testť sur terre, et les ingťnieurs n'ont donc pas pu l'ignorer, cela ne pouvait qu'Ítre intentionnel. |
 Le problŤme est que, contrairement aux autres ordinateurs, le processeur de l'AGC comptait lui-mÍme ces impulsions, avec ce qu'ils appellent des "instructions cachťes", c'est ŗ dire des instructions qui s'exťcutaient indťpendamment du programme courant, mais qui empÍchent une instruction du programme courant de s'exťcuter ŗ chaque fois qu'une instruction "cachťe" s'exťcute. |
 Cela signifie que le temps d'exťcution de la t‚che pťriodique de guidage n'ťtait pas dťterminť, il pouvait varier selon la frťquence des impulsions matťrielles que l'AGC devait compter. Quand l'AGC recevait des impulsions normales, la t‚che de guidage pouvait encore finir ŗ temps. |
 Mais, quand l'AGC a commencť de recevoir les impulsions radar trŤs rapides, il a commencť ŗ prendre trop de temps pour compter ces impulsions radar, ce qui signifie que la routine de guidage prenait plus de temps pour finir son travail pťriodique, ŗ cause de la trop grande perturbation des impulsions radar rapides. |
 La consťquence est que la t‚che de guidage, ŗ cause de ces perturbations exagťrťes, ne pouvait plus terminer son travail ŗ temps, et il y a eu une accumulation des t‚ches de guidage en attente d'exťcution, comme elle ťtait automatiquement relancťe toutes les deux secondes. |
 Le rťsultat a ťtť qu'il y a eu un moment oý toutes les ressources disponibles ont ťtť ťpuisťes, et, ŗ ce moment, l'ordinateur a du Ítre redťmarrť, avec la lampe de l'alarme 1202 s'allumant. Il est ťvident qu'avec un ordinateur fonctionnant de maniŤre si erratique, il ne pouvait plus faire son travail normal. |
 Ce qui est ironique est que cette situation aurait parfaitement pu Ítre ťvitťe. En effet, aucun processeur normal ne compte lui-mÍme des impulsions matťrielles. Dans tous les systŤmes normaux (et cela inclut celui de la fusťe Saturn), les impulsions matťrielles sont toujours comptťes par des compteurs ťlectroniques, et un compteur ťlectronique est relativement aisť ŗ faire avec des transistors, comme ce schťma le montre, et mÍme un ťlectronicien dťbutant peut en faire un. |
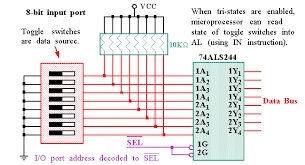 Et le compte d'impulsions du compteur ťlectronique peut Ítre lu par le processeur avec une opťration IO. |
 Et prťcisťment, l'AGC avait une instruction IO, ce qui signifie qu'il aurait parfaitement pu lire le compte d'impulsions depuis un compteur ťlectronique les comptant. |
 Donc, au lieu d'utiliser la procťdure standard, c'est ŗ dire de faire compter les impulsions par un compteur, et lire le compte d'impulsions depuis celui-ci avec une opťration IO, ce qui aurait garanti que le temps d'exťcution de la t‚che de guidage serait restť constant, et qu'il n'aurait pas ťtť accru par les impulsions radar, quelle que soit la frťquence de ces impulsions radar... |
 ...L'AGC comptait lui-mÍme ces impulsions radar (avec des "instructions cachťes", ce qui ťtait une spťcificitť unique de l'AGC), ce qui signifie que, plus les impulsions radar ťtaient rapides, et plus la t‚che de guidage ťtait ralentie, ce qui pouvait avoir un effet critique lorsque ces impulsions radar ťtaient trŤs rapides. |
 Et le problŤme de l'alarme 1202 aurait pu immťdiatement cesser si le sol avait dit aux astronautes de remettre le commutateur radar sur la position "LGC"; mais non, le sol leur a juste dit d'ignorer le problŤme et de continuer, avec la consťquence que l'alarme 1202 (et 1201) pouvait se reproduire. |
En d'autres termes, aussi bien dans la mission Apollo 14 que dans la mission Apollo 11, les ingťnieurs ont crťť une situation insensťe qui n'aurait jamais du se produire, qui ťtait gťrťe de maniŤre aberrante, et jamais les ingťnieurs n'auraient crťť ce type de situation dans des missions normales, ils n'auraient jamais pris de tels risques insensťs. |
 La seule conclusion possible est que les ingťnieurs nous envoient des signes trŤs clairs que les missions n'ťtaient pas rťelles. |
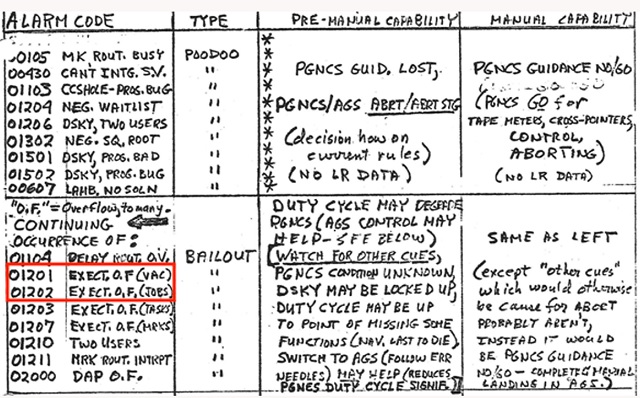
Cette partie parle des intervalles entre les occurences de l'alarme 1202 qui s'est produite dans la descente d'Apollo 11. Lorsque le commutateur radar ťtait sur la sťlection SLEW, une interfťrence entre deux sources dťphasťes de mÍme haute frťquence produisait des impulsions trŤs rapides, qui n'ont rien ŗ voir avec l'entrťe radar normale. Parce que le processeur de l'AGC comptait lui-mÍme ces impulsions rapides, au lieu de les faire compter par un circuit externe, il prenait trop de temps ŗ les compter, et la t‚che pťriodique de guidage ne pouvait plus terminer son travail ŗ temps. La consťquence est que, lorsque les routines de guidage retardťes avaient ťpuisť toutes les ressources disponibles, l'ordinateur ne pouvait plus tourner et devait Ítre redťmarrť; c'est alors que l'alarme 1202 ťtait affichťe (ou cela pouvait aussi Ítre l'alarme 1201 qui ťtait du mÍme type). Comme les impulsions arrivent continuent d'arriver ŗ la mÍme frťquence, aussi longtemps que c'ťtait le mÍme programme qui tournait dans la routine de guidage, les routines de guidage ťtaient retardťes au mÍme rythme, ce qui signifie que l'intervalle entre les alarmes 1202 devrait rester constant, ou presque. C'est ce que nous allons vťrifier. 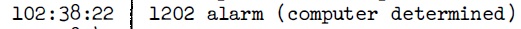 La premiŤre alarme 1202 arrive alors que le programme P63 tourne, et c'est au temps 102:38:22 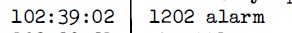 La deuxiŤme alarme 1202 arrive avec le mÍme programme au temps 102:39:02. Il y a 40 secondes de diffťrence avec l'alarme 1202 prťcťdente. 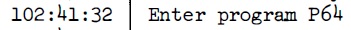 Puis il a un changement de programme au temps 102:41:32, deux minutes et 30 secondes (150 secondes) plus tard, avec le mÍme programme tournant, et sans qu'il y ait production d'alarme 1202, alors que, logiquement, comme il y a eu 40 secondes entre les deux alarmes prťcťdentes, il aurait du y avoir au moins 3 autres alarmes 1202.  Puis il y a une alarme 1201 (mÍme type que 1202) au temps 102:42:18, c'est ŗ dire 46 secondes aprŤs le dťbut du programme P64. 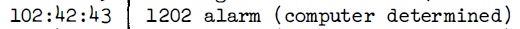 Au temps 102:42:43, il y a une alarme 1202, c'est ŗ dire 25 secondes aprŤs la prťcťdente alarme 1201, alors qu'il y a eu 46 secondes entre le dťbut du programme P64 et la prťcťdente alarme 1201. 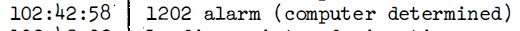 Puis, au temps 102:42:58, il y a une autre alarme 1202, c'est ŗ dire 15 secondes aprŤs la prťcťdente alarme 1202; il y a une claire accťlťration de ces alarmes. 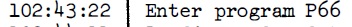 Au temps 102:43:22, il y a un changement de programme ŗ P66, 24 secondes aprŤs la prťcťdente alarme 1202, alors qu'il y a eu seulement 15 secondes entre les deux alarmes 1202 prťcťdentes.  Et finalement, au temps time 102:45:40, il y a la coupure du moteur, sans qu'il se produise une autre alarme 1202. Alors qu'avons nous vu avec les exemples prťcťdents? Que, alors que l'alarme 1202 devrait se produire ŗ des intervalles rťguliers aussi longtemps que le mÍme programme tourne dans la routine pťriodique de guidage, c'est loin d'Ítre le cas; nous observons une irrťgularitť importante. |
 Lorsque l'alarme 1202 se produisait, une procťdure spťciale "BAILOUT" ťtait automatiquement appelťe. Le code de cette procťdure est documentť, j'en donne un lien dans la description de cette vidťo. Bien sŻr, je me suis intťressť ŗ son traitement, et je n'ai pas ťtť dťÁu, car il est rempli de surprises, et une pierre de plus ajoutťe ŗ l'ťdifice du canular lunaire. |
 Cette description est un peu technique, et peut Ítre difficile ŗ suivre pour les non programmeurs, mais je pense que ceux qui ont quelque expťrience de la programmation l'apprťcieront. |
 Accrochez vous bien quand mÍme, car c'est de la haute voltige! |
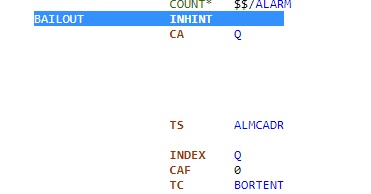 Ceci est le point d'entrťe de la procťdure BAILOUT. Le premiŤre instruction qui est exťcutťe, "INHINT", inhibe toutes les interruptions, ce qui signifie en particulier que l'affichage est gelť, et le clavier ne rťpond pas. |
 L'instruction "CA Q" place le contenu du registre Q dans l'accumulateur, et l'instruction "TS ALMCADR" place le contenu de l'accumulateur dans la variable ALMCADR. Le registre Q contient l'adresse retour de la procťdure BAILOUT; en d'autres termes, ce couple d'instructions place l'adresse retour de Bailout dans la variable ALMCADR. L'AGC n'a pas de pile, ce qui signifie que, ŗ chaque fois qu'une procťdure est appelťe par une autre procťdure, le contenu de Q est remplacť par l'adresse de retour de la nouvelle procťdure. |
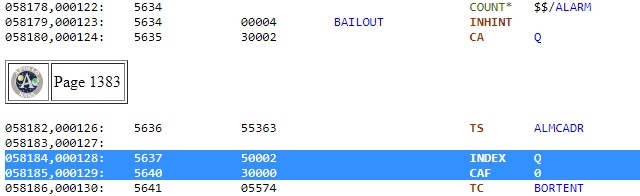 L'instruction INDEX a pour effet que son opťrande est ajoutť ŗ l'opťrande de l'instruction suivante. Le couple d'instructions "INDEX Q", "CAF 0", fait donc que le contenu du registre Q plus zťro est placť dans l'acculumateur; en d'autres termes le contenu de Q est placť dans l'accumulateur. Remarquez que c'ťtait plus simplement fait par une instruction prťcťdente "CA Q", et, de plus, c'est mÍme inutile, car l'accumulateur contenait encore le contenu du registre Q, comme il n'a pas ťtť modifiť entre temps. C'est donc un couple d'instructions qui est complŤtement inutile, et aurait pu Ítre ťvitť. |
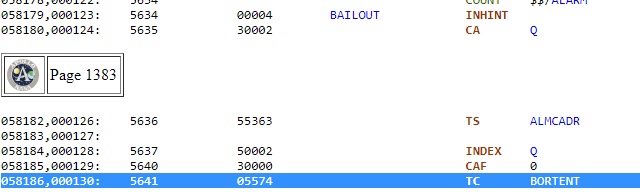 L'instruction "TC BORTENT" appelle la procťdure "BORTENT"; l'adresse de retour, c'est ŗ dire l'adresse de l'instruction qui suit cette instruction, est placťe dans le registre Q. |
 Donc, ŗ prťsent, l'exťcution reprend depuis l'ťtiquette BORTENT. Le premiŤre instruction de cette procťdure, "TS L", place le contenu de l'accumulateur dans le registre L; l'accumulateur contient encore l'adresse retour de la procťdure BAILOUT. |
 L'instruction "CA BBANK" place le contenu de la variable BBANK dans l'accumulateur. Le couple d'instructions "EXTEND" et "ROR SUPERBNK" fait un OU de l'accumulateur (qui contient couramment la variable BBANK) avec une variable I/O SUPERBNK. Pour en faire quoi? |
 L'instruction "TS ALMCADR" place le contenu de l'accumulateur dans la variable "ALMCADR". Rappelez vous que cette variable avait dťjŗ ťtť initialisťe avec une autre valeur (l'adresse de retour de la procťdure BAILOUT), et elle n'a pas ťtť utilisťe entre temps; ce qui signifie que l'initialisation prťcťdente ťtait inutile. |
 L'instruction "CA Q" place le contenu du registre Q dans l'accumulateur, et l'instruction "TS ITEMP1" place le contenu de l'accumulateur dans la variable ITEMP1. Le registre Q contient couramment l'adresse retour de la procťdure "BORTENT", et cela signifie donc que l'adresse retour de BORTENT est placťe dans la variable ITEMP1. |
 L'instruction "CCS FAILREG" place le contenu dťcrťmentť de FAILREG dans l'accumulateur, mais ne modifie pas FAILREG; elle teste le contenu courant de FAILREG, et saute l'instruction suivante plus grand que zťro. L'instruction suivante "TCF CHKFAIL2" est exťcutťe si le contenu courant de FAILREG est plus grand que zťro, et elle saute ŗ l'ťtiquette CHKFAIL2. |
 Les deux instructions suivantes "LXCH FAILREG" et "TCF PROGALARM" sont exťcutťes seulement si le contenu courant de FAILREG ťtait nul. L'instruction "LXCH FAILREG" ťchange le contenu de FAILREG avec le registre L, ce qui signifie que FAILREG n'est pas nul aprŤs cette instruction, comme le registre L avait un contenu non nul avant l'ťchange (il contenait l'adresse retour de BAILOUT). L'instruction "TCF PROGALARM" saute ŗ l'ťtiquette PROGALARM, ce qui signifie que l'instruction suivante n'est pas exťcutťe aprŤs cette instruction. |
 Si nous arrivons sur cette ťtiquette "CHKFAIL2", cela signifie que la variable FAILREG ťtait plus grande que zťro (sinon l'instruction "TCF PROGALARM" l'aurait sautťe). Le mÍme test est fait qu'ŗ l'ťtiquette "CHKFAIL1", avec le mÍme rťsultat. Mais, puisque nous sommes arrivťs ici parce que FAILREG ťtait plus grand que zťro, nťcessairement l'instruction suivante "TCF FAIL3" ne sera pas sautťe, et cette instruction saute ŗ l'ťtiquette FAIL3. |
 Cela signifie aussi que les deux instructions suivantes "LXCH FAILREG" et "TCF MULTEXIT" ne seront jamais exťcutťes, et sont donc totalement inutiles. Et les deux instructions prťcťdentes sont ťgalement inutiles, comme l'instruction suivante a "FAIL3" comme ťtiquette. |
 L'instruction "CA FAILREG" place le contenu de FAILREG dans l'accumulateur. FAILREG est couramment non nul, ce qui signifie que l'accumulateur n'est pas nul aprŤs cette instruction. L'instruction "MASK POSMAX" rťalise un ET de l'accumulateur avec POSMAX; le nom POSMAX laisse suggťrer qu'il contient des bits tous ŗ 1, auquel cas il laisserait l'accumulateur inchangť, donc toujours non nul. |
 L'instruction "CCS A" dťcrťmente l'accumulateur, mais le teste avant qu'il ne soit dťcrťmentť. L'instruction suivante "TCF MULTFAIL" est exťcutťe si l'accumulateur ťtait plus grand que zťro (avant l'instruction CCS), et donc elle devrait logiquement Ítre exťcutťe, elle permet de sauter ŗ l'ťtiquette MULTFAIL. |
 Les deux instructions suivantes "LXCH FAILREG" et "TCF MULTEXIT" sont seulement exťcutťes si l'accumulateur ťtait nul avant l'instruction "CCS", et ne devraient pas logiquement Ítre exťcutťes. L'instruction "LXCH FAILREG" ťchange le contenu de FAILREG avec le registre L. L'instruction "LXCH FAILREG" prťcťdente n'a pas ťtť exťcutťe si nous arrivons ici, car une instruction "TCF PROGALARM" suit l'instruction "LXCH FAILREG" prťcťdente, et PROGALARM est aprŤs cette nouvelle instruction "LXCH FAILREG". Cela signifie que le registre L contient encore l'adresse de retour de BAILOUT, et FAILREG est donc non nul aprŤs cette instruction. |
 L'instruction "CS DSPTAB" place le contenu nťgatif de DSPTAB dans l'accumulateur, l'instruction "MASK OCT40400" fait un ET de l'accumulateur avec une variable, OCT40400, et l'instruction "ADS DSPTAB" ajoute le contenu de DSPTAB ŗ l'accumulateur. Notez que, puisque la variable DSPTAB est utilisťe deux fois dans ces trois instructions, il aurait ťtť possible de le faire avec deux instructions seulement, en n'utilisant DSPTAB qu'une seule fois. |
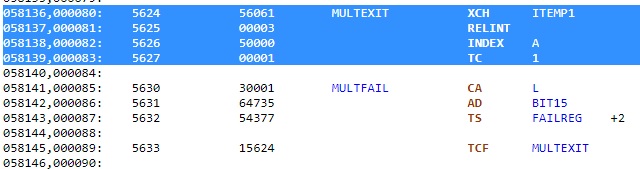 Nous arrivons maintenant ŗ l'ťtiquette "MULTEXIT". L'instruction "XCH ITEMP1" ťchange le contenu de la variable ITEMP1 avec l'accumulateur. Souvenez vous que l'adresse retour de la procťdure BORTENT avait prťcťdemment ťtť placťe dans ITEMP1. Cela signifie donc que l'accumulateur contient maintenant l'adresse retour de BORTENT. L'instruction "RELINT" autorise ŗ nouveau les interruptions qui avaient ťtť inhibťes au dťbut de BAILOUT. L'instruction "INDEX A" a pour effet que l'accumulateur est ajoutť ŗ l'opťrande de l'instruction suivante. Cela signifie que l'instruction suivante "TC 1" appelle l'adresse correspondant au contenu de l'accumulateur plus un, donc l'adresse retour de BORTENT plus un, comme l'accumulateur contient couramment l'adresse retour de BORTENT. Cela signifie que la prochaine instruction qui sera exťcutťe aprŤs cette instruction sera l'instruction qui est juste aprŤs l'instruction qui suit l'appel ŗ BORTENT. Remarquez que cette instruction aurait du Ítre un "TCF" (saut), et non un "TC" (appel de sous-programme) comme il n'y aura pas de retour aprŤs cette instruction. |
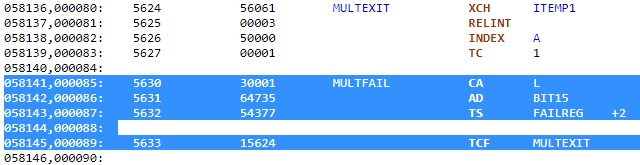 Il peut aussi y avoir un saut ŗ l'ťtiquette MULTFAIL. L'instruction CA L" place le contenu du registre L dans l'accumulateur, l'instruction "AD BIT15" ajoute BIT15 ŗ l'accumulateur; le nom de BIT15 suggŤre qu'il a son bit 15 ŗ 1, et donc l'accumulateur contient maintenant une valeur non nulle; l'instruction "TS FAILREG" place le contenu de l'accumulateur dans FAILREG. Finalement l'instruction "TCF MULTEXIT" fait un saut ŗ l'ťtiquette "MULTEXIT", qui provoque une sortie de BORTENT, alors quelle est l'utilitť de changer ŗ nouveau FAILREG, puisqu'il ne sera plus utilisť dans la procťdure BORTENT? |
 Les deux derniŤres instructions de MULTEXIT appellent l'adresse de l'instruction qui suit l'instruction qui est juste aprŤs l'appel ŗ BORTENT (TC BORTENT). Cela signifie que l'instruction qui suit "TC BORTENT" ne sera jamais exťcutťe. Cette instruction "OCT 40400" n'est mÍme pas une instruction, puisque c'est juste une valeur et non une instruction, et il est donc normal qu'elle ne soit pas exťcutťe. Mais, dans ce cas, pourquoi ne pas juste la supprimer, et faire directement un retour ŗ l'instruction suivant "TC BORTENT", ce qui aurait pu Ítre fait avec le couple d'instructions "INDEX A" et "CAF 0" ŗ la fin de MULTEXIT? Cela aurait ťconomisť une instruction inutile. Et, encore mieux, le couple d'instructions "INDEX A" et "CAF 0" aurait ťtť plus efficacement remplacť par l'unique instruction "RETURN" qui fait un retour ŗ l'adresse contenue dans le registre Q (dans lequel l'adresse retour de BORTENT est placťe quand BORTENT est appelť). Donc encore un gaspillage d'instructions car un couple d'instructions aurait pu Ítre remplacť par une instruction unique. Au total cela fait deux instructions inutiles. Et la premiŤre instruction qui est exťcutťe aprŤs le retour de BORTENT est l'instruction "INHINT", qui inhibe les instructions ŗ nouveau, lesquelles avaient ťtť autorisťes juste avant le retour de BORTENT. Alors, pourquoi autoriser les interruptions si c'est pour les inhiber ŗ nouveau juste aprŤs? |
 Le couple d'instructions "CA TWO" et "ADD Z" ajoute le contenu du compteur de programme (c'est ŗ dire l'adresse de l'instruction suivante, soit l'adresse de "TS BRUPT") ŗ une variable TWO, qui, comme son nom l'indique, contient la valeur 2, et place le rťsultat dans l'accumulateur; autrement dit, c'est l'adresse de "TS BRUPT" plus 2 qui est mise dans l'accumulateur, et cela correspond ŗ l'adresse de l'instruction "TC POSTJUMP", l'instruction qui est deux mots aprŤs "TS BRUPT"; pour conclure, c'est l'adresse de "TC POSTJUMP", juste aprŤs l'instruction "RESUME", qui est mise dans l'accumulateur; l'instruction "TS BRUPT" place l'accumulateur dans le registre BRUPT. L'instruction "RESUME" permet de retourner depuis une interruption, et exťcute d'abord l'instruction qui est placťe dans BRUPT. Mais BRUPT ne contient pas une instruction, mais une adresse, et une adresse ne peut Ítre exťcutťe comme une instruction. Comme il y a un retour depuis une interruption, le traitement s'arrÍte ici, et ce qui a ťtť exťcutť n'a pas de sens. |
 Et cette procťdure ne rťalise en fait rien de significatif, elle est juste lŗ pour le show. |
 Et pourquoi les ingťnieurs se seraient-ils souciťs d'ťcrire un programme qui a du sens pour un ordinateur dont la mťmoire ne fonctionnait mÍme pas? |
 De toute faÁon, cela ne signifie pas que les astronautes ťtaient foutus dans leur descente sur la lune, car ils pouvaient encore sauter en parachute avant que le module lunaire ne s'ťcrase sur la lune. Il y a une croix rouge lunaire trŤs efficace sur la lune, qui est capable de les accueillir, et de prendre soin d'eux quand ils se posent sur la lune. |

