. Dada uma variável aleatória X designa-se por F(x) a aplicaçăo :
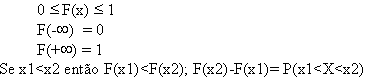
Variável aleatória a uma funçăo que costuma ser representada por X, cujo valor é um número real determinado pelo resultado de uma experięncia aleatória.
As variáveis aleatórias podem ser de dois tipos:
Para uma dada experięncia aleatória podemos estar interessados no estudo de de uma única característica, ou seja numa variável aleatória unidimensional, ou pelo contrário num conjunto de característica, tratando-se assim de uma variável aleatória multidimensional
. Um conceito que nos permite compreender o fenômeno associado ŕ experięncia, descrita pela variável aleatória é o de:
Para as variáveis aleatórias discretas chama-se
distribuiçăo de probabilidade ao conjunto dos pares (xi,pi) em que pi é a
probabilidade de X tomar o valor xi. Neste caso, ![]()
Para as variáveis aleatórias contínuas chama-se
funçăo densidade de probabilidade ŕ funçăo f(x) contínua e positiva, tal
que: 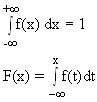
Chama-se, para as variáveis aleatórias contínuas :
Valor
médio, esperança matemática valor esperado ou média, e representa-se por
![]()
E(a)=a
E(a+bX)=a+bE(X)
E(X+Y)=E(X)+E(Y)
Se X e Y
forem independentes E(XY)=E(X).E(Y)
O valor médio é uma medida do centro de uma distribuiçăo. Uma
medida de dispersăo em relaçăo ao valor médio, é-nos dada pela variância,
representada por ![]() 2, e definida por
E[(X-m)2], a
2, e definida por
E[(X-m)2], a ![]() chama-se desvio padrăo.
chama-se desvio padrăo.
Var(X)![]() 0
0
Var(aX+b)=a2Var(X)
Se X e Y forem independentes
Var(X+Y)=Var(X)+Var(Y)
Ŕ variaçăo conjunta de X e Y chama-se Covariância e
designa-se por Cov(X,Y) o valor de E(XY)-E(X)E(Y). Desta definiçăo resulta que o
valor da covariância depende das unidades em que se exprimem as variáveis
aleatórias X e Y. Deste modo introduz-se um parâmetro que caracteriza a
intensidade da ligaçăo entre X e Y, o coeficiente de correlaçăo, designado
por![]() e definido por
e definido por ![]() . Este valor está compreendido entre -1 e 1. Se X e Y săo independentes
entăo
. Este valor está compreendido entre -1 e 1. Se X e Y săo independentes
entăo ![]() =0>.
=0>.
Das propriedades do valor médio e da variância podemos facilmente
deduzir quais os parâmetros da variável aleatória , obtida pela média
de variáveis aleatórias com a mesma distribuiçăo, com parâmetros  , em que o valor médio e a variância săo, respectivamente;
, em que o valor médio e a variância săo, respectivamente;
![]()
Vamos em seguida descrever sumariamente algumas variáveis aleatórias contínuas, nomeadamente com distribuiçăo :
A distribuiçăo normal surgiu no século XVIII ligada ao
estudo de erros de mediçőes repetidas de uma mesma quantidade (replicadas). As
suas propriedades matemáticas foram estudadas por DeMoivre, Laplace e Gauss,
sendo por este fato esta distribuiçăo conhecida por distribuiçăo de Gauss. As
principais razőes da sua importância prendem-se com o fato de muitas variáveis
biométricas serem aproximadamente normais, de mesmo variáveis năo normais
poderem ser transformadas nesta, ou ainda, neste caso a parte central ser razoavelmente
bem aproximada por uma normal.A normal representa-se por N (µ,![]() ) .
) .
f.d.p.=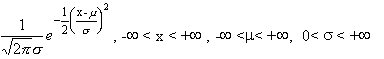
Simetria relativamente a µ, f(µ+a)=f(µ-a)
Unimodal - moda =
µ
Maximizante em µ, ![]()
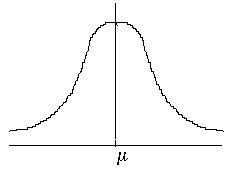
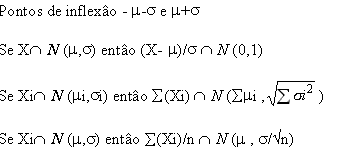
As propriedades anteriores mostram que a soma de Normais ainda é uma normal. Mais ainda o seguinte teorema mostra-nos que a distribuiçăo aproximada da soma de n variáveis aleatórias independentes e identicamente distribuídas, é a de uma normal, segundo certas condiçőes.
Seja {Xn} uma sucessăo de n variáveis aleatórias i.i.d. , com
valor médio µ , e variância ![]() 2(finita). A variável aleatória Sn=
2(finita). A variável aleatória Sn=![]() (Xi) tem distribuiçăo assintóticamente normal, com parâmetros nµ e
(Xi) tem distribuiçăo assintóticamente normal, com parâmetros nµ e ![]()
![]() . Ou seja para um valor de n suficientemente grande, a distribuiçăo de
Sn é N(nµ ,
. Ou seja para um valor de n suficientemente grande, a distribuiçăo de
Sn é N(nµ , ![]()
![]() ), e escreve-se Sn ~ N(nµ ,
), e escreve-se Sn ~ N(nµ ,![]()
![]() ).
).
Donde se obtém que, a média de n variáveis aleatórias é: ![]() (Xi)/n~N(µ,
(Xi)/n~N(µ,![]()
![]() )
)
Esta distribuiçăo é muito usada em inferęncia estatística, sendo um caso particular da funçăo gama. Entre outras utilizaçőes, é de realçar a sua aplicaçăo no estudo da variância de uma populaçăo a partir de uma amostra.
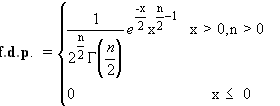
Esta funçăo como, como se pode observar pela f.d.p. fica
perfeitamente especificada pelos graus de liberdade ,n . Representa-se por ![]() .
.
Alguns resultados importantes relativos a esta distribuiçăo, săo:
A soma de funçőes com distribuiçăo qui-quadrado, tem distribuiçăo qui-quadrado com grau de liberdade igual ŕ soma dos graus de liberdade dessas distribuiçőes:
![]()
Se Z tem distribuiçăo normal reduzida, entăo o quadrado de Z tem distribuiçăo qui-quadrado com um grau de liberdade:
![]()
Esta distribuiçăo foi introduzida por William Gosset em 1908, que publicava os seus trabalhos sob o pseudônimo de Student, para năo divulgar ŕ concorręncia da fábrica em que trabalhava, a utilizaçăo dos métodos estatísticos nos processos de fabrico. Tal como a distribuiçăo anterior, esta distribuiçăo tem um papel importante na inferęncia estatística, e fica identificada por um parâmetro, o grau de liberdade. A variável aleatória com a distribuiçăo de Student representa-se por t(n).
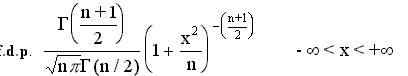
Simétrica
E(t)=0;
Var(t)=n/(n-2) para n>2
unimodal
semelhante ŕ normal reduzida
Se 
Esta distribuiçăo em conjunto com a do Qui-Quadrado e t de
student, forma um conjunto de distribuiçőes teóricas indispensáveis na resoluçăo
de problemas de inferęncia estatística. A distribuiçăo F, encontra um largo campo
de aplicaçăo em problemas relativos ŕ análise de variância. Diz-se que uma
variável aleatória tem distribuiçăo F, e escreve-se X~F(m,n) se a sua funçăo
densidade de probabilidade for definida por:
A expressăo geral do erro aleatório inerente a um valor y resultante de
operaçőes definidas por uma funçăo P(ui) pode ser definido da seguinte forma:
A demonstraçăo deste resultado năo é apresentada uma vez que a teoria
necessária ŕ sua demonstraçăo năo se enquadra nos objetivos desta disciplina.
Mais ainda convém realçar que este resultado é uma simplificaçăo de uma
expressăo matemática mais rigorosa. A sua apresentaçăo corrente na bibliografia
de quimiometria justifica a perda de rigor em funçăo da praticabilidade. Nesta
perspectiva é desculpável o abuso de notaçăo no uso de -s - como interpretador
do erro.
Em seguida apresentam-se testes para validaçăo de um método por
comparaçăo: Dado uma amostra de dimensăo n poderemos afirmar que o seu valor médio µ é
igual a mµ0 ?
Entăo Exemplo: Para investigar um novo método utilizou-se um material padrăo cuja
concentraçăo de Pb é conhecida (0.340 mg). Foram realizadas 15 replicadas pelo
método a testar tendo-se obtido o seguinte resultado: t0.05= -1.761 e t0.95=1.761 como
|tobs|=1.660<1.761 năo se rejeita a hipótese de que a diferença
năo é significativa. O nível de significância foi de 0.1. Será que de duas amostras independentes de dimensăo n1 e
n2 com médias respectivamente Exemplo : Uma amostra é analisada num estudo inter-comparativo para a
determinaçăo de um composto A tendo-se obtido os valores para a média e
variância respectivamente 32.6 e 6.55 com amostras de dimensăo 36. O analista
analisou uma amostra com o seu próprio método tendo obtido para 30 replicadas os
valores : 31.6 para a média e 4.05 para a variância. Pender-se-á concluir que o
método investigado produz resultados iguais ou inferiores aos do estudo
inter-comparativo?
como 1.776 > 1.645 rejeitamos a hipótese H0 de igualdade de valores médios
havendo evidęncia de que que µ1 poderá ser maior que µ2
b) Pequenas amostras
Exemplo : Utilizando o exemplo anterior mas agora considerando que que
n1=11 e n2=13
e que a hipótese de normalidade e homogenidade está verificada.
como t0.95=quantil 0.95 de uma t(22)=1.717 e 1.071<1.717 năo
rejeitamos a hipótese de igualdade de valores médios.
Dados os dois conjuntos de dados, o valor da diferença entre cada par de
observaçőes terá uma distribuiçăo com valor médio zero?
Considere-se para cada par de observaçőes a diferença di =
x1i-x2i . Para testar esta hipótese temos mais uma vez que
fazer uma distinçăo entre pequenas e grandes amostras.
a) Grandes amostras (n>30)
Para grandes amostras pelo teorema do limite central estaremos a
testar a hipótese de . b) Pequenas amostras
Para pequenas amostras o teorema do limite central já năo é
aplicável mas utilizando a hipótese de normalidade de Exemplo : A composiçăo do composto A é analisado em dez amostras por um
método padrăo R, e um método a testar T. Será que os dois métodos produzem
resultados diferentes?
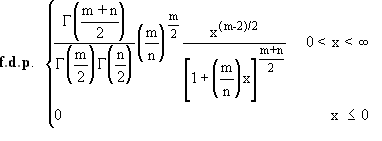
Propriedades e resultados relativos ŕ distribuiçăo F

Apontamentos sobre inferęncia estatística

2.2.- PROPAGAÇĂO DE ERROS ALEATÓRIOS
Em trabalho
experimental, o cálculo de um valor final pode ser resultado da combinaçăo de um
conjunto de valores observados. Este cálculo pode envolver operaçőes como a
soma, quociente ou produto, ou ainda a sua combinaçăo. É de salientar que o
efeito destas operaçőes em erros aleatórios e sistemáticos é completamente
diferente, porque os erros aleatórios de certa forma cancelam-se, enquanto que
os erros sistemáticos, uma vez que apresentam uma tendęncia, reproduzem-se ao
longo destas operaçőes. Supondo que x é o resultado de a+b, onde a e b tęm um
erro sistemático de 1. O valor atribuído a x herda um erro de valor 2. No
entanto se a e b tivessem subjacente um erro de ±1 o erro de x năo seria de ±2 .
Importa pois conhecer a forma como interagem os erros aleatórios e sistemáticos
num conjunto de operaçőes.
![]()

2.3.- PROPAGAÇĂO DE ERROS SISTEMÁTICOS
A propagaçăo
dos erros sistemáticos determina-se de forma análoga aos erros aleatórios, com
ausęncia do sinal de módulo, uma vez que estes erros tęm um sinal determinado. O
valor do erro sistemático de cada membro do cálculo final, é identificado pela
letra ![]()
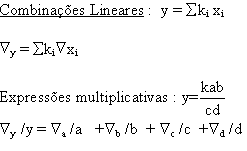
2.4. TESTES PARA COMPARAÇĂO DE MÉTODOS
. Uma das
formas de selecionar um método analítico, é comparando vários métodos de acordo
com as suas características. A substituiçăo de um método por outro faz-se
normalmente porque este último é menos dispendioso, mais rápido ou por outras
características que o tornam mais atrativo. No entanto uma decisăo deste tipo
năo é levada acabo sem um estudo da precisăo e ausęncia de erros sistemáticos. A
forma mais simples de determinar a acurácia de um método, é analisando um
material padrăo ou standard para o qual a concentraçăo do da substância a
analisar é conhecida. A diferença entre o valor obtido pela média de replicadas
e o valor correto dar-nos-á uma indicaçăo da existęncia ou năo de viés. Se a
diferença năo for significativa os desvios podem ser considerados como
resultados de erros aleatórios, caso contrário o erro pode ser usado como um
estimado do erro sistemático. Na ausęncia de material standard a comparaçăo
pode ser estabelecida em relaçăo a um método para o qual é conhecida a ausęncia
de erros sistemáticos. No entanto a precisăo do método nos casos descritos
estará a ser determinada apenas para o material utilizado. Este procedimento năo
será incorreto se a extrapolaçăo năo suscitar ambigüidades. Caso contrário o
teste mais correto decorrerá de várias análises para diferentes produtos.
Avaliaçăo do viés de um método por utilizaçăo de material padrăo ou standard
(identificaçăo de erros sistemáticos)
Quando se analisa uma amostra
standard, por exemplo como as propostas por organizaçőes como a ASTM (American
Society of Testing and Matterials), NBS ( National Bureau of Standards) ou a BCR
(Bureau Communautaire de Reference), por um novo método, há que decidir se o
resultado difere significativamente do correto. O termo significativo em
estatística é estabelecido a partir do conhecimento da funçăo de distribuiçăo da
variável aleatória (estatística de teste) utilizada para comparaçăo dos
resultados. Se a probabilidade de ocorręncia do valor observado for pequena,
isso corresponde ŕ năo aceitaçăo da hipótese estudada, ou seja a de que os
valores comparados năo diferem significativamente. A probabilidade de rejeitar
uma hipótese corresponde ao nível de significância do teste, sendo um valor a,
normalmente igual a 0.1 ou 0.05.
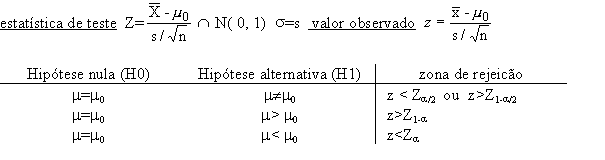
Comparaçăo com um valor conhecido com erro aleatório negligenciável (uma
amostra)
Neste primeiro caso a hipótese em estudo pode ser posta da seguinte
forma :
![]() = média dos n resultados obtidos pelo novo método ; µ0 =
valor correto
= média dos n resultados obtidos pelo novo método ; µ0 =
valor correto
a) Grandes amostras (n>30)
Para grandes amostras pelo teorema do
limite central estaremos a testar a hipótese ![]() de ter uma distribuiçăo Normal com valor médio µ0 e desvio
padrăo
de ter uma distribuiçăo Normal com valor médio µ0 e desvio
padrăo ![]()
![]() sendo “s” um bom estimado de
sendo “s” um bom estimado de ![]() .
.
b) Pequenas amostras
Para pequenas amostras o teorema do limite central
já năo é aplicável mas utilizando a hipótese de normalidade de ![]() é uma normal reduzida, ou seja
é uma normal reduzida, ou seja ![]() tem uma distribuiçăo com valor médio µ igual a µ:0 e desvio
padrăo igual a
tem uma distribuiçăo com valor médio µ igual a µ:0 e desvio
padrăo igual a ![]() .
.

0.380; 0.346; 0.291;
0.278; 0.404; 0.331;0.409; 0.285; 0.361; 0.268; 0.306; 0.243; 0.316; 0.223 ;
0.299.
A média obtida difere significativamente do valor real, existe
evidęncia de erros sistemáticos no método? ![]() = 0.316 ; s=0.056
= 0.316 ; s=0.056
![]()
Comparaçăo com um valor conhecido cujo erro aleatório năo é negligenciável
(duas amostras independentes)
Neste segundo caso estamos a comparar o valor
obtido pelo método a testar com um valor conhecido para o mesmo produto que
estamos a analisar mas por um outro método certificado. A questăo será posta,
neste caso, nos seguintes termos:
![]() e e variâncias s1 e s2 provęm de uma mesma
populaçăo com valor médio µ , ou seja os seus valores médios µ1 e
µ2 săo iguais a µ?
e e variâncias s1 e s2 provęm de uma mesma
populaçăo com valor médio µ , ou seja os seus valores médios µ1 e
µ2 săo iguais a µ?
a) Grandes amostras (n>30)
Para grandes amostras pelo teorema do limite central estaremos a
testar a hipótese de ![]() 1 e
1 e ![]() 2 terem uma distribuiçăo normal com valor médio
µ1 e µ2 iguais a µ e desvio padrăo respectivamente
2 terem uma distribuiçăo normal com valor médio
µ1 e µ2 iguais a µ e desvio padrăo respectivamente ![]() 1/
1/![]() 1 e
1 e ![]() 2/
2/![]() 2 sendo “s1 e s2 ” estimadores dos respectivos desvios
padrőes. Neste caso podemos considerar a diferença das duas normais, que ainda
será normal com valor médio µ-µ=0 e variância
s12/n1+
s22/n2.
2 sendo “s1 e s2 ” estimadores dos respectivos desvios
padrőes. Neste caso podemos considerar a diferença das duas normais, que ainda
será normal com valor médio µ-µ=0 e variância
s12/n1+
s22/n2.




Comparaçăo de dois métodos para a mesma amostra (amostras
emparelhadas)
Outro caso em estudo refere-se ao estudo de n amostra de
diferentes concentraçőes, ou năo, por dois métodos. No primeiro caso, o teste
que desenvolveremos só será aplicável se os erros năo forem proporcionais ŕs
concentraçőes dos produtos e, em caso de erros sistemáticos eles sejam
constantes. A formulaçăo da comparaçăo dos dois métodos pode ser posta da
seguinte forma:
![]() ter uma distribuiçăo normal com valor médio µD=0 e desvio
padrăo
ter uma distribuiçăo normal com valor médio µD=0 e desvio
padrăo ![]() /
/![]() sendo “s” um bom estimado de
sendo “s” um bom estimado de ![]()

![]() podemos recorrer ŕ estatística
podemos recorrer ŕ estatística ![]() que tem uma distribuiçăo t(n-1) porque Z=
que tem uma distribuiçăo t(n-1) porque Z=![]() /(
/(![]() /
/![]() ) tem distribuiçăo de uma normal reduzida ou seja
) tem distribuiçăo de uma normal reduzida ou seja ![]() tem uma distribuiçăo com valor médio igual a 0 e variância a
tem uma distribuiçăo com valor médio igual a 0 e variância a ![]() 2/n e assim, sendo a distribuiçăo de (n-1)
S2/
2/n e assim, sendo a distribuiçăo de (n-1)
S2/![]() 2 é um
2 é um ![]() .
.

